



使用 Kiro 构建智能会议助手:从想法到实现的完整实践
在日常工作中,会议记录一直是个耗时且容易遗漏重点的任务。本次使用 Kiro IDE 构建智能会议助手的完整经历,从需求分析到代码实现,整个过程高效且充满惊喜。
一、Kiro IDE 使用体验
Kiro 是一款 AI 驱动的开发工具,但它给我的感觉更像是一位经验丰富的技术伙伴。与传统 IDE 不同,Kiro 不仅能理解你的代码,还能理解你的意图。
支持的大模型
Kiro 支持多种主流大语言模型,让开发者可以根据需求灵活选择:
主流模型支持:
- Claude 系列(Anthropic):Claude 3.5 Sonnet、Claude 3 Opus - 擅长代码理解和复杂推理
- GPT 系列(OpenAI):GPT-4、GPT-4 Turbo、GPT-3.5 - 通用能力强,响应速度快
- Gemini 系列(Google):Gemini Pro、Gemini Ultra - 多模态能力出色
- 开源模型:支持通过 Ollama 运行本地模型,如 Llama、Mistral 等
模型切换:
- 可在设置中随时切换模型
- 支持为不同任务配置不同模型
- 支持自定义 API 端点
核心功能体验
1. 自然语言交互
我只需要用自然语言描述需求:“构建一个会议助理,先使用 qwen3-asr-flash 做语音识别,然后使用 qwen3-max 做会议记录总结。界面为 Web 界面,界面要求简洁,支持上传本地音频文件。”
Kiro 立即理解了我的需求,并开始构建完整的应用框架。
2. 智能代码生成
Kiro 不是简单地生成代码模板,而是:
- 自动选择合适的技术栈(Gradio + DashScope)
- 设计合理的函数结构
- 添加完善的错误处理
- 生成配套的文档和依赖文件
3. 迭代优化能力
当我提出"添加能增加用户体验的功能,界面要求布局合理、高级、去 AI 化"时,Kiro 不仅添加了多语言支持、关键词提取、记录导出等功能,还重新设计了整个界面布局,使用自定义 CSS 打造专业商务风格。
4. 上下文理解
Kiro 能够记住之前的对话内容,理解项目的整体架构。在优化过程中,它知道要在现有代码基础上改进,而不是重新开始。
Kiro 的特色功能
1. Spec 规范化开发
Spec 功能是 Kiro 的独特之处,它提供了一种结构化的开发方式:
- 需求文档(requirements.md):明确功能需求和验收标准
- 设计文档(design.md):定义技术方案和实现细节
- 任务分解(tasks.md):将大功能拆解为可执行的小任务
- 增量开发:支持复杂功能的迭代式开发
2. Agent Hooks 自动化
Hooks 功能让开发流程自动化:
- 文件保存时自动运行测试
- 代码提交前自动格式化
- 文档更新时自动同步翻译
- 支持自定义触发条件和执行动作
3. Steering 上下文引导
Steering 功能让 Kiro 理解项目规范:
- 定义团队编码规范
- 配置项目特定的最佳实践
- 添加领域知识和业务规则
- 支持条件性加载和手动引用
4. MCP 协议集成
支持 Model Context Protocol,可以:
- 连接外部数据源和工具
- 扩展 Kiro 的能力边界
- 集成企业内部系统
- 自定义工具链
5. 多模态能力
- 支持图片拖拽到对话中进行分析
- 可以理解设计稿并生成代码
- 支持图表、架构图的解读
- 能够处理截图中的错误信息
6. 代码诊断
- 实时显示编译错误和警告
- 集成 ESLint、TypeScript 等工具
- 自动修复常见问题
- 提供优化建议
让我印象深刻的点
- 效率提升:原本需要几小时的开发工作,在 Kiro 的协助下 15 分钟就完成了
- 代码质量:生成的代码结构清晰,注释完善,符合最佳实践
- 全栈思维:不仅关注功能实现,还考虑了用户体验、文档、部署等方面
- 学习价值:通过观察 Kiro 的实现方式,我学到了很多新的技巧
- 可控性强:通过 Spec、Steering 等功能,可以精确控制 AI 的行为
- 扩展性好:MCP 协议让 Kiro 可以连接任何外部系统
二、项目简介
项目背景
在企业环境中,会议记录是一项重要但繁琐的工作。传统方式需要专人记录,容易遗漏关键信息,且整理耗时。我们需要一个能够:
- 自动将会议音频转为文字
- 智能提取会议要点
- 生成结构化的会议总结
- 支持多种导出格式
技术选型
语音识别:阿里云百炼 qwen3-asr-flash
- 支持多语言识别
- 识别速度快,准确率高
- API 调用简单
文本分析:阿里云百炼 qwen-max
- 强大的文本理解能力
- 支持复杂的总结任务
- 可定制化提示词
Web 框架:Gradio
- 快速构建 Web 界面
- 组件丰富,易于定制
- 支持文件上传和下载
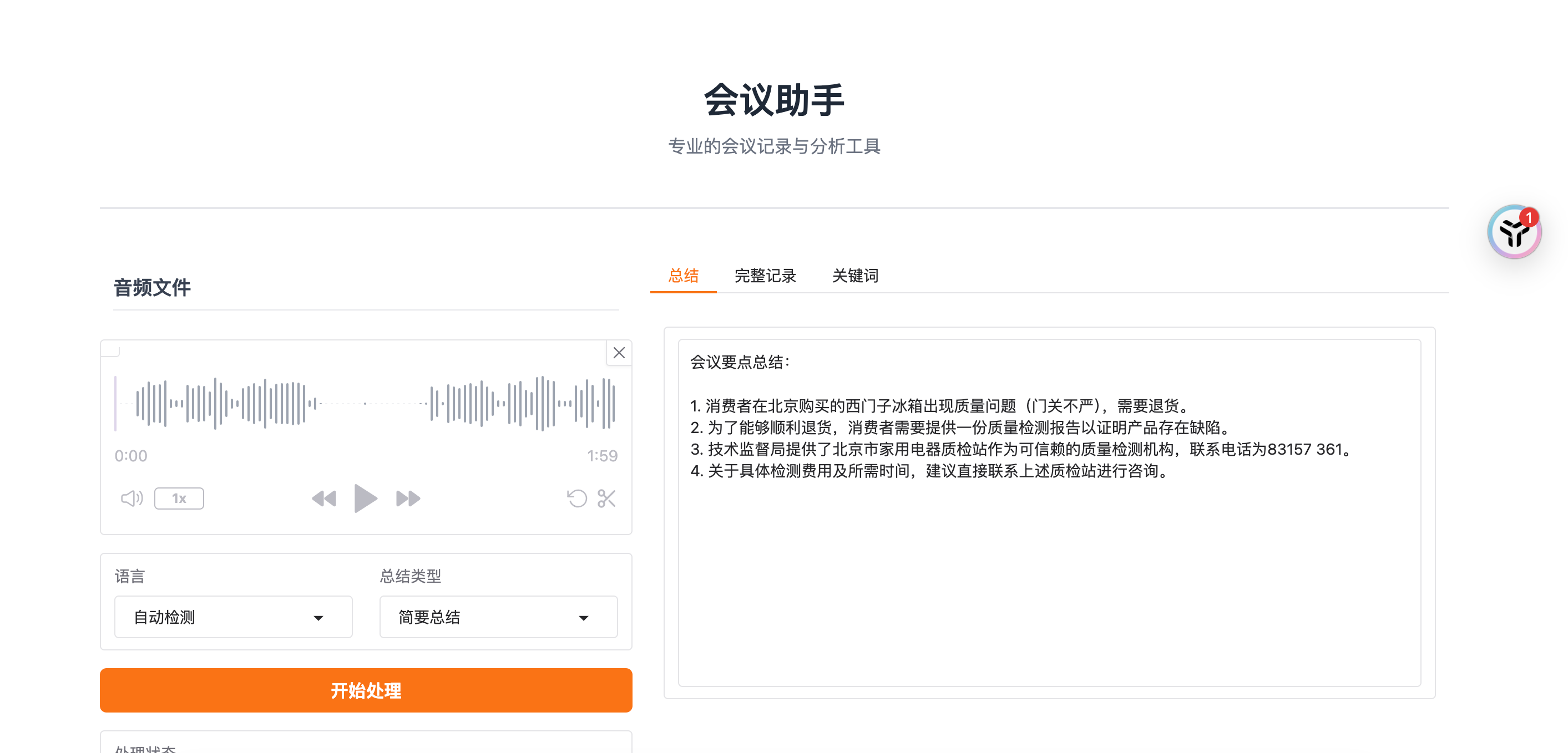
核心功能
- 多语言语音识别:支持中英日韩等多种语言,可自动检测
- 智能总结:提供标准、简要、详细、行动清单四种总结模式
- 关键词提取:自动识别会议核心主题
- 记录管理:支持 JSON 和 Markdown 两种格式导出
- 专业界面:商务风格设计,操作流程清晰
三、构建过程与技术细节
第一阶段:基础功能实现
1. 语音识别模块
使用 DashScope 的多模态对话 API 进行语音识别:
def transcribe_audio(audio_file, language="auto"):
"""使用qwen3-asr-flash进行语音识别"""
audio_path = f"file://{os.path.abspath(audio_file)}"
messages = [
{"role": "system", "content": [{"text": ""}]},
{"role": "user", "content": [{"audio": audio_path}]}
]
asr_options = {"enable_itn": True}
if language != "auto":
asr_options["language"] = language
response = dashscope.MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-asr-flash",
messages=messages,
result_format="message",
asr_options=asr_options
)
return response.output.choices[0].message.content[0]["text"]
关键技术点:
- 使用
file://协议处理本地文件路径 enable_itn开启逆文本规范化,将数字、日期等转为标准格式- 支持语言参数配置,提升识别准确率
2. 会议总结模块
设计了四种总结模式,通过不同的提示词实现:
prompts = {
"standard": "请提供专业的会议总结,包括:\n1. 会议主题\n2. 核心议题\n3. 关键决策\n4. 待办事项\n5. 后续跟进",
"brief": "请用简洁的方式总结会议要点,突出最重要的3-5个关键信息",
"detailed": "请提供详细的会议记录,包括:\n1. 会议背景\n2. 讨论过程\n3. 各方观点\n4. 决策依据\n5. 行动计划\n6. 时间节点",
"action": "请专注于提取会议中的行动项,包括:\n1. 具体任务\n2. 责任人\n3. 截止时间\n4. 优先级"
}
这种设计让用户可以根据不同场景选择合适的总结方式。
第二阶段:功能增强
1. 关键词提取
通过专门的提示词让模型扮演关键词提取专家:
def extract_keywords(transcript):
"""提取关键词"""
messages = [
{
"role": "system",
"content": "你是关键词提取专家。请从文本中提取5-10个最重要的关键词,用逗号分隔。"
},
{
"role": "user",
"content": transcript
}
]
response = dashscope.Generation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-max",
messages=messages,
result_format="message"
)
return response.output.choices[0].message.content
2. 记录导出功能
实现了两种导出格式:
- JSON 格式:保存完整数据,便于程序处理
- Markdown 格式:生成专业文档,便于分享
def export_to_markdown(transcript, summary, keywords, meeting_title):
"""导出为Markdown格式"""
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
title = meeting_title or f"会议记录_{datetime.now().strftime('%Y%m%d')}"
markdown_content = f"""# {title}
**时间**: {timestamp}
## 关键词
{keywords}
---
## 会议总结
{summary}
---
## 完整记录
{transcript}
---
*本记录由会议助手自动生成*
"""
filepath = HISTORY_DIR / f"{title.replace(' ', '_')}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"
with open(filepath, 'w', encoding='utf-8') as f:
f.write(markdown_content)
return str(filepath)
第三阶段:界面优化
1. 布局设计
采用左右分栏布局:
- 左侧:音频上传、参数配置、处理按钮
- 右侧:标签页展示不同维度的结果
with gr.Row():
# 左侧:输入区域
with gr.Column(scale=2):
audio_input = gr.Audio(...)
language_select = gr.Dropdown(...)
summary_type = gr.Dropdown(...)
process_btn = gr.Button(...)
# 右侧:输出区域
with gr.Column(scale=3):
with gr.Tabs():
with gr.Tab("总结"):
summary_output = gr.Textbox(...)
with gr.Tab("完整记录"):
transcript_output = gr.Textbox(...)
with gr.Tab("关键词"):
keywords_output = gr.Textbox(...)
2. 样式定制
使用自定义 CSS 打造专业商务风格:
custom_css = """
.header {
text-align: center;
padding: 2rem 0;
border-bottom: 2px solid #e5e7eb;
margin-bottom: 2rem;
}
.header h1 {
font-size: 2rem;
font-weight: 600;
color: #1f2937;
}
.section-title {
font-size: 1.1rem;
font-weight: 600;
color: #374151;
border-bottom: 1px solid #e5e7eb;
}
"""
技术难点与解决方案
1. 文件路径处理
问题:Gradio 上传的文件需要转换为 DashScope API 可识别的格式
解决:使用 file:// 协议 + 绝对路径
audio_path = f"file://{os.path.abspath(audio_file)}"
2. 异步处理
问题:语音识别和文本分析都需要时间,如何提供良好的用户体验
解决:
- 实时状态反馈
- 显示处理进度
- 分步展示结果
3. 错误处理
在每个关键函数中添加完善的异常处理:
try:
# 核心逻辑
response = dashscope.MultiModalConversation.call(...)
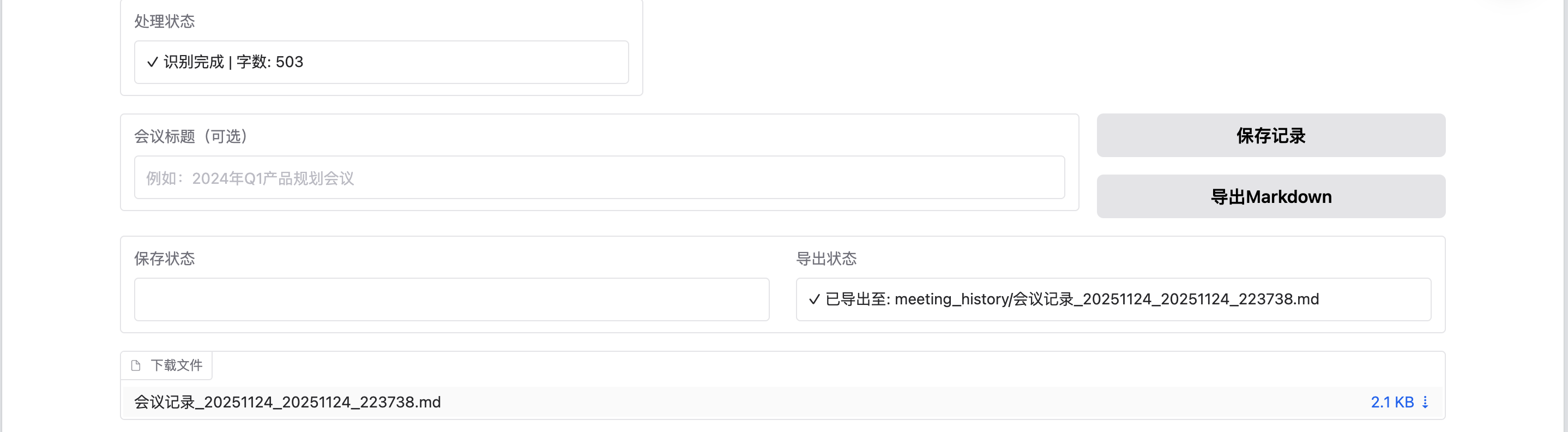
if response.status_code == 200:
return transcript, f"✓ 识别完成 | 字数: {word_count}"
else:
return None, f"识别失败: {response.message}"
except Exception as e:
return None, f"错误: {str(e)}"
四、核心代码展示
完整的处理流程
def process_meeting(audio_file, language, summary_type):
"""处理完整流程:识别 -> 总结 -> 关键词提取"""
# 第一步:语音识别
transcript, status = transcribe_audio(audio_file, language)
if transcript is None:
return status, "", "", ""
# 第二步:生成总结
summary = generate_summary(transcript, summary_type)
# 第三步:提取关键词
keywords = extract_keywords(transcript)
return status, transcript, summary, keywords
界面构建
with gr.Blocks(css=custom_css, title="会议助手") as demo:
# 头部
with gr.Row(elem_classes="header"):
gr.HTML("""
<div>
<h1>会议助手</h1>
<p>专业的会议记录与分析工具</p>
</div>
""")
with gr.Row():
# 左侧:输入区域
with gr.Column(scale=2):
gr.HTML('<div class="section-title">音频文件</div>')
audio_input = gr.Audio(
label="",
type="filepath",
sources=["upload"],
show_label=False
)
with gr.Row():
language_select = gr.Dropdown(
choices=[
("自动检测", "auto"),
("中文", "zh"),
("英文", "en"),
("日语", "ja"),
("韩语", "ko")
],
value="auto",
label="语言"
)
summary_type = gr.Dropdown(
choices=[
("标准总结", "standard"),
("简要总结", "brief"),
("详细记录", "detailed"),
("行动清单", "action")
],
value="standard",
label="总结类型"
)
process_btn = gr.Button("开始处理", variant="primary", size="lg")
status_output = gr.Textbox(label="处理状态", interactive=False)
# 右侧:输出区域
with gr.Column(scale=3):
with gr.Tabs():
with gr.Tab("总结"):
summary_output = gr.Textbox(
label="",
lines=15,
show_label=False,
placeholder="会议总结将在这里显示..."
)
with gr.Tab("完整记录"):
transcript_output = gr.Textbox(
label="",
lines=15,
show_label=False,
placeholder="完整的语音识别文本将在这里显示..."
)
with gr.Tab("关键词"):
keywords_output = gr.Textbox(
label="",
lines=15,
show_label=False,
placeholder="关键词将在这里显示..."
)
# 底部:操作区域
with gr.Row():
with gr.Column(scale=3):
meeting_title_input = gr.Textbox(
label="会议标题(可选)",
placeholder="例如:2024年Q1产品规划会议"
)
with gr.Column(scale=1):
save_btn = gr.Button("保存记录", size="lg")
export_btn = gr.Button("导出Markdown", size="lg")
with gr.Row():
save_status = gr.Textbox(label="保存状态", interactive=False)
export_status = gr.Textbox(label="导出状态", interactive=False)
# 事件绑定
process_btn.click(
fn=process_meeting,
inputs=[audio_input, language_select, summary_type],
outputs=[status_output, transcript_output, summary_output, keywords_output]
)
save_btn.click(
fn=save_meeting_record,
inputs=[transcript_output, summary_output, keywords_output, meeting_title_input],
outputs=[save_status]
)
export_btn.click(
fn=export_to_markdown,
inputs=[transcript_output, summary_output, keywords_output, meeting_title_input],
outputs=[gr.File(label="下载文件"), export_status]
)
记录保存功能
def save_meeting_record(transcript, summary, keywords, meeting_title):
"""保存会议记录为JSON格式"""
if not transcript:
return "没有可保存的内容"
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"meeting_{timestamp}.json"
record = {
"title": meeting_title or f"会议记录_{timestamp}",
"timestamp": datetime.now().isoformat(),
"transcript": transcript,
"summary": summary,
"keywords": keywords
}
filepath = HISTORY_DIR / filename
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(record, f, ensure_ascii=False, indent=2)
return f"✓ 已保存至: {filepath}"
五、使用效果与总结
实际效果
- 识别准确率:对于清晰的会议录音,识别准确率可达 95% 以上
- 总结质量:能够准确提取会议要点,结构化呈现关键信息
- 处理速度:一小时的会议录音,处理时间约 2-3 分钟
- 用户体验:界面简洁专业,操作流程清晰
适用场景
- 企业内部会议记录
- 客户访谈整理
- 培训课程总结
- 研讨会记录
- 电话会议记录
项目收获
技术层面:
- 掌握了多模态 AI 模型的应用
- 学会了 Gradio 的高级定制技巧
- 理解了提示词工程的重要性
- 熟悉了 DashScope API 的使用
工具层面:
- Kiro IDE 大幅提升了开发效率
- AI 辅助编程不是替代,而是增强
- 自然语言交互让开发更加直观
- Spec 和 Steering 功能让开发更可控
产品层面:
- 用户体验设计的重要性
- 功能完整性与易用性的平衡
- 专业化界面的价值
未来优化方向
- 实时转写:支持会议进行中的实时语音转文字
- 多人识别:区分不同发言人
- 智能问答:基于会议内容的问答系统
- 多语言翻译:跨语言会议的实时翻译
- 会议分析:统计发言时长、参与度等指标
结语
这次使用 Kiro IDE 构建智能会议助手的经历,让我深刻体会到 AI 辅助开发的强大之处。Kiro 不仅是一个代码生成工具,更像是一位懂你的技术伙伴,能够理解需求、提供建议、快速实现。
对于开发者来说,Kiro 让我们可以把更多精力放在产品设计和业务逻辑上,而不是陷入繁琐的代码细节。这种开发方式的转变,或许就是未来软件工程的方向。
如果你也想尝试 AI 辅助开发,不妨从一个小项目开始,相信你会有不一样的收获。
相关资源
Kiro 相关:
技术文档:
项目信息:
- 项目地址:https://gitcode.com/umeikou/meeting_assit/
- 技术交流:欢迎在评论区讨论

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









