







必应是一个搜素引擎,它有许多漂亮的图片,比如: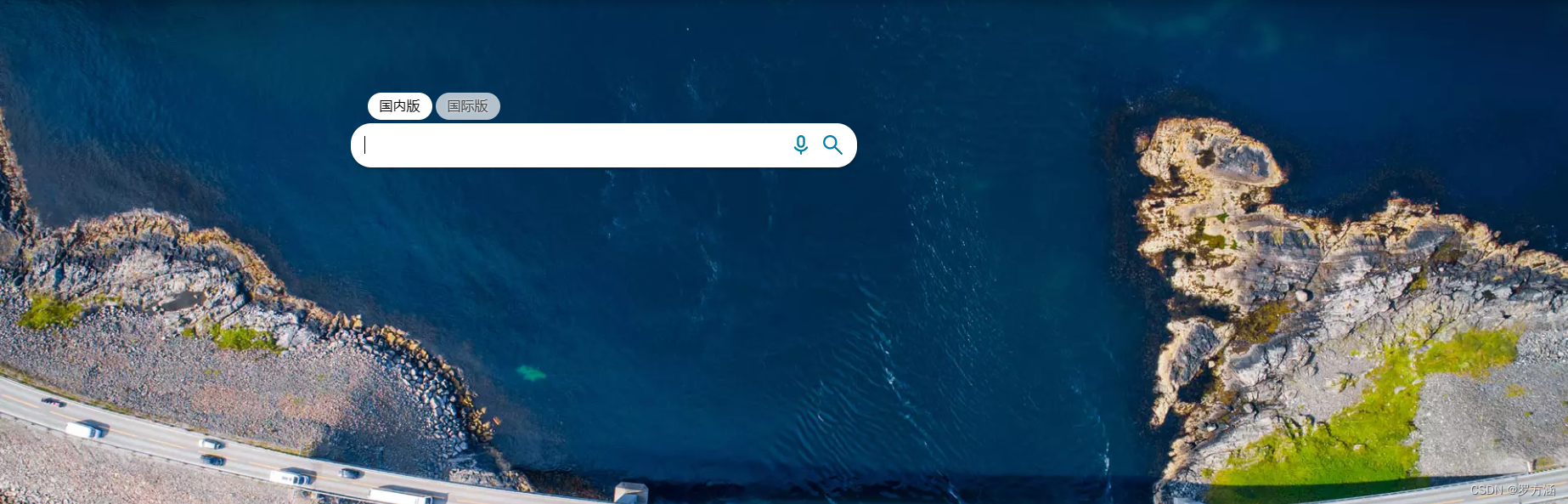
或者
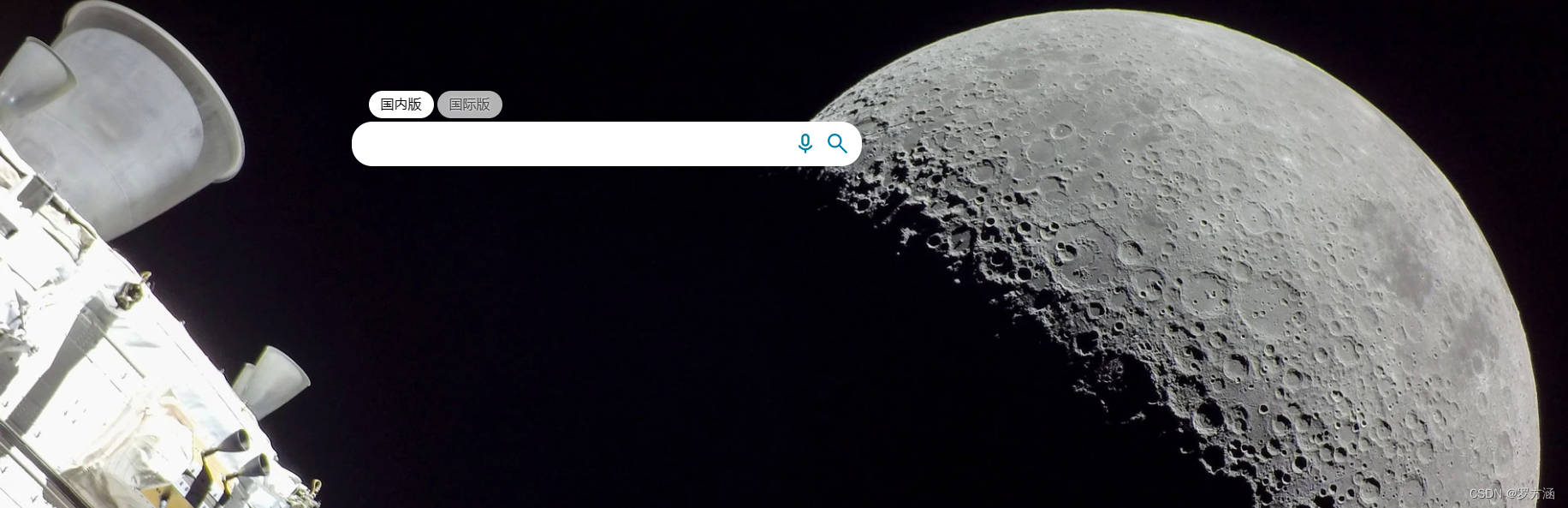
现在我们要将它们爬取下来(记得下载requests库):
import requests
BING_URL = "https://cn.bing.com"
API_URL = BING_URL + "/HPImageArchive.aspx?format=js&idx=0&n=8"
def get_image_list():
reponse = requests.get(API_URL)
json_data = reponse.json()
return json_data["images"]
def get_images(image_list):
images = []
for image_data in image_list:
image_url = BING_URL + image_data["url"]
response = requests.get(image_url)
image_content = response.content
image = {
"content": image_content,
"date": image_data["enddate"]
}
images.append(image)
return images
def save_images(images):
image_files = []
for image in images:
image_path = "%s.jpg" % image["date"]
with open(image_path, "wb") as f:
f.write(image["content"])
image_files.append(image_path)
return image_files
def download_bing_images():
image_list = get_image_list()
images = get_images(image_list)
return save_images(images)
print(download_bing_images())
记得点赞哦!


















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









