



点击上方“Python数据之道”,选择“星标公众号”
只收藏文章,不点在看的,都是耍流氓

作者 | Python语音识别
来源 | 深度学习与python
介绍 5 个强大的 Scikit-learn 算法
Logistic回归
Logistic回归为概率型非线性回归模型,是研究二分类观察结果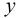 与一些影响因素
与一些影响因素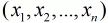 之间关系的一种多变量分析方法。可用于数据分类和曲线拟合回归。
之间关系的一种多变量分析方法。可用于数据分类和曲线拟合回归。
from sklearn.ensemble import LogisticRegressionsoftmax_reg = LogisticRegression(multi_class =“multinomial”,solver =“lbfgs”,C = 5) softmax_reg.fit(X,Y) pred = softmax_reg.predict(X_test) import LogisticRegression
softmax_reg = LogisticRegression(multi_class =“multinomial”,solver =“lbfgs”,C = 5)
softmax_reg.fit(X,Y)
pred = softmax_reg.predict(X_test)

支持向量机
支持向量机通过构建超平面来对数据集进行分类工作,其内部可采用不同的核函数以满足不同数据分布,目前支持向量机怕是大家最熟悉的一种机器学习算法了吧。
from sklearn.ensemble import svmclf = svm.SVC(gamma ='scale',decision_function_shape ='ovo') clf.fit(X,Y) pred = clf.predict(X_test) import svm
clf = svm.SVC(gamma ='scale',decision_function_shape ='ovo')
clf.fit(X,Y)
pred = clf.predict(X_test)

朴素贝叶斯
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯也许是本文中讨论的所有模型中最简单的一个。朴素贝叶斯非常适合少量数据的参数估计。朴素贝叶斯应用贝叶斯定理,其假设每个特征之间具有条件独立性。

from sklearn.ensemble import GaussianNBclf = GaussianNB() clf.fit(X,Y) pred = clf.predict(X) import GaussianNB
clf = GaussianNB()
clf.fit(X,Y)
pred = clf.predict(X)

随机森林
随机森林是一种基于Bagging的集成学习模型。通过使用Bootstraping从原数据集随机抽取n个子数据集来训练n颗决策树,然后再将n颗决策树结果结合起来形成准确率更高的强学习器。特别是在Kaggle比赛中。随机森林通过在数据集的子样本上拟合决策树分类器。然后综合分类性能以获得高精度,同时避免过度拟合。
from sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(n_estimators = 100,max_depth = 2,random_state = 0) clf.fit(X,Y) pred = clf.predict(X)import RandomForestClassifier
clf = RandomForestClassifier(n_estimators = 100,max_depth = 2,random_state = 0)
clf.fit(X,Y)
pred = clf.predict(X)

AdaBoost
AdaBoost是一种集成学习模型分类器,是典型的Boosting算法,属于Boosting家族的一员。AdaBoost思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类的样本权值,提高那些被错误分类的样本权值。然后,再根据所采用的基学习器进行学习训练。其在sklearn中调用的示例代码如下:
from sklearn.ensemble import AdaBoostClassifierclf = AdaBoostClassifier(n_estimators = 100) clf.fit(X,Y) pred = clf.predict(X)import AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators = 100)
clf.fit(X,Y)
pred = clf.predict(X)

总结
sklearn是机器学习的一个最佳选择,里面有常用的分类算法、回归算法、无监督算法以及数据处理接口,调用只需几行代码就可以实现你的机器学习模型。通过本次的5个示例,相信你已经能基本掌握sklearn中算法调用方式,在需要调用其它算法时方式都是一样的,希望能对你的机器学习之路有所帮助。
本文详细代码参考Github:
https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://github.com/Poseyy/Articles/tree/master/5SkLearnModels&xid=17259,15700021,15700186,15700190,15700253,15700256,15700259&usg=ALkJrhi6qM1ShHuE5JWexjuMvX0AWcKgDA
sklearn中文文档
http://sklearn.apachecn.org/cn/0.19.0/
-------------------End-------------------
Python数据之道

据说学Python的只有10%的人关注了这个号,
还有很大潜力

今日主题:机器学习算法,你觉得哪些最有意思~
留言格式:昵称 + day xx + 留言内容(字数不少于15字)
欢迎各位同学加入公众号读者分享交流群,在公众号后台回复 “微信群” 即可。

同学们,支持就请右下角点 !
!

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









