




本系列最后一篇,我们把目光放到 支持向量机 (Support Vector Machine, SVM)。 SVM 在高光谱遥感中被广泛应用,尤其在样本有限的情况下,常常是最稳健的传统方法之一。
🧩 为什么 SVM 适合遥感?
-
小样本友好:只依赖支持向量,避免过拟合。
-
非线性可扩展:通过核函数(Kernel)映射到高维空间,实现复杂边界。
-
可调灵活:核函数、惩罚系数、gamma 等超参数可针对数据分布优化。
⚙️ 关键参数详解
-
kernel:核函数
-
'linear':线性分割,速度快; -
'rbf'(默认):高斯核,常用; -
'poly':多项式核,较少用; -
'sigmoid':类似神经网络激活函数。
-
-
C:惩罚系数(越大越注重减少误分类,风险是过拟合)。
-
gamma(RBF核特有):控制样本影响范围,越大越“紧”,越小越“松”。
-
probability:若设为 True,可输出类别概率(代价是训练更慢)。
💻 一键可跑代码(KSC:SVM 分类 + 参数对比 + 全图预测)
# -*- coding: utf-8 -*-
"""
Sklearn案例⑳:支持向量机(SVM)分类(KSC 数据)
"""
import os, numpy as np, scipy.io as sio, matplotlib.pyplot as plt, matplotlib
from matplotlib.colors import ListedColormap, BoundaryNorm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.metrics import (confusion_matrix, classification_report,
accuracy_score, cohen_kappa_score)
# ===== 中文显示 =====
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['axes.unicode_minus'] = False
# ===== 参数 =====
DATA_DIR = r"your_path" # ← 修改为KSC数据路径
PCA_DIM = 30
TRAIN_SIZE = 0.3
SEED = 42
# ===== 1) 数据加载 =====
X_cube = sio.loadmat(os.path.join(DATA_DIR,"KSC.mat"))["KSC"].astype(np.float32)
Y_map = sio.loadmat(os.path.join(DATA_DIR,"KSC_gt.mat"))["KSC_gt"].astype(int)
h, w, b = X_cube.shape
coords = np.argwhere(Y_map!=0)
X_all = X_cube[coords[:,0], coords[:,1]]
y_all = Y_map[coords[:,0], coords[:,1]] - 1
num_classes = int(y_all.max()+1)
print(f"[INFO] 有标签像素: {len(y_all)}, 类别数: {num_classes}")
# ===== 2) 分层划分 & 无泄露预处理 =====
X_tr, X_te, y_tr, y_te = train_test_split(
X_all, y_all, train_size=TRAIN_SIZE, stratify=y_all, random_state=SEED
)
scaler = StandardScaler().fit(X_tr)
pca = PCA(n_components=PCA_DIM, random_state=SEED).fit(scaler.transform(X_tr))
def feat(X):return pca.transform(scaler.transform(X))
X_train, X_test = feat(X_tr), feat(X_te)
# ===== 3) SVM 模型 =====
clf = SVC(kernel="rbf", C=20, gamma=0.005, probability=False, random_state=SEED)
clf.fit(X_train, y_tr)
y_pred = clf.predict(X_test)
# ===== 4) 评估 =====
oa = accuracy_score(y_te, y_pred)
kappa = cohen_kappa_score(y_te, y_pred)
cm = confusion_matrix(y_te, y_pred, labels=np.arange(num_classes))
cmn = cm / np.maximum(cm.sum(axis=1, keepdims=True), 1)
print(f"[SVM] OA={oa*100:.2f}% Kappa={kappa:.4f}")
print(classification_report(y_te, y_pred, digits=4, zero_division=0))
# 混淆矩阵
fig, axes = plt.subplots(1, 2, figsize=(11, 4.2), constrained_layout=True)
im0 = axes[0].imshow(cm, cmap=plt.cm.YlGnBu, alpha=0.9)
axes[0].set_title("混淆矩阵(计数)"); axes[0].set_xlabel("预测"); axes[0].set_ylabel("真实")
for i in range(num_classes):
for j in range(num_classes):
axes[0].text(j, i, str(cm[i,j]), ha='center', va='center',
color='black'if cm[i,j]<cm.max()/2else'white', fontsize=9)
fig.colorbar(im0, ax=axes[0], fraction=0.046, pad=0.04)
im1 = axes[1].imshow(cmn, vmin=0, vmax=1, cmap=plt.cm.OrRd, alpha=0.9)
axes[1].set_title("混淆矩阵(归一化)"); axes[1].set_xlabel("预测"); axes[1].set_ylabel("真实")
for i in range(num_classes):
for j in range(num_classes):
axes[1].text(j, i, f"{cmn[i,j]*100:.1f}%", ha='center', va='center', color='black', fontsize=9)
fig.colorbar(im1, ax=axes[1], fraction=0.046, pad=0.04)
plt.show()
# ===== 5) 整图预测 =====
X_flat = X_cube.reshape(-1, b)
pred_map = clf.predict(feat(X_flat)).reshape(h, w) + 1
base_cmap = plt.get_cmap('tab20')
colors = [base_cmap(i % 20) for i in range(num_classes)]
cmap = ListedColormap(colors)
boundaries = np.arange(0.5, num_classes+1.5, 1)
norm = BoundaryNorm(boundaries, cmap.N)
plt.figure(figsize=(8.6,6.4))
im = plt.imshow(pred_map, cmap=cmap, norm=norm)
plt.title("SVM 整图预测结果")
plt.axis("off")
cbar = plt.colorbar(im, boundaries=boundaries,
ticks=np.arange(1,num_classes+1,max(1,num_classes//12)),
fraction=0.046, pad=0.04)
cbar.set_label("类别ID", rotation=90)
plt.show()
# ===== 6) 参数对比(C / gamma)=====
cands = [
("C=10,g=0.01", SVC(kernel="rbf", C=10, gamma=0.01, random_state=SEED)),
("C=20,g=0.005", SVC(kernel="rbf", C=20, gamma=0.005, random_state=SEED)),
("C=50,g=0.001", SVC(kernel="rbf", C=50, gamma=0.001, random_state=SEED)),
]
names, accs = [], []
for n, model in cands:
model.fit(X_train, y_tr)
accs.append(accuracy_score(y_te, model.predict(X_test))*100)
names.append(n)
plt.figure(figsize=(8,8))
x = np.arange(len(names))
plt.plot(x, accs, marker='o', linewidth=2.2)
plt.xticks(x, names, rotation=20, ha='right'); plt.ylabel("OA (%)")
plt.title("SVM 参数对比(C/gamma)")
plt.grid(alpha=0.3, linestyle='--'); plt.tight_layout(); plt.show()
🔍 结果解读
-
混淆矩阵:对比各类识别情况;难分类的地物往往光谱相似。
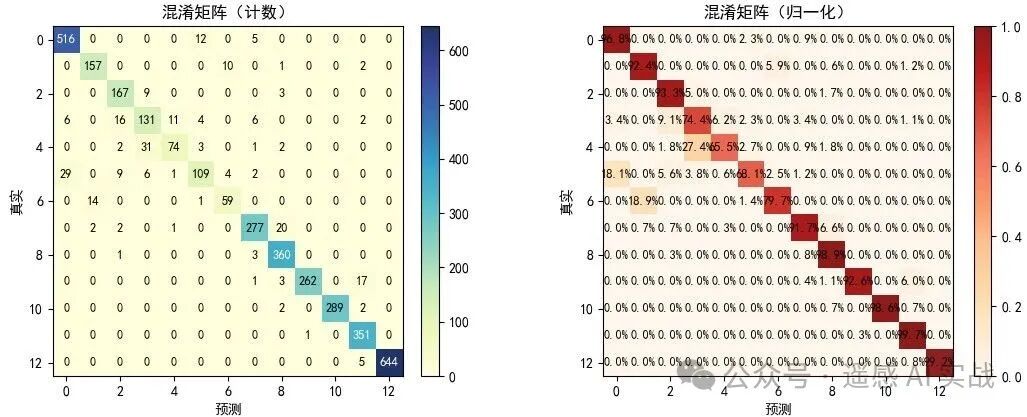
-
整图预测:SVM 结果通常边界清晰、噪声较少。
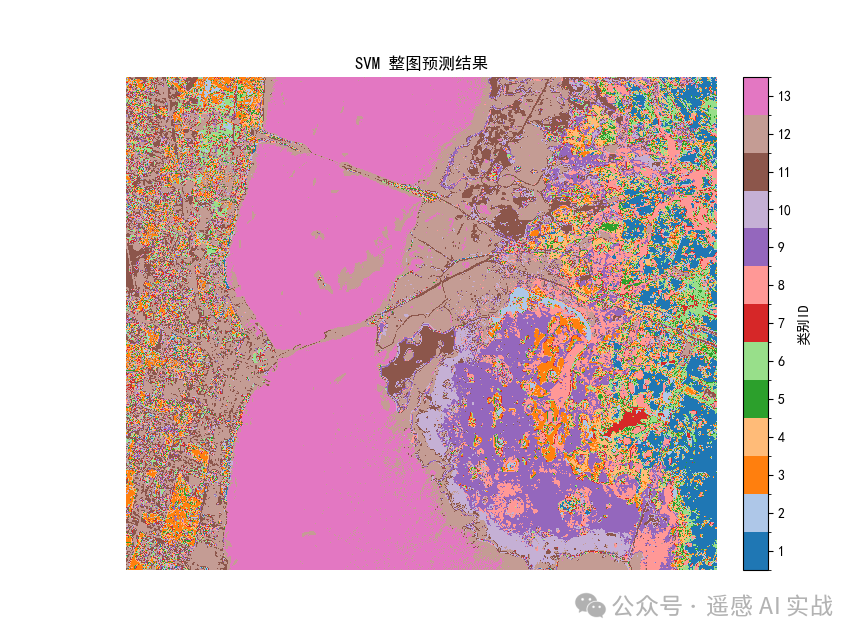
-
参数对比:
-
C越大 → 更强约束 → 边界更贴合训练 → 容易过拟合; -
gamma越大 → 影响范围小 → 更复杂边界;过小 → 欠拟合。
-
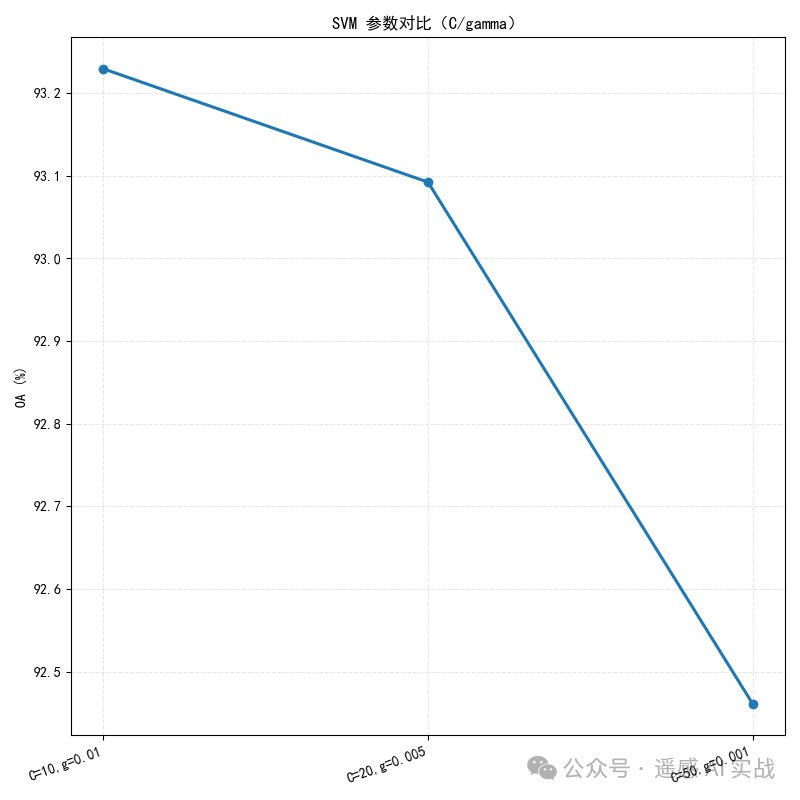
✅ 总结
-
SVM 是遥感分类的黄金基线,特别适合样本不足或类间边界复杂的情况。
-
超参选择很关键,建议:
-
先
kernel='rbf'; -
网格搜索
C, gamma; -
样本多时可先 PCA。
-
-
实战里,SVM 常被用来和随机森林、神经网络等方法做对比。
👉 至此,本系列 20 篇 Sklearn × 遥感实战教程 就全部结束啦! 从 预处理 → 分类器 → 集成 → 半监督 → 可视化 → SVM终章,我们完成了一个完整的 传统机器学习 & 遥感 入门路径。
接下来我会从最基础开始写一系列小工具和进阶内容教程,如深度学习等。
欢迎大家关注下方公众号获取更多内容!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











