







 实体消歧涉及判断词的不同含义,如“苹果”可以指水果或公司。实体统一确定多个表达是否指向同一实体,常用方法包括编辑距离、规则匹配和有监督学习。指代消歧则解决文本中代词的指代问题,可以通过最近名字法或基于监督的分类器实现。
实体消歧涉及判断词的不同含义,如“苹果”可以指水果或公司。实体统一确定多个表达是否指向同一实体,常用方法包括编辑距离、规则匹配和有监督学习。指代消歧则解决文本中代词的指代问题,可以通过最近名字法或基于监督的分类器实现。
实体消歧
实体消歧主要是指:一个词可能含有多个意思,不同的上下文表达的含义可能也不一样
例如:今天苹果发布了新手机
对于“苹果”我们怎么判断?
对于实体消歧来说我们得有一个实体库,库中包含每个实体,以及它所包含的意思,例如:“苹果”在实体库中有两个含义:
苹果:水果的一种
苹果:美国的一家高科技公司
那么对于:今天苹果发布了新手机。
这样一句话我们提取“苹果”前后大约30个词左右和并利用两个含义形成关于TF-IDF的词向量,然后再将“苹果”的两个含义也计算出相应的词向量,最后做余弦相似度计算判断这句话与那个向量比较接近,选择最高相似度的含义。
实体统一
实体统一是指判断多个实体是不是属于一个实体,其实这种情况也比较常见,比如大家在填写地址的时候,有很多种写法但指的是同一个地址,还有很多人都有多个手机,我们能不能通过一些访问信息来判断是不是属于同一个人而使用不同手机操作的呢?这些都是实体统一要做的工作。
所以给定两个实体,字符串,我们来判断是否属于同一个实体,字符串
第一种方法是:计算两个实体(字符串)之间的相似度,一般使用编辑距离即可,设定阈值,判断是否属于一个实体。
第二种方法:基于规则
举个例子:
1、百度有限公司
2、百度科技有限公司
我们通过人工的设计一些库,或者说是一些词典,这些库包含相同实体的特点:
词典1:公司、有限公司、分公司…
词典2:北京,天津,上海…
词典3:科技,技术…
如果实体中的词出现在库中将其删掉
1、百度有限公司——作为原型,删掉词库中的词后为:百度
2、百度科技有限公司 —删掉词库中的词后为:百度 判定相同实体
以上两种方法精度不高,人力成本比较高
第三种基于有监督的学习方法:
还是上面的例子:
1、百度有限公司
2、百度科技有限公司
我们可以将1和2利用特征工程将其转换为特征向量:
比如考虑词性,前后单词,词位置等等
然后
1:输入到一个训练好的分类模型去判断两个实体是否相似。
2:利用余弦相似度技术相似程度,然后再输入到LR做二分类的计算
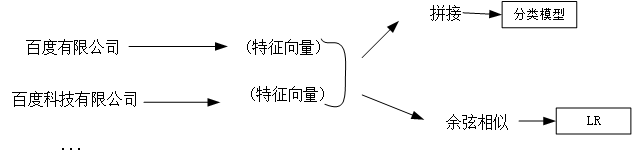
第四种方法:基于图的实体统一
其实每个实体都不是独立的,他们与其他实体是包含一定的联系,如下图所以我们在做实体统一的时候我们考虑到了这种实体关系,也就是根据这种图来做。
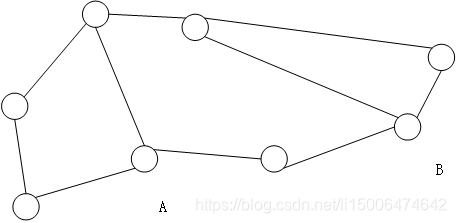
假如我们判断A和B是否是同一个人我们在做特征向量时不仅加入他的个人信息,还可以加入这种关系:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









