







(2023-12-12-21:00)
这篇文章
提出了Text2KGBench,用于评估LLMs在本体(ontology)指导下从文本语料中提取事实的能力。
主要介绍的还是基准,第2节介绍了基准的任务,第3节描述了基准的创建过程,第4节定义了评价指标,第5节给出了基准和评价结果。在第6节的相关工作之后,本文在第7节给出了一些结束语和下一步的工作。
但是其中好像已经把咱们想做的做了,就是从大模型中提取知识图谱

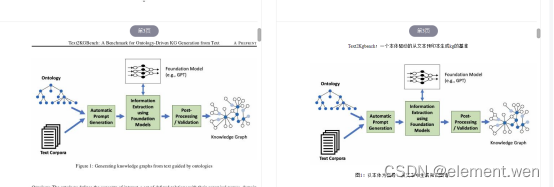
前提知识:
本体是实体存在形式的描述,往往表示为一组概念定义和概念之间的层级关系,如:苹果的图片,苹果,apple这三个都是符号。但是现实中实实在在的苹果这个事物,就是亚里士多德口中的"实体",巴门尼德口中的"存在",和本体论中所说的"本体"。
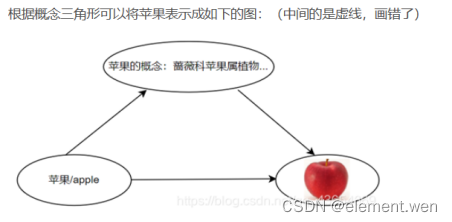
该篇论文贡献:
1.提出了一个新的基准Text2KGBench,通过本体和指令引导关系抽取,扩展了关系抽取。
2.提供了两个数据集:( a )维基数据- TekGen,有10个本体和13474个句子对齐到三元组;( b ) DBpedia
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









