




 本文介绍了如何使用Python结合Selenium自动化测试工具来登录网易云音乐并获取cookie,以便爬取私人歌单。通过创建Scrapy爬虫项目,利用Selenium模拟登录获取cookie,并将其转化为适合Scrapy的格式,最终实现对特定歌单的爬取。
本文介绍了如何使用Python结合Selenium自动化测试工具来登录网易云音乐并获取cookie,以便爬取私人歌单。通过创建Scrapy爬虫项目,利用Selenium模拟登录获取cookie,并将其转化为适合Scrapy的格式,最终实现对特定歌单的爬取。
一
cookie是什么东西?
小饼干?糖果?能吃吗?
简单来说就是你第一次用账号密码访问服务器
服务器在你本机硬盘上设置一个身份识别的会员卡(cookie)
下次再去访问的时候只要亮一下你的卡片(cookie)
服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上
二
需求分析
爬虫要访问一些私人的数据就需要用cookie进行伪装
想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去
但是在火狐的F12截取到的数据就是,
网易云音乐先将你的账号密码给编了码,再发post请求
所以我们在准备表单数据的时候就已经被卡住了
这时候我们就可以使用自动化测试Selenium帮助我们去登录
登录好之后就获取cookie给爬虫使用
OK,废话也废话完了,直接开整吧!!
首先跟我创建一个爬虫项目和爬虫
在CMD创建
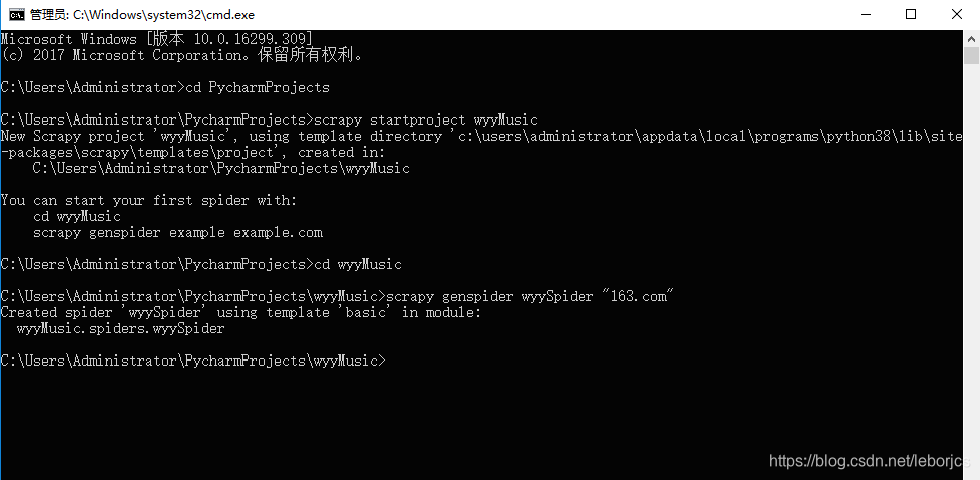
用Pycharm打开这个项目:
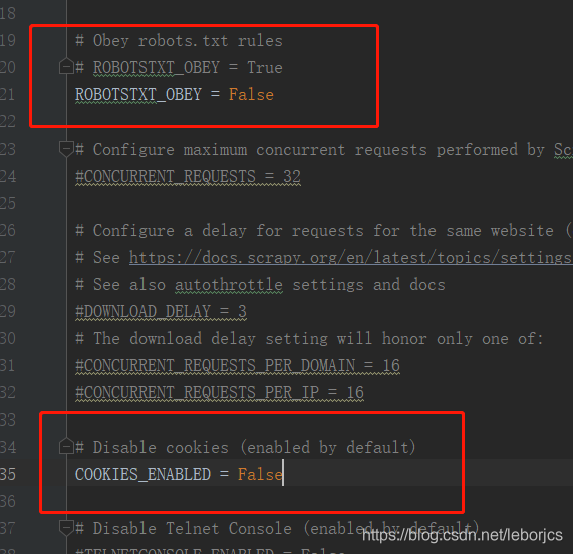
首先修改配置文件setting.py
1.关闭机器人协议
2.取消禁用cookie的功能 ↓↓↓
现在就回到爬虫文件wyySpider.py准备前期的工作
修改start_urls里的网址和准备一个请求头
首先用火狐浏览器打开网易云音乐,登录后进入到个人主页 ↓↓↓
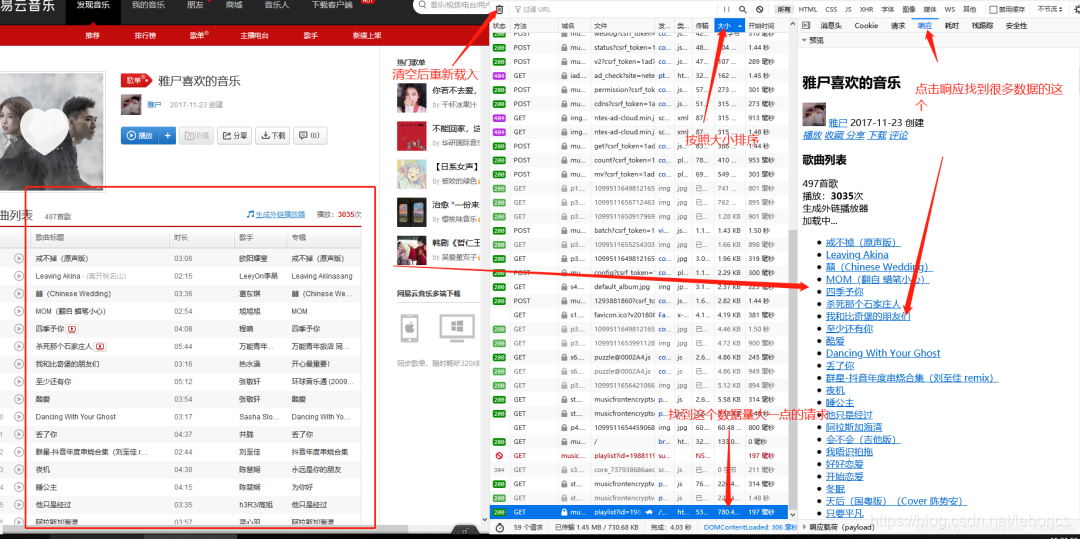
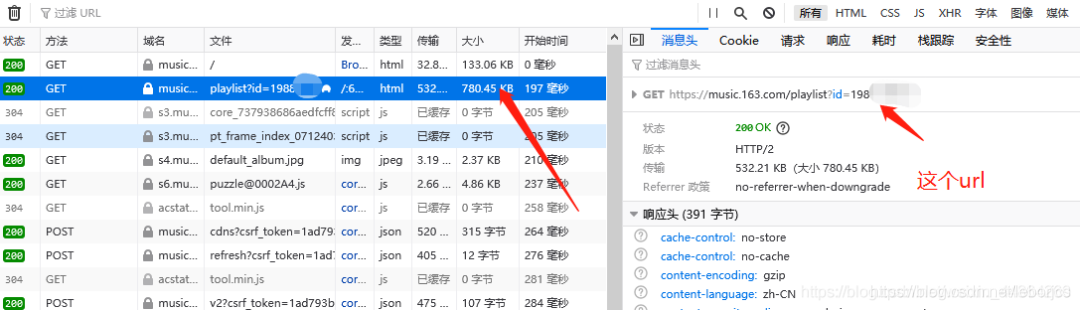
在爬虫代码那里准备一下,修改一下start_urls ↓↓↓
import scrapy
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
class WyyspiderSpider(scrapy.Spider):
name = ‘wyySpider’
allowed_domains = [‘163.com’]
start_urls = [‘https://music.163.com/playlist?id=19xxxxx7’]
先实现一下自动登录功能获取cookie
首先导一下自动化测试的包(Selenium)
没有这个包的话去控制台:pip --default-timeout=100 install selenium -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
导完包还要一个谷歌的驱动程序,先看一下自己的谷歌版本
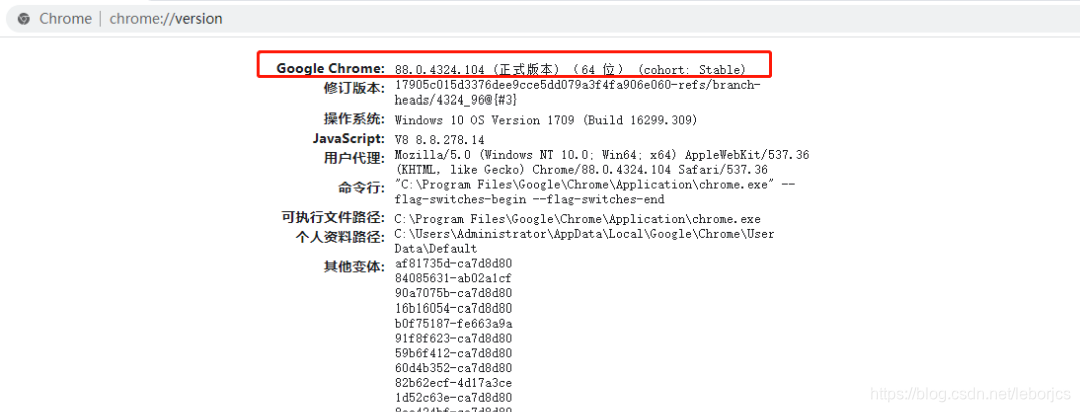
到这网站下载相同版本的驱动程序
:https://sites.google.c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









