




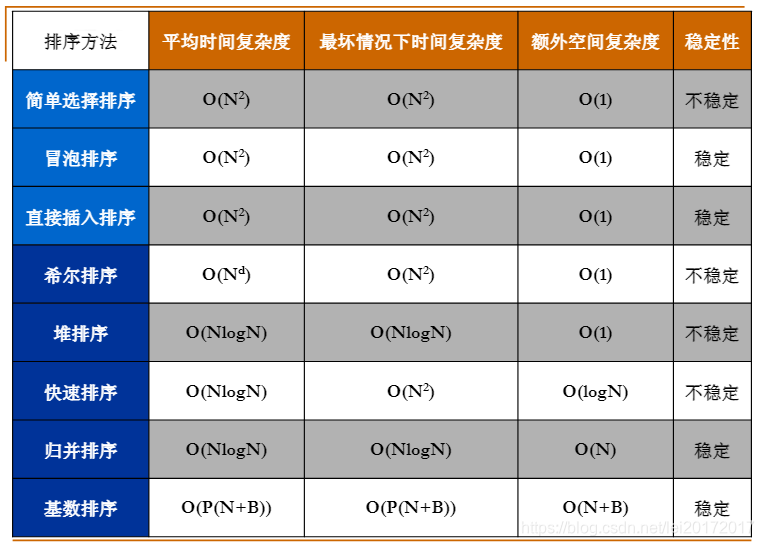
 本文详细介绍了在C语言中实现的8种排序算法(直接插入、折半插入、希尔排序、简单选择、堆排序、冒泡排序、快速排序和归并排序),并对在不同数据规模(100、10000、1000000)及正序、逆序、随机序下的排序时间进行测试,并通过图表展示结果。实验结果显示了排序算法在不同场景下的性能优劣。
本文详细介绍了在C语言中实现的8种排序算法(直接插入、折半插入、希尔排序、简单选择、堆排序、冒泡排序、快速排序和归并排序),并对在不同数据规模(100、10000、1000000)及正序、逆序、随机序下的排序时间进行测试,并通过图表展示结果。实验结果显示了排序算法在不同场景下的性能优劣。
内部排序算法效率比较,数据结构实验,C语言实现
注:完整代码可以到我的小程序 航筱北同学 上搜索查看。

1.直接插入排序
2.折半插入排序
3.希尔排序
4.简单选择排序
5.堆排序
6.冒泡排序
7.快速排序
8.归并排序
实验内容与要求
对我们所学过的各种排序算法,分别测试统计数据量为100、10000、1000000时各自在正序、逆序、随机序时所耗的时间,写出分析报告。可用图表说明你的分析内容。(确保算法正确的情况下可以不需要输出,以节约时间)
实验过程
1.首先,写出各个排序算法的C语言代码【详见后面的代码】;
2.声明一个存储待排序数据的数组,数组的RMaxSize定为1000000;
R[RMaxSize]应该放在main主函数的前面,不要放在main函数的里面,可能main函数里面可分配的数组空间有限。
#define RMaxSize 1000000
int R[RMaxSize];
3为了测算出排序时消耗的时间,我们还要引入time库,用到里面的库函数clock();
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
#define RMaxSize 1000000
int R[RMaxSize];
clock_t start,stop; //colck_t是clock()函数返回的变量类型
4.可以通过类似下面的代码来测算各个排序方法排序时所消耗的时间。
start = clock();
//要记录运行时间的被测函数或某段过程将嵌入到这里
stop = clock();
duration = stop - start; // 将某段过程执行结束时的时间减去开始执行时的时间即得到该段过程的运行时间,以毫秒为单位,duration为以声明类型过的的变量
比如,要测试某次排序的耗时,可写如下代码
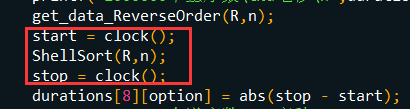
**5.为了对之前的8种排序算法的时间效率进行对比,我们需要把它们各自在不同数据量排序时的耗时记录下来。**所以,可以通过数组来存储,但是为了更加方便和直观的输出结果,决定采用二维数组来存储这些运行时间,并且,为了不那么变扭,决定把二维数组的第一行和第一列废弃掉,即durations[0][j]和durations[i][0]废弃。到时候输出的结果应该类似这样的表格格式,更加直观。当然,此时的数组内容已经初始化为-1,为了和0区分,-1代表未统计。
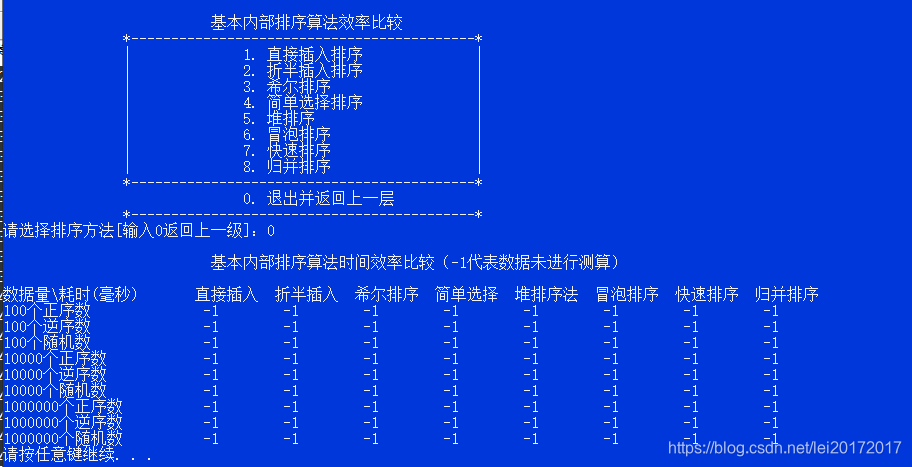
可以通过如下代码来设计这个表格,对数据进行格式化输出
void showResultTable() {
printf("\n 基本内部排序算法时间效率比较\n");
printf("\n%6s \t%6s %6s %6s %6s %6s %6s %6s %6s\n", "数据量\\耗时(毫秒)", "直接插入", "折半插入", "希尔排序", "简单选择", "堆排序法","冒泡排序","快速排序","归并排序");
printf("%10s\t %8d %8d %8d %8d %8d %8d %8d %8d\n","100个正序数",durations[1][1],durations[1][2],durations[1][3],durations[1][4],durations[1][5],durations[1][6],durations[1][7],durations[1][8]);
printf("%10s\t %8d %8d %8d %8d %8d %8d %8d %8d\n","100个逆序数",durations[2][1],durations[2][2],durations[2][3],durations[2][4],durations[2][5],durations[2][6],durations[2][7],durations[2][8]);
printf("%10s\t %8d %8d %8d %8d %8d %8d %8d %8d\n","100个随机数",durations[3][1],durations[3][2],durations[3][3],durations[3][4],durations[3][5],durations[3][6],durations[3][7],durations[3][8]);
printf("%10s\t %8d %8d %8d %8d %8d %8d %8d %8d\n","10000个正序数",durations[4][1],durations[4][2],durations[4][3],durations[4][4],durations[4][5] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









