



 本文介绍了一种基于Faster-RCNN的红绿灯检测方案,用于无人驾驶汽车在路口的安全行驶。该方案包括数据采集、模型训练及结果发送等环节。
本文介绍了一种基于Faster-RCNN的红绿灯检测方案,用于无人驾驶汽车在路口的安全行驶。该方案包括数据采集、模型训练及结果发送等环节。
0 前言
这是之前做过的一个红绿灯检测的小小实践,现以“软件工程文档”的形式整理以下。只是一个总体的流程,不会面面俱到,介绍太多的细节,有问题的朋友,欢迎交流,也请大神不吝赐教。
1 需求规格说明
在无人驾驶中,路口红绿灯的识别问题十分关键,无人驾驶汽车根据识别的结果采取不同的措施,比如:如果检测到红灯,则在路口等待,直到绿灯亮起后继续行驶;如果检测到绿灯,则直接通过路口。因此,能否准确识别红绿灯的状态,决定着无人驾驶汽车的安全。
鉴于以上需求,需要开发一套红绿灯识别的解决方案,通过摄像头采集图像,然后设计算法对图像进行处理,识别出图像的类别,最后将分类结果发送给决策段进行判断,进而控制无人驾驶汽车的行为。
2 系统设计
2.1 开发环境
硬件开发平台:NVIDIA Jetson TX2
工业相机:AVT GigE
操作系统:Ubuntu 16.04
开发平台:ROS
编程语言:Python
2.2 总体设计
红路灯识别系统主要包括:摄像头数据采集,红绿灯识别,识别结果的发送三个部分。总体框架如下图所示。

2.1 数据采集
首先在硬件开发平台NVIDIA Jetson TX2上安装Ubuntu16.04操作系统,然后安装ROS(Robot Operating System),最后安装AVT GigE的驱动包,此时便可以读取相机采集的图像。
2.2 红绿灯检测
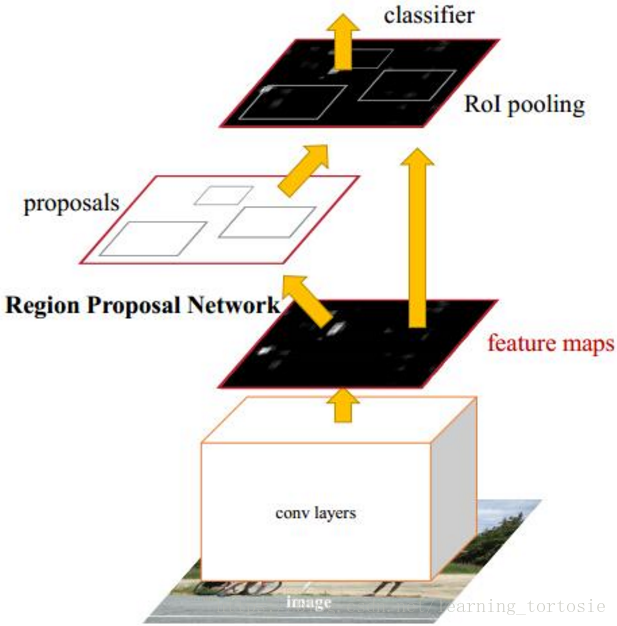
深度学习在计算机视觉领域取得了巨大的成功,其中Faster-RCNN框架具有准确率高等优点,因此本设计采用Faster-RCNN框架对图像进行识别。
Faster-RCNN框架如下图所示,主要步骤依次为:输入图像、生成候选区域、特征提取、分类、位置精修。
红绿灯检测部分主要包括建立数据集、标注、训练模型、测试效果四部分,流程图如下图所示。

首先要建立数据集,来源为在路口不同时刻不同天气下采集的大量图像,以及比赛提供的离线数据,如下图所示为一幅在路口采集的图像。

然后使用工具对数据集进行标注,分为背景、红灯、绿灯三类。
在NVIDIA Jetson TX2上配置深度学习框架Caffe,然后配置Faster-RCNN框架,对一些指定文件进行参数上的修改,使用自己创建的数据集训练模型。
模型训练完成后,输入上图所示的图像进行测试,测试结果如下图所示,程序检测到绿灯及其位置和概率。

2.3 发送识别结果
在本设计中,不同模块间的通信借助ROS完成,红绿灯识别模块将测试结果发布一个话题,决策模块订阅这个话题,这样决策模块就得到了红绿灯识别模块的检测结果。模块间的通信如下图所示。

其中,
talker为红绿灯识别模块的节点,
listener为决策模块的节点,
light_state为
talker节点发布的话题,
listener节点订阅话题
light_state。
3 编程实现
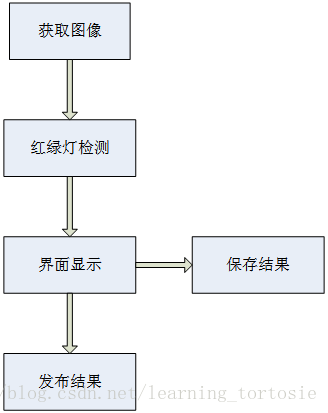
由于需要对摄像头实时采集的图像进行处理,因此使用ROS或OpenCV获取输入的每帧图像,然后将图像输入到红绿灯识别程序,输出识别结果,最后将结果以界面的形式显示出来,并以视频和图片的形式保存,方便调试。这里需要使用OpenCV对文件进行操作。
使用ROS将整个红绿灯识别模块封装成一个节点,检测结果为话题,并将其发布出去,供其他节点订阅。
程序流程如下图所示。
4 集成
集成包括内部模块的集成和与外部其他模块的集成。
内部模块的集成,主要包括实时采集图像,输入到检测模块处理,然后保存结果供调试使用,最后将检测结果发送出去。
与外部模块的集成,即决策模块,是通过ROS完成的,红绿灯识别模块和决策模块分别为两个节点,红绿灯识别节点发布带有检测结果的话题,决策节点订阅这个话题就可以获取检测结果。
5 测试
测试分为离线测试和在线测试。
离线测试为搭建环境,训练模型,编程实现,测试结果,主要是在线测试前的准备过程。
在线测试需要在真实场景下进行实车测试,检验方案的有效性。
写这篇博客时,硬件设备已经上交,而且当初也没留下截图,只好放出在笔记本电脑上运行的截图。
(这也提醒我,做完实验要尽快记录下来)
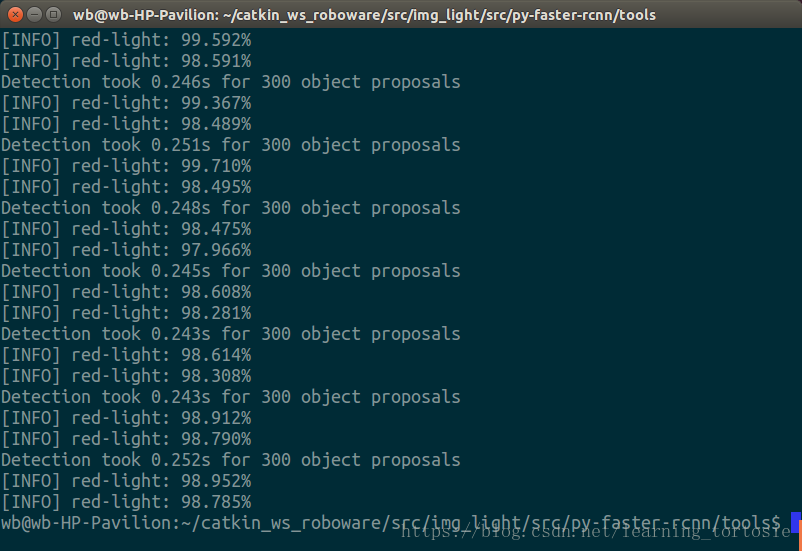
本想插入视频直观地展示效果,然而我用的Markdown格式,试了好多方法都无法插入视频,所以附上链接,也请会在Markdown格式下插入视频的朋友多多指教。
http://player.youku.com/player.php/sid/XMzU0MjQ4MzA0NA==/v.swf
6 维护
此方案主要针对特定地点路口红绿灯的识别问题,如果场景变化,还要重新采集数据集进行训练。
目前版本对GPU依赖较高,同时存在实时性不高的问题,后期会优化模型,使用或研发性能更好的框架进行模型的训练。
附录1 程序源码
由于某种原因,源码暂不公开,有特殊需求的朋友请评论,欢迎交流。
附录2 硬件设备图

现在手头上没有AVT GigE相机,来个微视相机救场吧。


















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









