




 本文描述了一个在嵌入式项目中,通过对比使用OPENMP和TBB进行图像滤波操作的多线程加速效果,发现两者与基础多线程性能接近,且代码编写相对简单。实验结果表明数据独立性可能影响性能,强调了数据独立性的优化重要性。
本文描述了一个在嵌入式项目中,通过对比使用OPENMP和TBB进行图像滤波操作的多线程加速效果,发现两者与基础多线程性能接近,且代码编写相对简单。实验结果表明数据独立性可能影响性能,强调了数据独立性的优化重要性。
背景:在某个嵌入式上的图像处理项目功能开发告一段落,进入性能优化阶段。尝试从多线程上对图像处理过程进行加速。经过初步调研后,可以从OPENMP,TBB这两块进行加速,当前项目中有些算法已采用多线程加速,这次主要是对比以上两个加速模块与多线程加速效果的对比。现在PC上实验,然后再移植相关库。
环境准备:WIN11 ,VS2022 ,Debug 64
1、编译OPENCV。
经测试,编译过程是否选择TBB,MP相关选项对加载对应库和使用不影响。
2、安装TBB。(https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)
VS配置之打开相关模块。
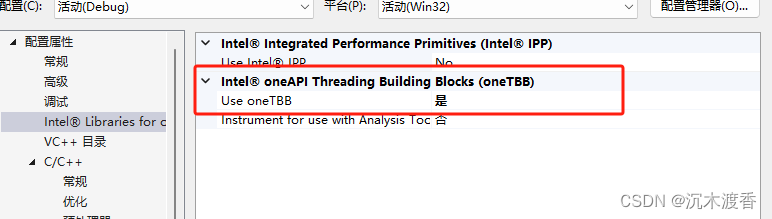
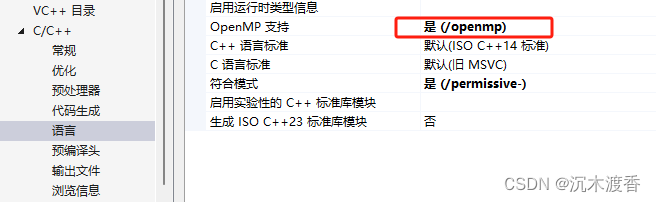
对比过程:实验对比的对象包括:
1、基础FOR循环。
2、多线程。
3、原数据相同的TBB。
4、原数据独立的TBB。
5、原数据相同的OPENMP;
6、原数据独立的OPENMP;
测试数据为960*600的图像,测试内容为对该图进行大尺寸滤波操作。
测试代码:
#include <fstream>
#include <iostream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <omp.h>
#include <future>
#include <thread>
#include <tbb/parallel_for.h>
#include <tbb/blocked_range.h>
int main()
{
const static int iCnt = 50;//循环次数
Mat imori = imread("ori.png");
cvtColor(imori, imori, COLOR_BGR2GRAY);
Mat imoriMt, imoriMP, imoriTbb, imoriAMP[iCnt], imoriATBB[iCnt];
imori.copyTo(imoriMt);
imori.copyTo(imoriMP);
imori.copyTo(imoriTbb);
for (size_t i = 0; i < iCnt; i++)
{
imori.copyTo(imoriAMP[i]);
imori.copyTo(imoriATBB[i]);
}
Mat imRslt[iCnt], imRsltMt[iCnt], imRsltMP[iCnt], imRsltAMP[iCnt],imRsltTbb[iCnt], imRsltATBB[iCnt];
std::vector<std::future<void>> vFutures(iCnt);
double start1 = omp_get_wtime();
{
for (int i = 0; i < iCnt; i++)
{
Mat kealMN = Mat::ones(25, 25, CV_32F);
filter2D(imori, imRslt[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101);
}
}
double end1 = omp_get_wtime();
cout << " cv Normal Time = " << (end1 - start1) << endl;
double startMt = omp_get_wtime();
int i = 0;
for (auto iter = vFutures.begin(); iter != vFutures.end(); iter++, i++)
*iter = std::async([](cv::Mat* imRslt, Mat imori, int i) {Mat kealMN = Mat::ones(33, 33, CV_32F); filter2D(imori, imRslt[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101); }, imRsltMt, imoriMt, i);
for (auto iter = vFutures.begin(); iter != vFutures.end(); iter++)
iter->get();
double endMt = omp_get_wtime();
cout << " cv MThread Time = " << (endMt - startMt) << endl;
double startMP = omp_get_wtime();
#pragma omp parallel num_threads(iCnt)
{
#pragma omp for
for (int i = 0; i < iCnt; i++)
{
Mat kealMN = Mat::ones(33, 33, CV_32F);
filter2D(imoriMP, imRsltMP[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101);
}
}
double endMP = omp_get_wtime();
cout << " cv MP Time = " << (endMP - startMP) << endl;
double startAMP = omp_get_wtime();
#pragma omp parallel num_threads(iCnt)
{
#pragma omp for
for (int i = 0; i < iCnt; i++)
{
Mat kealMN = Mat::ones(33, 33, CV_32F);
filter2D(imoriAMP[i], imRsltAMP[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101);
}
}
double endAMP = omp_get_wtime();
cout << " cv AMP Time = " << (endAMP - startAMP) << endl;
double startTbb = omp_get_wtime();
tbb::parallel_for(tbb::blocked_range<size_t>(0, iCnt),
[&](tbb::blocked_range<size_t> r) {
for (size_t i = r.begin(); i < r.end(); i++)
{
Mat kealMN = Mat::ones(33, 33, CV_32F);
filter2D(imoriTbb, imRsltTbb[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101);
}
});
double endTbb = omp_get_wtime();
cout << " cv Tbb Time = " << (endTbb - startTbb) << endl;
double startATbb = omp_get_wtime();
tbb::parallel_for(tbb::blocked_range<size_t>(0, iCnt),
[&](tbb::blocked_range<size_t> r) {
for (size_t i = r.begin(); i < r.end(); i++)
{
Mat kealMN = Mat::ones(33, 33, CV_32F);
filter2D(imoriATBB[i], imRsltATBB[i], CV_32F, kealMN, Point(-1, -1), 0, BORDER_REFLECT_101);
}
});
double endATbb = omp_get_wtime();
cout << " cv Atbb Time = " << (endATbb - startATbb) << endl;
getchar();
return 0;
}
实验结果:
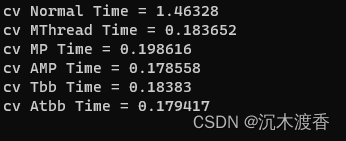
实验结论:
1、OPENMP,TBB可以有效对并行处理进行加速,其效果与多线程处理基本持平。
2、OPENMP,TBB的优势在于代码编写相对简单,也不用考虑线程数的设置。
3、OPENMP,TBB的基础数据独立与否,对测试速度基本不影响(待定,有的同学说会导致各线程等待访问同一数据,引起耗时增加),也可能和PC的性能较好有关。但尽量去保证数据独立性,避免处理结果错误。
ARM实践 TODO


















 1741
1741




 到【灌水乐园】发言
到【灌水乐园】发言









