






 本文探讨了机器学习中对话式训练(DT)与最大似然(ML)训练的区别,重点介绍了DT的目标函数及其优化过程。DT关注训练语音对于训练文本的概率最大化,通过贝叶斯公式解释了DT目标函数的构成,并讨论了实际应用中如何通过n-bestlist或lattice进行近似计算。此外,文章还提到了EM算法和Generalized EM算法在训练问题中的应用。
本文探讨了机器学习中对话式训练(DT)与最大似然(ML)训练的区别,重点介绍了DT的目标函数及其优化过程。DT关注训练语音对于训练文本的概率最大化,通过贝叶斯公式解释了DT目标函数的构成,并讨论了实际应用中如何通过n-bestlist或lattice进行近似计算。此外,文章还提到了EM算法和Generalized EM算法在训练问题中的应用。
X表示训练数据中的语音信号,W代表训练数据中的文本,θθ \theta
θ代表声学模型参数,LM语言模型是固定的。
ML的目标函数是:
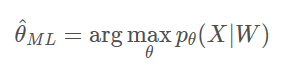
DT的目标函数是:
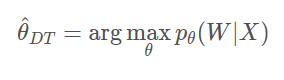
别在于条件概率不同。ML中,只要训练文本产生训练语言的概率大就行了。而DT要求的是训练语音对于训练文本的概率大。即就是要训练文本产生训练语音的概率,与其他文本产生训练语音的概率之差大。对DT目标函数用一次贝叶斯公式就可以看出:
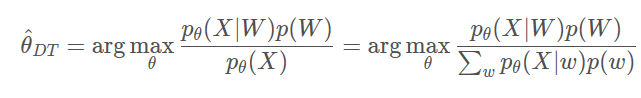
分子上的pθ(X∣W),正是ML的目标函数;而分母则是所有文本(包括训练文本和它的所有竞争者)产生训练语音的概率(按语言模型加权的)和。
由于分母上要枚举所有可能的文本并不现实,所以实际中,一般使用一个已有的ML训练的语音系统对训练语音做一次解码,得到n-best或lattice,用这里面的文本来近似分母上的求和。n-best list或lattice中包含了训练文本的足够接近的竞争者。
对DT的目标函数取对数,可以得到:
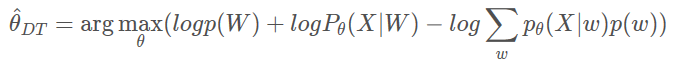
右边第一项logp(W)是常数,可忽略,第二项是ML的目标函数的对数,第三项的形式与第二项有相似之处。
ML训练问题一般使用EM算法来解决的,DT训练多了第三项,同样有Generalized EM算法来求解。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









