




在真实科研与工程中,强烈建议直接使用自己的遥感影像与标签数据,这样实验才具有实际意义。 不过,很多同学刚开始学习时可能没有准备好的数据集,可以借助 sklearn.datasets 里的内置与生成数据集功能来做练习。
往期内容和数据链接如下:
🧩 datasets 模块能做什么?
sklearn.datasets 提供了三类常见功能:
-
内置小数据集:适合快速上手,常见有:
-
load_iris():鸢尾花分类 -
load_digits():手写数字(8×8 灰度图) -
load_wine():红酒分类 -
load_breast_cancer():乳腺癌诊断
-
-
下载大型公开数据集(通过
fetch_前缀):-
fetch_olivetti_faces():人脸数据 -
fetch_20newsgroups():新闻分类文本 -
fetch_openml():通用接口,可从 OpenML 平台拉取上百个公开数据集
-
-
生成模拟数据(适合调试算法):
-
make_classification():生成可控特征和类别的分类数据 -
make_blobs():聚类数据 -
make_moons()、make_circles():非线性可分的二维玩具数据
-
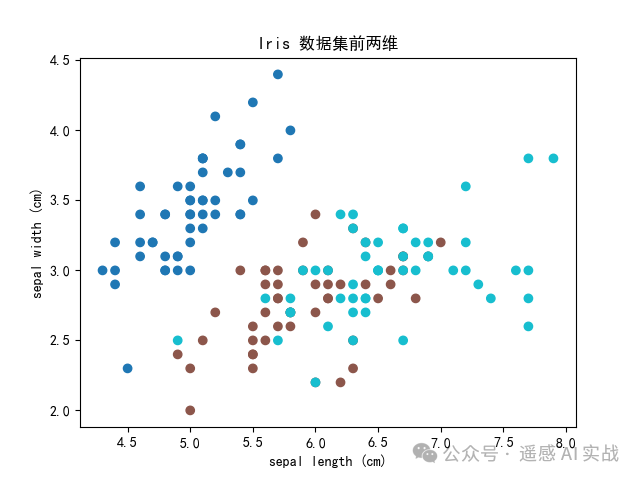
💻 示例1:加载内置鸢尾花数据集
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
X, y = iris.data, iris.target
print("数据形状:", X.shape)
# 简单可视化
plt.scatter(X[:,0], X[:,1], c=y, cmap="tab10")
plt.xlabel(iris.feature_names[0]); plt.ylabel(iris.feature_names[1])
plt.title("Iris 数据集前两维")
plt.show()
输出:四维特征(萼片/花瓣长宽),三类花(Setosa/Versicolor/Virginica)。
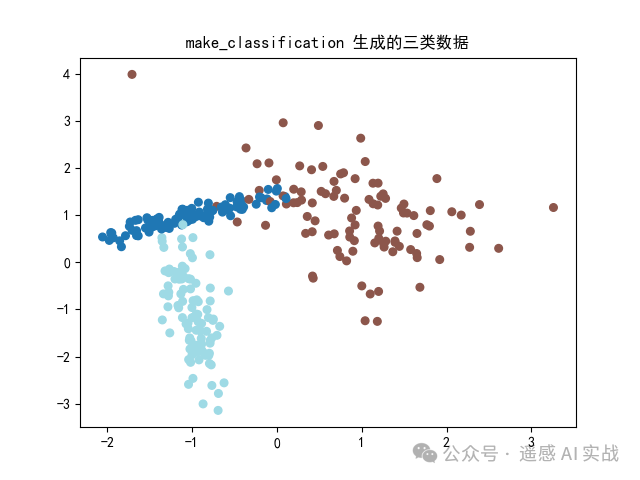
💻 示例2:生成模拟分类数据
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
X, y = make_classification(
n_samples=300, n_features=2, n_redundant=0, n_clusters_per_class=1,
n_classes=3, random_state=42
)
plt.scatter(X[:,0], X[:,1], c=y, cmap="tab20", s=30)
plt.title("make_classification 生成的三类数据")
plt.show()
这样就能快速生成一个分类任务,适合调试 SVM、kNN 等分类器。
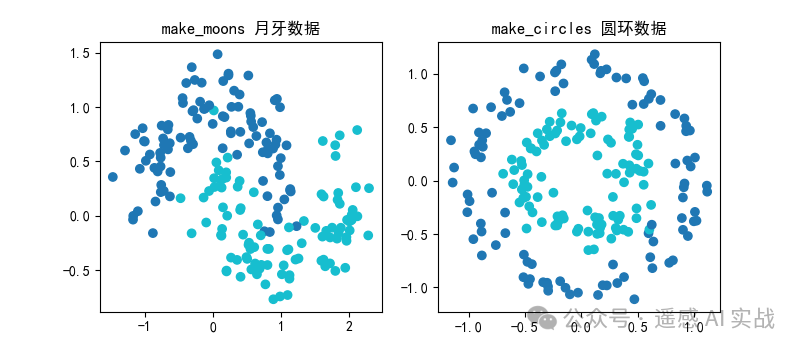
💻 示例3:非线性分布数据
from sklearn.datasets import make_moons, make_circles
import matplotlib.pyplot as plt
X1, y1 = make_moons(n_samples=200, noise=0.2, random_state=42)
X2, y2 = make_circles(n_samples=200, noise=0.1, factor=0.5, random_state=42)
plt.figure(figsize=(8,3.5))
plt.subplot(1,2,1)
plt.scatter(X1[:,0], X1[:,1], c=y1, cmap="tab10")
plt.title("make_moons 月牙数据")
plt.subplot(1,2,2)
plt.scatter(X2[:,0], X2[:,1], c=y2, cmap="tab10")
plt.title("make_circles 圆环数据")
plt.show()
这类数据常用于展示 非线性分类器(如核SVM、神经网络)的优势。
✅ 小结
-
sklearn.datasets非常适合入门学习与算法调试,但不适合直接替代真实的遥感实验。 -
在实际工作中,应该使用 Sentinel、Landsat、高分等真实遥感影像;而在教学、算法原型验证时,可以用
make_classification或make_moons快速生成样例。 -
建议同学们:用 datasets 快速练手,理解算法 → 再切换到真实遥感数据完成应用。
欢迎大家关注下方公众号获取更多内容!


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











