



优快云话题挑战赛第2期
参赛话题:大数据技术分享
Hive概述
Hive是一个基于Hadoop的数据仓库软件,可以使用类似SQL的语法读写、查询和管理大数据集。Hive最初只是Facebook内部的一个项目,使得拥有SQL技能但缺乏Java编程技能的分析师能够查询存储HDFS上的海量数据。如今,Hive已经成为一个成功的Apache项目,许多公司将它用于通用的、可扩展的数据处理平台。
Hive主要提供以下特性:
通过SQL语言访问数据以及常用的数据仓库操作如ETL(extract/transform/load)、报表和数据分析;
将数据结构施加于多种数据格式(如CSV/TSV文本文件、Parquet和ORC)的机制,数据可以存储在HDFS或HBase中;
利用MapReduce、Tez或Spark作为查询的执行引擎,本书主要介绍最常用的基于MapReduce执行引擎。
Hive与传统数据库
Hive在很大程度上与传统关系型数据库非常类似,然而由于Hive是基于HDFS和MapReduce做数据存储和处理,这深刻影响着Hive所支持的特性。随着Hive的发展,这些架构上的限制已经逐渐解除,使得Hive与传统数据库更趋类似。
读时模式和写时模式
模式(shcema)指的是数据库的表结构,即数据表中包含的列以及相应的数据类型。在传统数据库中,数据在导入表的时候就会验证模式,只有在模式符合时才能成功导入。这种在数据写入时验证模式的方式称为写时模式(schema on write)。Hive采取的是另一种方式,即在数据导入时并不验证模式,而只在查询时才验证,称为读时模式(schema on read)。
这两种方式各有利弊。读时模式在数据导入时,不需要将输入数据进行读取、解析以及序列化成数据库的内部存储格式。整个数据导入过程只是将数据文件复制或移动到指定位置。同时,读时模型也更灵活,对于同一个数据文件,可以施加多种不同的模式,用于不同的分析任务。Hive中的外部表即支持这一特性,后续章节会具体介绍。而写时模式的数据查询效率较高,因为数据库可以在一些列上做索引,并在数据存储格式上做优化。然而,写时模式的缺点是,数据导入的时间较长。
修改、事务和索引
修改、事务和索引是传统数据库的标配。直到近几年,Hive才开始支持这些特性,早先的Hive版本都不支持这些特性。这都是由于Hive基于HDFS和MapReduce做数据存储和处理,HDFS文件并不支持在文件任意位置做修改,修改数据表中的一条记录就必须将整个数据表变换为一张新的数据表。多数数据仓库应用在数据导入数据表后,并不需要修改数据,而大多为扫描数据表的全部或一部分。
Hive很早之前就支持使用INSERT INTO语句将新的数据文件插入到数据表中。然而直到0.14版本才开始支持使用INSERT INTO TABLE … VALIES语句插入小批量数据,同时也开始支持UPDATE和DELETE语句。HDFS不支持在文件任意位置做修改,因此插入、修改和删除等操作的结果会保存在小的增量文件(delta file)中。后台的MapReduce作业会定期启动,将增量文件与基本表数据文件合并。这些插入、修改和删除操作都在事务(transaction)中完成。因此,对同一张数据表的不同查询能够看到一致的数据表。Hive同时也支持事务锁。
索引可以加速数据查询。例如,查询SELECT * FROM t WHERE x = a可以利用列x上的索引,直接定位到相关的表数据文件位置,而不需要进行全表扫描。Hive中目前支持两种索引类型:紧凑型(compact)和位图型(bitmap)。紧凑型索引存储每个值的HDFS文件块编号。位图型索引用位集合(bitset)存储数值对应的行号。
Hive元数据存储
Hive元数据存储(metastore)用于在关系型数据库(如MySQL或Oracle)中存储Hive表和分区的元数据,并通过服务API将这些信息提供给客户端。
默认情况下,Hive本身包含了一个内置的Derby数据库作为元数据存储。然而,该内置Derby数据库仅支持一个连接,意味着每次只有一个Hive会话可以访问元数据存储。这显然是生产环境中不能接受的。因此,多数情况下,会安装独立的关系型数据库(如MySQL或Oracle)。
Hive的安装
Hive安装前需确保Hadoop安装已完成
安装Hive相关组件
使用yum install命令在线安装Hive核心组件,包括
HiveServer2服务:hive-server2.noarch;
元数据存储服务:hive-metastore.noarch;
Hive客户端:hive。
sudo yum install hive-server2.noarch
sudo yum install hive-metastore.noarch
sudo yum install hive
配置基于MySQL的Hive元数据存储
以root用户登录MySQL。
mysql -u root -p
Enter password: Sh123456!
使用CREATE DATABASES语句创建Hive元数据存储的数据库metastore,并使用USE语句选择该数据库。
CREATE DATABASE metastore;
USE metastore;
使用SOURCE语句运行创建Hive元数据存储的相关数据表的SQL脚本/usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-2.1.1.mysql.sql。
SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-2.1.1.mysql.sql;
使用GRANT语句赋予hive用户操作数据库metastore的所有权限,这里将hive用户的密码设为123456。
GRANT ALL ON metastore.* TO’hive’@'%‘IDENTIFIED BY’123456’;
使用SHOW DATABASES和SHOW GRANTS验证数据库的创建和权限的赋予。
SHOW DATABASES;
±-------------------+
| Database |
±-------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
±-------------------+
SHOW GRANTS FOR ‘hive’@‘%’;
±----------------------------------------------------------------------------------------------------+
| Grants for hive@% |
±----------------------------------------------------------------------------------------------------+
| GRANT USAGE ON . TO ‘hive’@‘%’ IDENTIFIED BY PASSWORD ‘6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9’ |
| GRANT ALL PRIVILEGES ONmetastore. TO ‘hive’@’%’ |
±----------------------------------------------------------------------------------------------------+
使用quit命令退出MySQL。
quit;
配置MySQL JDBC驱动器
使用ln命令将MySQL JDBC驱动器文件mysql-connector-java.jar链接到文件夹/usr/lib/hive/lib/。
ln -s /usr/share/java/mysql-connector-java.jar /usr/lib/hive/lib/mysql-connector-java.jar
配置Hive
打开Hive配置文件/etc/hive/conf/hive-site.xml,加入的配置项包括:
javax.jdo.option.ConnectionURL:Hive元数据存储的连接地址;
javax.jdo.option.ConnectionDriverName:Hive元数据存储的驱动器名称,这里设为MySQL JDBC驱动器;
javax.jdo.option.ConnectionUserName:Hive元数据存储的用户名;
javax.jdo.option.ConnectionPassword:Hive元数据存储的密码。
该文件配置部分(即标签内)看起来如下所示。
vim /etc/hive/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
<description>the URL of the MySQL database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
创建Hive数据文件夹
Hive表中的数据通常存储在HDFS中的/user/hive/warehouse文件夹中。
以hdfs用户使用hdfs dfs -mkdir命令创建文件夹/user/hive/warehouse以及hdfs dfs -chown命令将文件夹所有权移交给hive用户。
以hive用户使用hdfs dfs -chmod命令将文件夹权限改为任何用户都可以读写。
sudo -u hdfs hdfs dfs -mkdir -p /user/hive/warehouse
sudo -u hdfs hdfs dfs -chown -R hive /user/hive
sudo -u hive hdfs dfs -chmod 1777 /user/hive/warehouse
启动Hive相关组件
使用service start命令启动Hive相关组件,包括
HiveServer2服务:hive-server2;
元数据存储服务:hive-metastore。
sudo service hive-metastore start
sudo service hive-server2 start
Starting Hive Metastore (hive-metastore): [ OK ]
Started Hive Server2 (hive-server2): [ OK ]
验证Hive正常运行
使用beeline命令执行显示所有数据表的命令。
beeline -u ‘jdbc:hive2://localhost:10000/’ -e ‘select 1;’
Connecting to jdbc:hive2://localhost:10000/
Connected to: Apache Hive (version 2.1.1-cdh6.1.0)
Driver: Hive JDBC (version 2.1.1-cdh6.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
INFO : Compiling command(queryId=hive_20190122120255_44a12068-2a35-4b4b-b019-b233d0076773): select 1
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20190122120255_44a12068-2a35-4b4b-b019-b233d0076773); Time taken: 4.416 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20190122120255_44a12068-2a35-4b4b-b019-b233d0076773): select 1
INFO : Completed executing command(queryId=hive_20190122120255_44a12068-2a35-4b4b-b019-b233d0076773); Time taken: 0.003 seconds
INFO : OK
±-----+
| _c0 |
±-----+
| 1 |
±-----+
1 row selected (5.329 seconds)
Beeline version 2.1.1-cdh6.1.0 by Apache Hive
Hive的运行
Hive中所有的查询都可以通过Beeline命令行客户端提交到HiveServer2服务,HiveServer2服务会与元数据存储服务交互,检查权限并将查询映射到具体的HDFS文件,最终将查询在Hive数据库中执行。整个过程如下图所示。
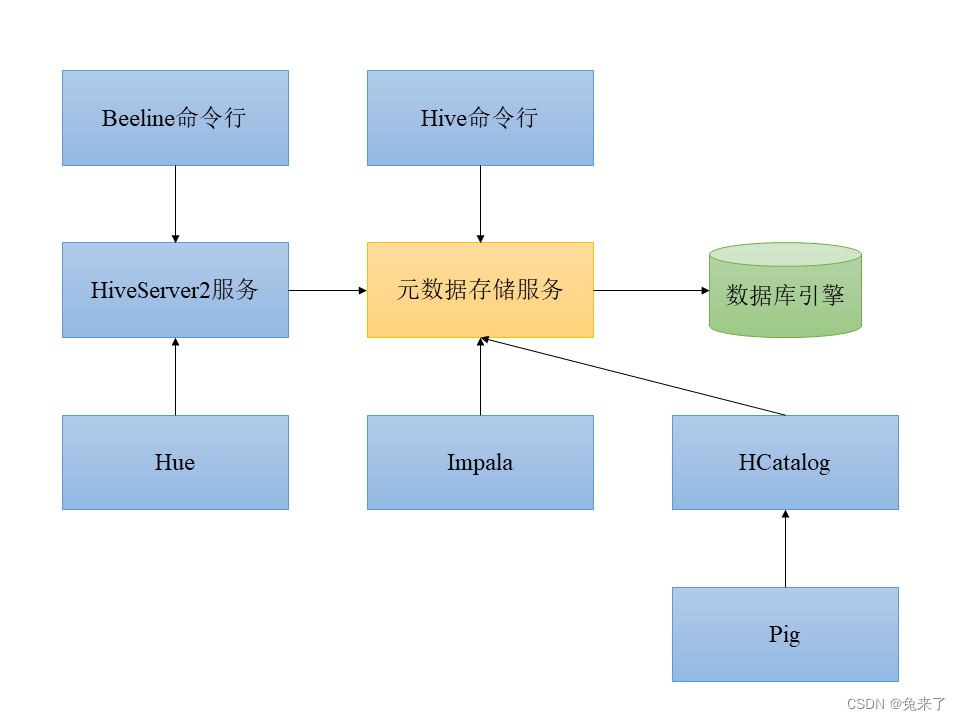
Hive命令行从Hive 1.0后就已经被淘汰,转而使用Beeline作为命令行工具。Beeline命令行和Hue与HiveServer2服务连接,将命令传递给元数据存储服务,并在Hive数据库中执行。而Imapala和Pig则直接连接元数据存储服务,而不通过HiveServer2服务。
Beeline基本命令
使用beeline命令进入Beeline命令行。
beeline
Beeline version 2.1.1-cdh6.1.0 by Apache Hive
Hive命令行从Hive 1.0后就已经被淘汰,转而使用Beeline作为命令行工具。Beeline命令行和Hue与HiveServer2服务连接,将命令传递给元数据存储服务,并在Hive数据库中执行。而Imapala和Pig则直接连接元数据存储服务,而不通过HiveServer2服务。
Beeline基本命令
使用beeline命令进入Beeline命令行。
beeline
Beeline version 2.1.1-cdh6.1.0 by Apache Hive
set hivevar:foo = bar;
set hivevar:foo;
±-----------------±-+
| set |
±-----------------±-+
| hivevar:foo=bar |
±-----------------±-+
使用${hivevar:<变量名>}引用变量,Hive会使用变量值替换掉变量引用。
select ‘${hivevar:foo}’;
±-----±-+
| _c0 |
±-----±-+
| bar |
±-----±-+
使用dfs <dfs子命令>命令执行HDFS中的dfs命令,以分号结尾。
dfs -ls;
±------------±-+
| DFS Output |
±------------±-+
±------------±-+
使用!quit命令退出Beeline。
!quit
Closing: 0: jdbc:hive2://localhost:10000/
Beeline运行选项
启动Beeline时指定一系列运行选项,可通过以下形式指定运行选项。
beeline -<选项1> <值1> -<选项2> <值2> …
常用的Beeline运行选项包括:
选项-u表示HiveServer2的JDBC连接URL,形如jdbc:hive2://<主机名>:<端口号>/<数据库名>;
选项-n表示登陆用户名;
选项-p表示登陆密码;
选项-e表示执行的查询语句,可以指定多次;
选项-f表示执行的脚本文件。
使用beeline -u <JDBC连接URL> -n <登陆用户名> -p <登陆密码>命令启动Beeline,避免每次启动都需要手动输入相关信息。
beeline -u ‘jdbc:hive2://localhost:10000’ -n root -p 123456
Beeline version 2.1.1-cdh6.1.0 by Apache Hive
!quit
使用beeline -e <查询语句>命令以非交互的方式直接执行查询语句。
beeline -u ‘jdbc:hive2://localhost:10000’ -n root -p 123456 -e ‘select 1;’ -e ‘select 2;’
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 2.1.1-cdh6.1.0)
Driver: Hive JDBC (version 2.1.1-cdh6.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
[…]
INFO : OK
±-----±-+
| _c0 |
±-----±-+
| 1 |
±-----±-+
1 row selected (0.347 seconds)
[…]
±-----±-+
| _c0 |
±-----±-+
| 2 |
±-----±-+
1 row selected (0.087 seconds)
Beeline version 1.1.0-cdh5.15.1 by Apache Hive
Closing: 0: jdbc:hive2://localhost:10000
使用beeline -f <脚本文件>命令以非交互的方式直接执行脚本文件。
echo ‘select 1; select 2;’ > script.sql
beeline -u ‘jdbc:hive2://localhost:10000’ -n root -p 123456 -f script.sql
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 2.1.1-cdh6.1.0)
Driver: Hive JDBC (version 2.1.1-cdh6.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> select 1; select 2;
[…]
±-----±-+
| _c0 |
±-----±-+
| 1 |
±-----±-+
1 row selected (0.334 seconds)
[…]
±-----±-+
| _c0 |
±-----±-+
| 2 |
±-----±-+
1 row selected (0.082 seconds)
0: jdbc:hive2://localhost:10000>
0: jdbc:hive2://localhost:10000>
Closing: 0: jdbc:hive2://localhost:10000

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









