







视频连接
https://www.youtube.com/watch?v=7VeUPuFGJHk
树的基本结构
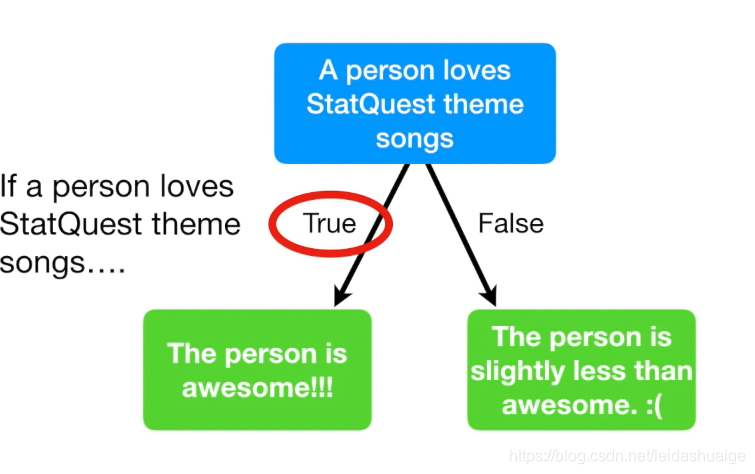
问一个问题,然后根据回答来判断结果
树的完整结构
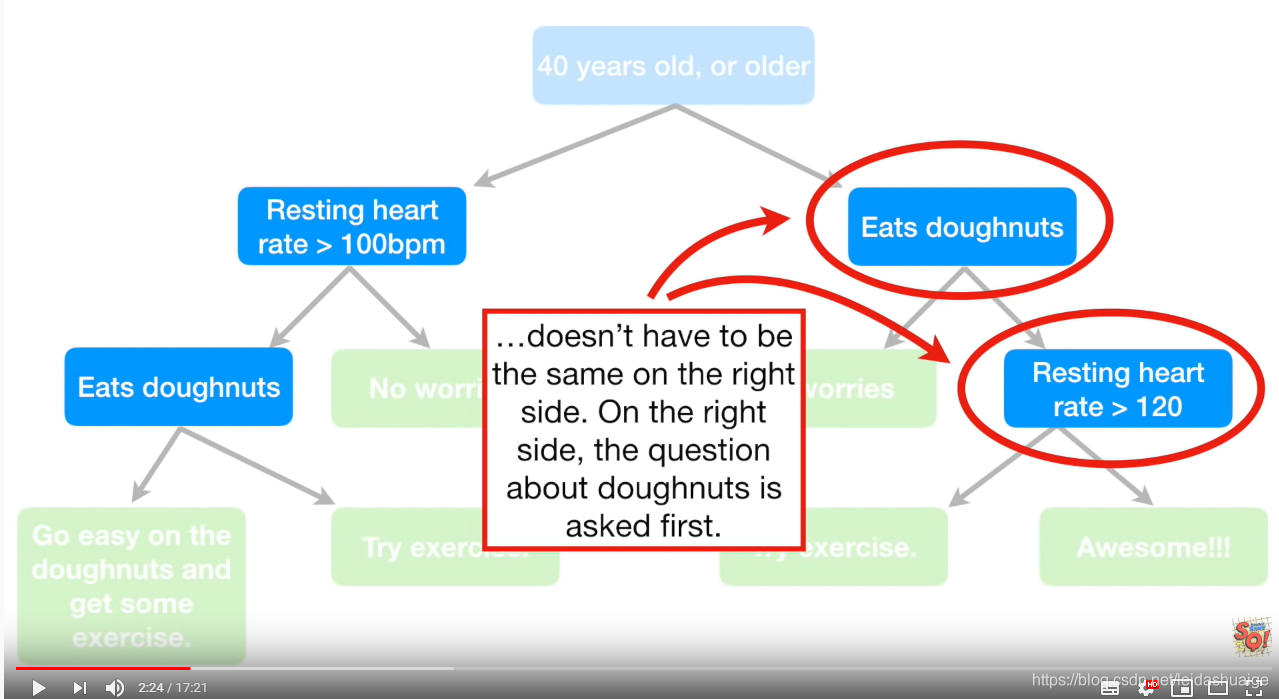
描述
- 顶层浅蓝色为root node
- 蓝色为internal node
- 绿色为 leaf node
注意点
- root node的问题很重要
- 问题可以被重复
- 结果可能被重复
如何构造一个树
选择根节点
使用每一个feature对于结果的相关性进行比较
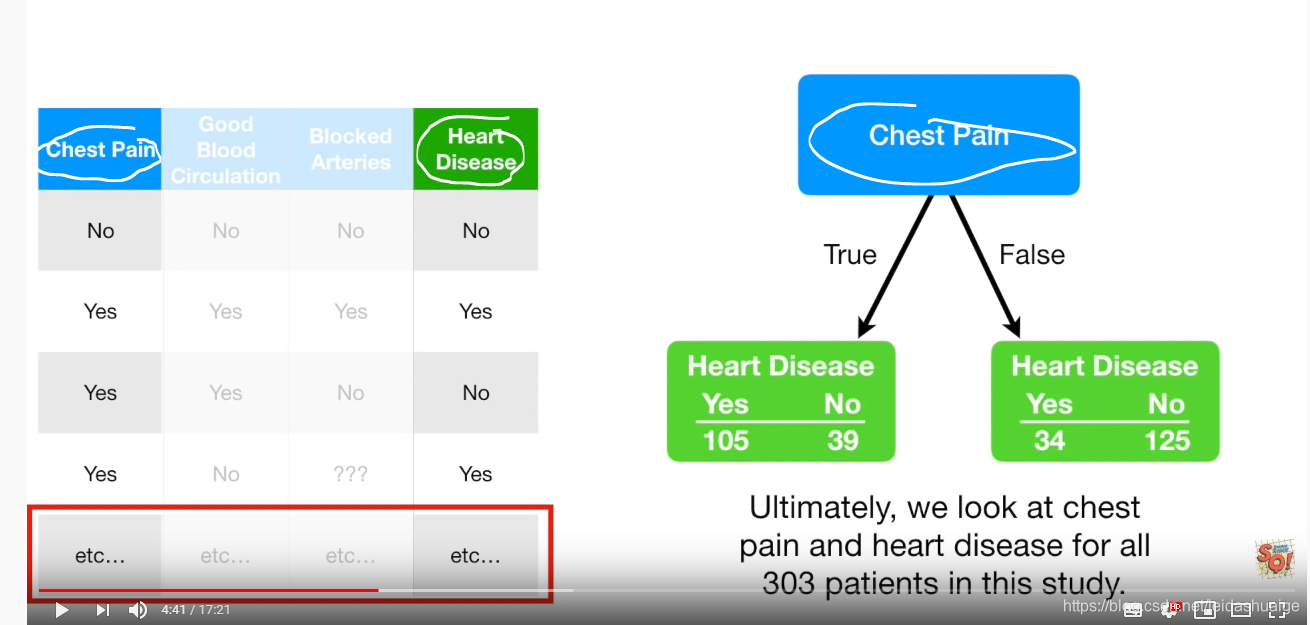
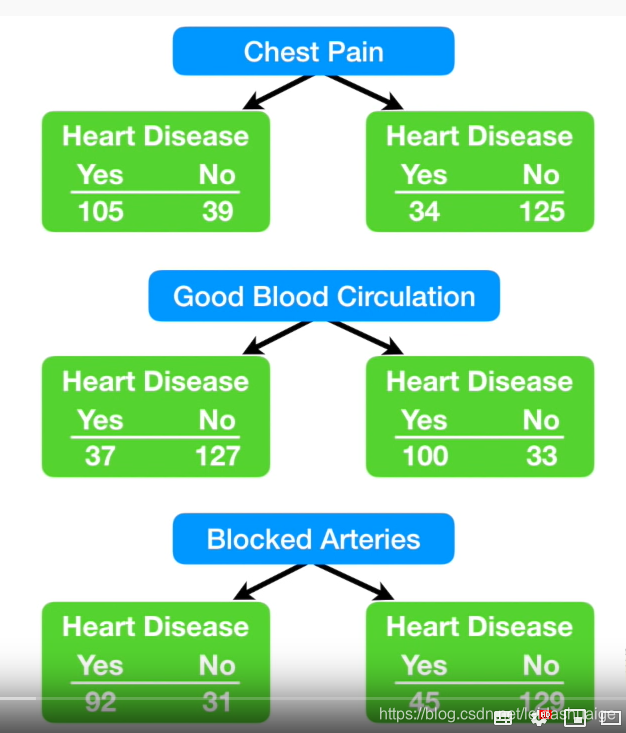
问题
- 因为有数据不全的情况,不同特征的总数不会相等
- 同一特征的左右数据总量不相等
如何解决这个问题
- 使用Gini公式计算每个分支的相关性
注意:Gini越小则该特征越有用

2.使用Gini impurity来表达一个feature的有效性
Gini impurity = 使用加权平均Gini公式
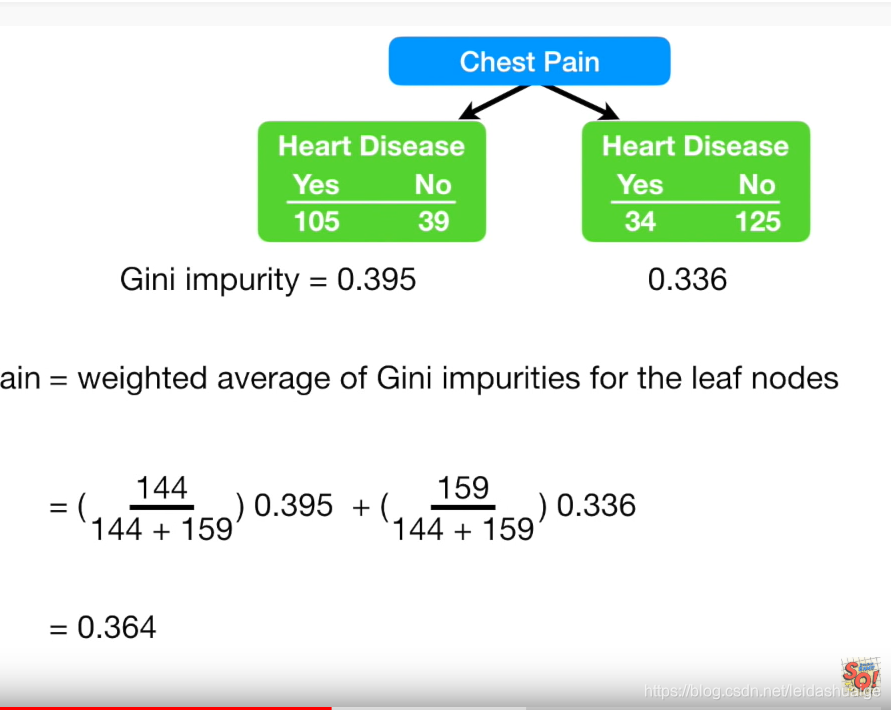
- 选择最小的相关性的作为root note
迭代选择internal Note
选择哪一个作为节点
如同选择根节点的note一样,我们这里还是计算Gini impurity
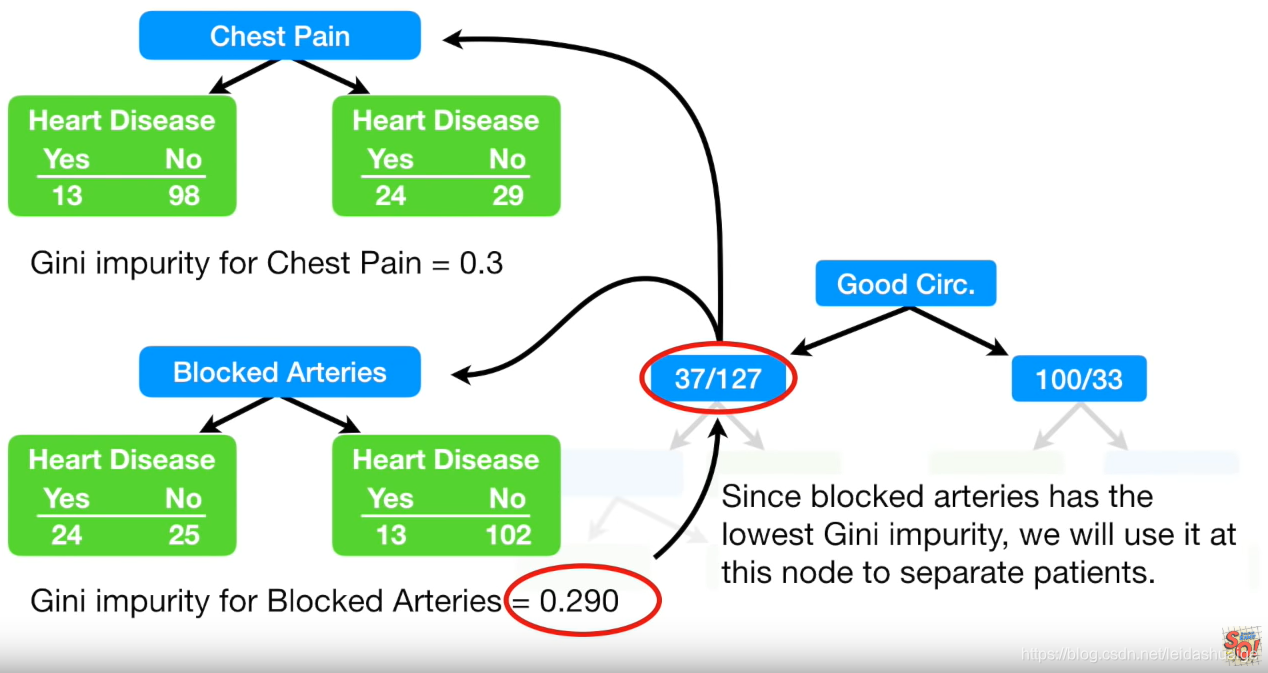
何时终止迭代
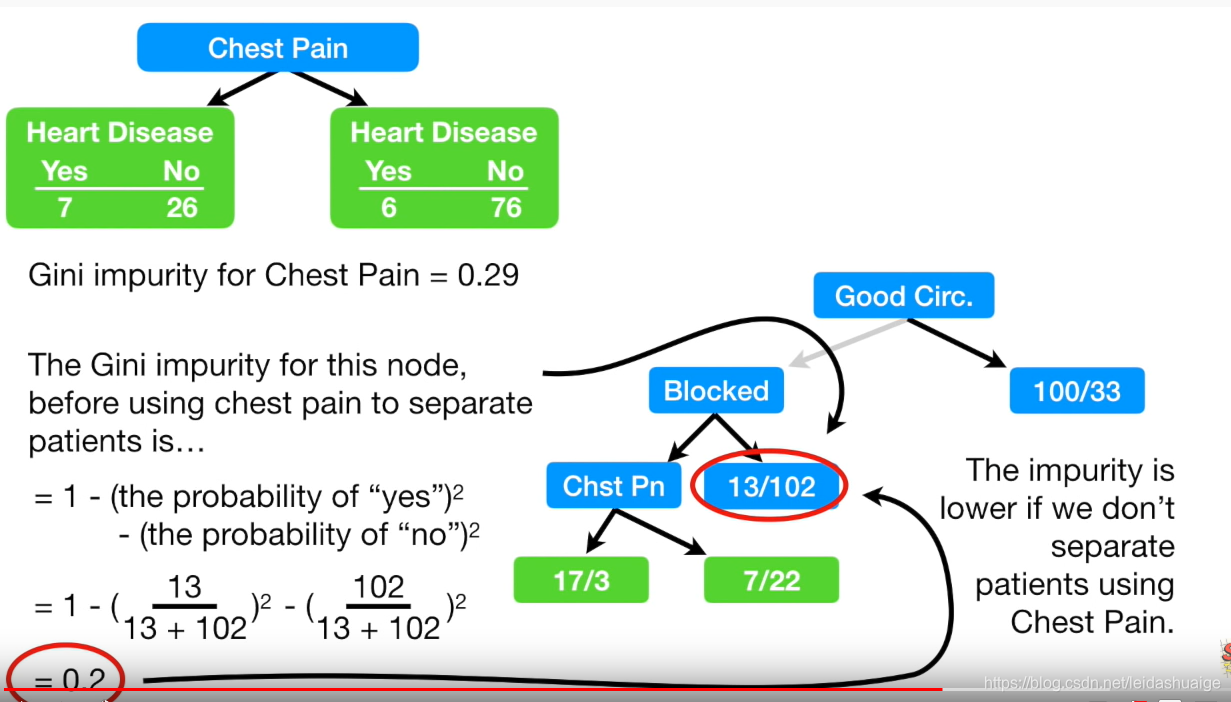
如果该节点计算所有feature的Gini impurity 均小于该节点的Gini score则不用往下迭代了。
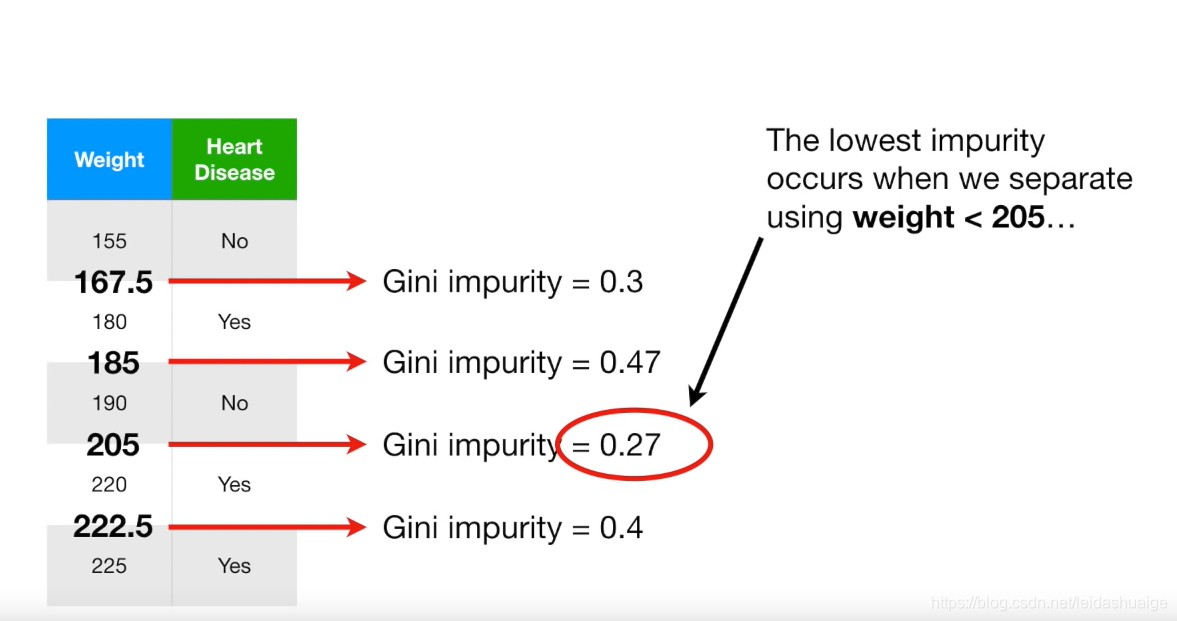
问题:如果该feature为数值类型怎么办?
- 将该数值升序排序,并且平均相邻的数值
- 将该数值作为分割点计算Gini impurity
- 选择最低分数的点作为最终的分割点
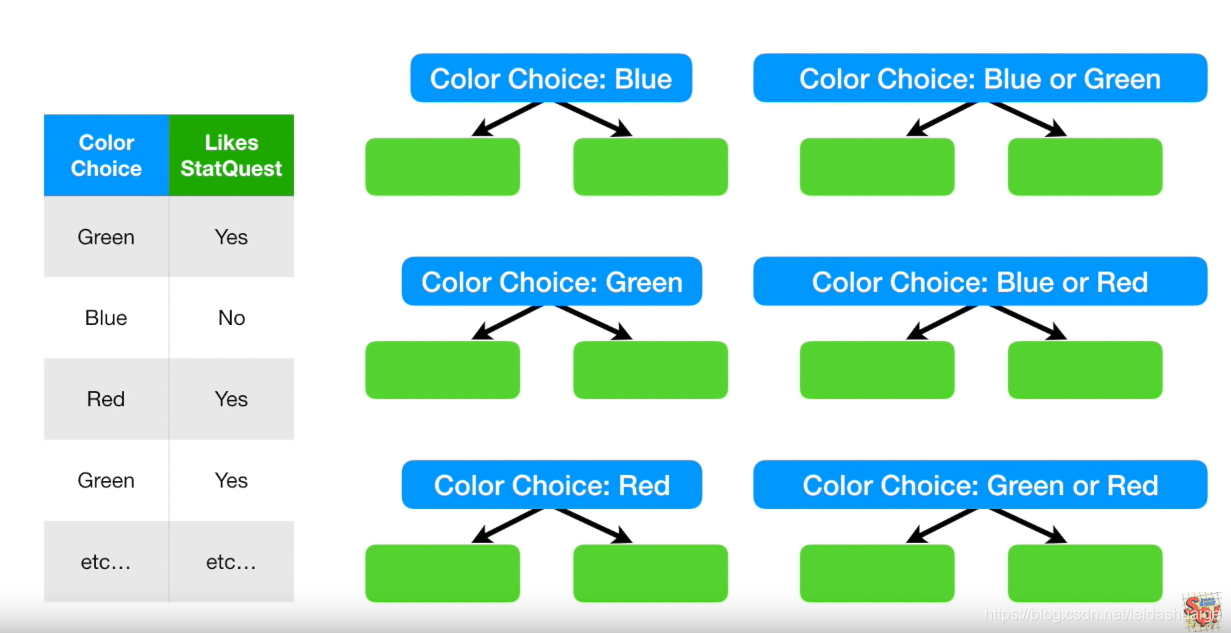
问题:如果该feature为category类型怎么办
- 给出该category的所有单个或者or组合
- 计算全部点的Gini impurity
- 选择最低的那个作为分割
feature importance 如何计算
就是单独计算每个节点的Gini impurity ,最低的就是最相关的
sklearn的 feature importance 可能是 1- Gini impurity
sk learn tree的参数解释
max_depth
树的总深度,越深的话越overfit。但是默认就是很深
min_samples_split
internode最小的sample
min_samples_leaf
最小叶子节点的sample数量
默认为1
min_weight_fraction_leaf
最小叶子节点要有的sample数量占所有sample数量的比例
max_features
最多的feature数量,默认为max_feature
结论
-
由树的原理来看,树结构对已经见到过的数据拟合效果会非常的好。没有见过的数据,拟合效果非常的差
-
sklearn的默认参数就是最能够过拟合的参数了,调整其他参数,仅仅是用来防止过拟合

















 5764
5764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









