







文末有福利!
智算中心建设通过领先的体系架构设计,以算力基建化为主体、以算法基建化为引领、以服务智件化为依托,以设施绿色化为支撑,从基建、硬件、软件、算法、服务等全环节开展关键技术落地与应用。
一、体系架构
(一)总体架构
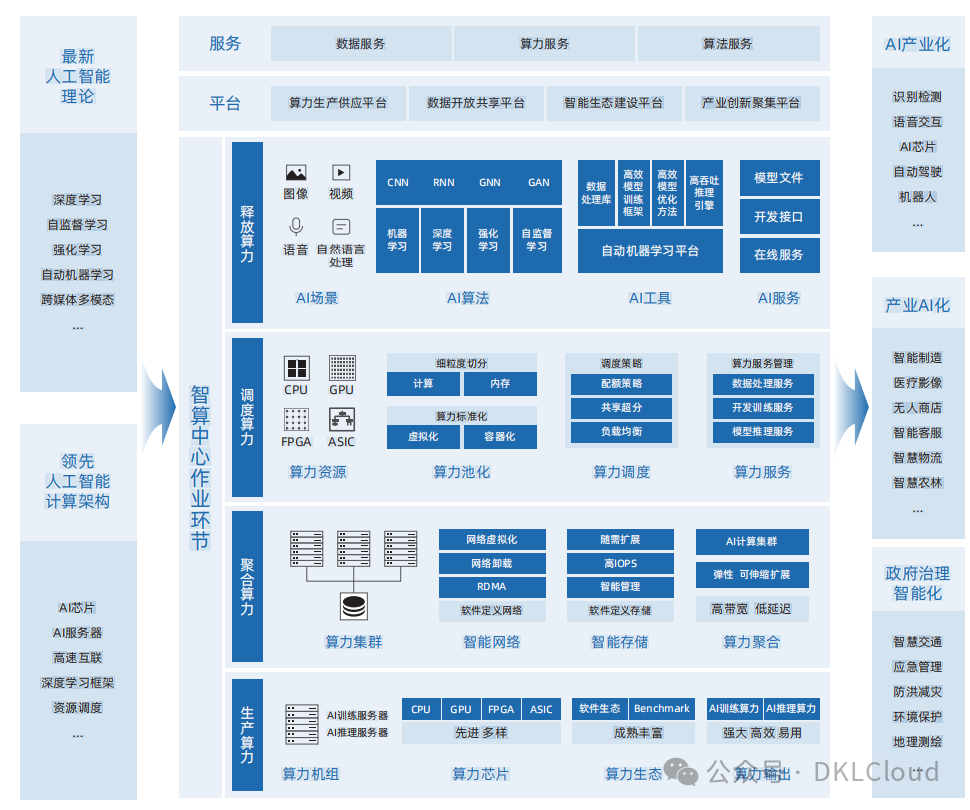
图8 智算中心总体架构
智能算力中心建设白皮书,重点围绕基础、支撑、功能和目标四大部分,创新性地提出了智算中心总体架构。
其中,基础部分是支撑智算中心建设与应用的先进人工智能理论和计算架构;支撑部分围绕智算中心算力生产、聚合、调度、释放的作业逻辑展开;功能部分提供算力生产供应、数据开放共享、智能生态建设和产业创新聚集四大平台,以及数据、算力和算法三大服务;整体目标是促进AI产业化、产业AI化及政府治理智能化。
(二)技术演进
智算中心的发展基于最新人工智能理论和领先的人工智能计算架构,算力技术与算法模型是其中的关键核心技术,算力技术以AI芯片、AI服务器、AI集群为载体,而当前的算法模型发展趋势以AI大模型为代表。
在此基础上,通过智算中心操作系统作为智算中心的“神经中枢”对算力资源池进行高效管理和智能调度,使智算中心更好地对外提供算力、数据和算法等服务,支撑各类智慧应用场景落地。而软件生态则是智算中心“好用、用好”的关键支撑。
1.AI芯片
基于AI芯片的加速计算是当前AI计算的主流模式。AI芯片通过和AI算法的协同设计来满足AI计算对算力的超高需求。当前主流的AI加速计算主要是采用CPU系统搭载GPU、FPGA、ASIC等异构加速芯片。
AI计算加速芯片发端于GPU芯片,GPU芯片中原本为图形计算设计的大量算术逻辑单元(ALU)可对以张量计算为主的深度学习计算提供很好的加速效果。随着GPU芯片在AI计算加速中的应用逐步深入,GPU芯片本身也根据AI的计算特点,进行了针对性的创新设计,如张量计算单元、TF32/BF16数值精度、Transformer引擎(Transformer Engine)等。
近年来,国产AI加速芯片厂商持续发力,在该领域取得了快速进展,相关产品陆续发布,覆盖了AI推理和AI训练需求,其中既有基于通用GPU架构的芯片,也有基于ASIC架构的芯片,另外也出现了类脑架构芯片,总体上呈现出多元化的发展趋势。但是,当前国产AI芯片在产品性能和软件生态等方面与国际领先水平还存在差距,亟待进一步完善加强。总体而言,国产AI芯片正在努力从“可用”走向“好用”。
2.AI服务器
AI服务器是智算中心的算力机组。当前AI服务器主要采用CPU+AI加速芯片的异构架构,通过集成多颗AI加速芯片实现超高计算性能。
为满足各领域场景和复杂的AI模型的计算需求,AI服务器对计算芯片间互联、扩展性有极高要求。AI服务器内基于特定协议进行多加速器间高速互联通信已成为高端AI训练服务器的标准架构。
目前业界以NVLink和OAM两种高速互联架构为主,其中NVLink是NVIDIA开发并推出的一种私有通信协议,其采用点对点结构、串列传输,可以达到数百GB/s的P2P互联带宽,极大地提升了模型并行训练的效率和性能。
OAM是国际开放计算组织OCP定义的一种开放的、用于跨AI加速器间的高速通信互联协议,卡间互联聚合带宽可高达896GB/s。
浪潮信息基于开放OAM架构研发的AI服务器NF5498,率先完成与国际和国内多家AI芯片产品的开发适配,并已在多个智算中心实现大规模落地部署。
3.AI集群
**大模型参数量和训练数据复杂性快速增长,对智算系统提出大规模算力扩展需求。**通过充分考虑大模型分布式训练对于计算、网络和存储的需求特点,可以设计构建高性能可扩展、高速互联、存算平衡的AI集群来满足尖端的AI计算需求。
**AI集群采用模块化方法构建,可以实现大规模的算力扩展。**AI集群的基本算力单元是AI服务器。数十台AI服务器可以组成单个POD计算模组,POD内部通过多块支持RDMA技术的高速网卡连接。在此基础上以POD计算模组为单位实现横向扩展,规模可多达数千节点以上,从而实现更高性能的AI集群。
**AI集群的构建主要采用低延迟、高带宽的网络互连。**为了满足大模型训练常用的数据并行、模型并行、流水线并行等混合并行策略的通信需求,需要为芯片间和节点间提供低延迟、高带宽的互联。另外,还要针对大模型的并行训练算法通信模式做出相应的组网拓扑上的优化,比如对于深度学习常用的全局梯度归约通信操作,可以使用全局环状网络设计,配置多块高速网卡,实现跨AI服务器节点的AI芯片间RDMA互联,消除混合并行算法的计算瓶颈。
**AI集群的构建需要配置面向AI优化的高速存储。**通过配置高性能、高扩展、多层级的智能存储,为各种数据访问需求提供优化性能。智能存储具备随需扩展功能,实现高IOPS处理能力,支持RDMA技术,同时实现高聚合带宽。

4.AI大模型
**超大规模智能模型,简称大模型,是近年兴起的一种新的人工智能计算范式。**和传统AI模型相比,大模型的训练使用了更多的数据,具有更好的泛化性,可以应用到更广泛的下游任务中。按照应用场景划分,AI大模型主要包括语言大模型、视觉大模型和多模态大模型等。
**自然语言处理是首个应用大模型的领域,BERT是大模型的早期代表。**随着大模型在自然语言的理解和生成领域成功应用,推动了语言大模型向更大的模型参数规模和更大训练数据规模的方向发展。当前,语言大模型的单体模型参数已经达到千亿级别,训练数据集规模也达到了TB级别,训练所需计算资源超过1000PetaFlop/s-day(PD)。业界典型的自然语言大模型有GPT-4、源、悟道和文心等。自然语言大模型已经广泛应用于个人知识管理、舆情检测、商业报告生成、金融反欺诈、智能客服、虚拟数字人等场景,同时也出现了一系列的创新应用场景,如剧本杀、反网络诈骗、公文写作等。
在语言大模型大获成功之后,相关技术和方法也被引入计算机视觉领域,通过构建更大的预训练模型,使其可以适用于目标检测、语义分割、异常检测等广泛的视觉任务。
在算法架构上,视觉大模型采用以Transformer架构为主体的神经网络架构和自监督的训练方法以及十亿级的无标注图片数据进行训练。当前业界已经出现了越来越多的通用视觉大模型和面向特定领域的视觉大模型。视觉大模型也已广泛应用于自动驾驶、智能安防、医学影像等领域。
随着大模型技术在语言、视觉等多个领域的应用,融合多个模态的多模态大模型也逐渐成为了业界关注的重点。基于多模态大模型的以文生图,文生视频技术也迅速发展,代表性模型有DALLE-2、Stable Diffusion 3 和Sora等。由于多模态大模型的快速发展,AI内容生成(AI Generated Content,AIGC)已成为下一个AI发展的重点领域。
5.智算OS
智算OS,即智算中心操作系统,是以智算服务为对象,对智算中心基础设施资源池进行高效管理和智能调度的产品方案,可以使智算中心更好地对外提供算力、数据、算法、智件等服
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









