






 本文介绍了OCR技术的基本概念,强调了其在Total Control设备控制接口中的应用。通过Total Control提供的百度OCR接口,用户可以获取手机屏幕或指定图片上的文字,提升设备控制的效率和便捷性。
本文介绍了OCR技术的基本概念,强调了其在Total Control设备控制接口中的应用。通过Total Control提供的百度OCR接口,用户可以获取手机屏幕或指定图片上的文字,提升设备控制的效率和便捷性。
什么是OCR?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
OCR也可简单地称为文字识别,是文字自动输入的一种方法。它通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,所以,OCR是一种非常快捷、省力的文字输入方式,也是在文字量比较大的今天,很受人们欢迎的一种输入方式。
总结起来就是一句话,将图像的文字转化成为字符。
OCR与Total Control脚本的联系
在 Total Control的设备控制接口中,我们提供了一些文字识别的接口,用户可以通过Total Control 提供的接口获取整个手机屏幕的文字,也可以获取手机屏幕上指定范围的文字。这样快捷的文字输入方式,会给用户带来很多方便。
在 Total Control的接口中,我们针对百度和Google 的OCR分别提供了文字识别接口。
• 百度ORC的四个接口:
loginBaiduCloud('API KEY', 'Secret Key'),
getTextByBaiduCloudOnAndroid(),
BDOcr.login(AppID, APIKey, SecretKey) ,
BDOcr.getText(filename, lang)
• Google OCR 的两个接口:
uploadTessData(fileName)
analyzeText(x1, y1, x2, y2, lang, mode)
百度OCR
百度OCR支持多场景下的文字检测识别,多项ICDAR指标世界第一,支持中、英、葡、法、德、意、西、俄、日、韩、中英混合识别,整体识别准确率高达90%以上,并提供高精度版,满足您更高的要求。
如何获取百度OCR账号
1. 注册百度云帐号并登录,链接为https://cloud.baidu.com/。
2. 在百度云中点击“产品服务”—>”人工智能”,进入文字识别链接为[https://console.bce.baidu.com/#/index/overview,如下图所示:
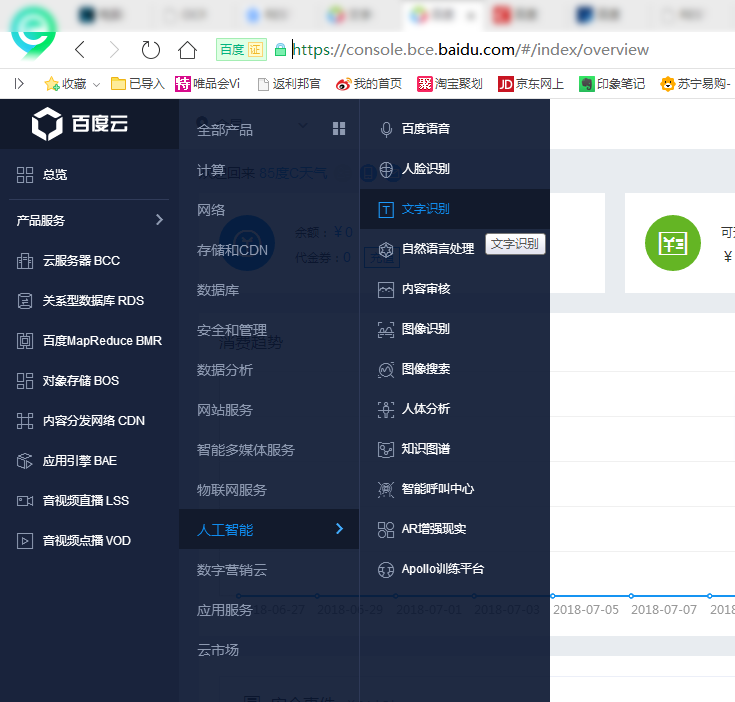
1. 进入下一页后点击创建应用,如下图所示
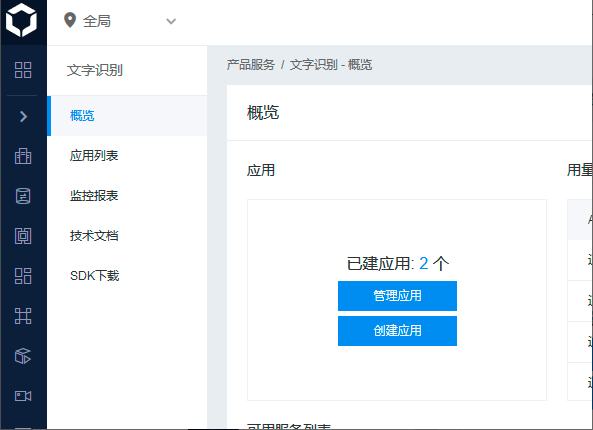
2. 在创建新应用的页面中,a)任意输入应用名称;b)应用类型选择“工具应用”;c)接口选择保持缺省。d)文字识别包名可以选择不需要,不过如果希望以后能够使用android版的文字识别,此处则要选择“需要”,Android后的输入栏内输入” com.sigma_rt.totalcontrol”。
如下图所示:

3. 点击立即创建,则可以获取自己的百度云OCR帐号,您能看到AppID,API Key,和Secret Key,这三个参数在对于后面的接口是必需的。如下图所示:
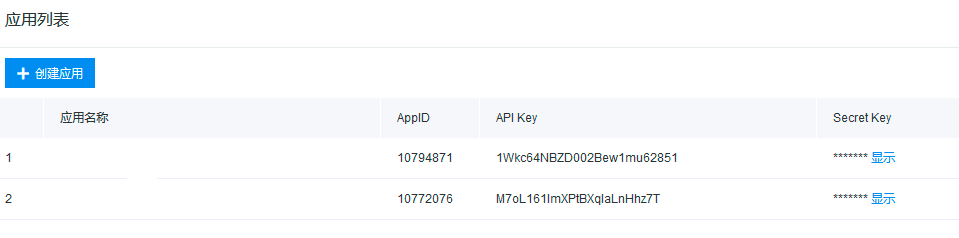
如何使用百度OCR接口
(一)获取手机屏幕上指定范围的文字
1. 申请自己的百度OCR帐号,获取API Key和Secret Key。详情请看【如何获取百度OCR账号】。
2. 用JS API “loginBaiduCloud”登陆百度OCR,例如:
var res = device.loginBaiduCloud('API KEY', 'Secret Key');
3. 利用设备接口“getTextByBaiduCloudOnAndroid”获取手机屏幕上的文字。例如:
res = device.getTextByBaiduCloudOnAndroid(11,366,701,716);
print("获取到的文字:\n"+res);
(二)获取指定图片上的文字
1. 申请自己的百度OCR帐号,获取AppID,API Key和Secret Key。详情请看【如何获取百度OCR账号】。
2. 用JS API “BDOcr.login”登陆百度OCR,例如:
BDOcr.login(AppID, APIKey, SecretKey)
3. 利用接口BDOcr.getText获取指定图片上的文字。例如:
var res=BDOcr.getText('E:\\Temp\\120\\1.jpg', 'CHN_ENG');
print(res);
BDOcr.getText的参数:
•filename:要解析图片的文件名
•lang:解析出来的语言标识,有如下选项:
CHN_ENG:中英文混合;
ENG:英文;
POR:葡萄牙语;
FRE:法语;
GER:德语;
ITA:意大利语;
SPA:西班牙语;
RUS:俄语;
JAP:日语;
百度OCR接口示例
(一)获取手机屏幕上的文字,手机屏幕如下图所示:
示例1:图中红色框表示屏幕坐标(11,366,701,716)
获取当前手机屏幕坐标(11,366,701,716)内的文字
//获取当前主控设备对象
var device = Device.getMain();
//登陆百度OCR,'API KEY', 'Secret Key'填入自己申请的账号密码
var res = device.loginBaiduCloud('API KEY', 'Secret Key');
if (res == false) {
print(lastError());
} else {
//获取当前手机屏幕坐标(11,366,701,716)内的文字
res = device.getTextByBaiduCloudOnAndroid(11,366,701,716);
print("获取到的文字:\n"+res);
}
示例2:
获取当前手机整个屏幕内的文字
//获取当前主控设备对象
var device = Device.getMain();
//登陆百度OCR,'API KEY', 'Secret Key'填入自己申请的账号密码
var res = device.loginBaiduCloud('API KEY', 'Secret Key');
if (res == false) {
print(lastError());
} else {
//获取当前手机整个屏幕内的文字
res = device.getTextByBaiduCloudOnAndroid();
print("获取到的文字:\n"+res);
}
运行结果
示例1:运行结果
Total control电脑控制手机手机群控系统
编程脚本自动化支持 REST AP/JS官网
Tota| Control手机控是一款用电脑控制手机的软件,可
自动化同步群控高达100台(可更多)手机。旗下TC
Games电脑控制手机玩游戏。提供手机投屏电脑
tc.sigma-rt.com.cn
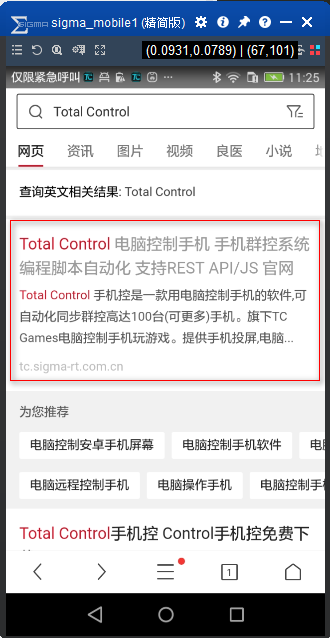
示例2:运行结果
仅限紧急呼叫E忑AE因E
农令[14:12
Q Total Control
)e
网页资讯图片视频良医小说
查询英文相关结果: Total contro
Tota| Control电脑控制手机手机群控系统
编程脚本自动化支持 REST AP|/JS官网
Tota| Contro|手机控是一款用电脑控制手机的软件,可
自动化同步群控高达100台(可更多)手机。旗下TC
Games电脑控制手机玩游戏。提供手机投屏电脑
tc sigma-rt. com. cn
为您推荐
电脑控制安卓手机屏幕电脑控制手机软件电
电脑远程控制手机电脑操作手机电脑控制手
Total control手机控 Control手机控免费下
(二)获取指定图片上的文字,图片如下

//登陆百度OCR,‘AppID’,'API KEY', 'Secret Key'填入自己申请的账号密码
BDOcr.login('AppID', ' API KEY ', 'Secret Key');
//获取图片mypic.png内的文字
var res=BDOcr.getText('E:\\sigmaTC\\产品20180611\\ocr\\mypic.png', 'CHN_ENG');
print(res);
运行结果
杰华科枝
首页
Total Control
TC Games
智能投屏专家
手机/电脑/智电视(投影仪)/平板/车载电脑互投互控
万屏互联,多屏互动

















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









