




本文的思想也是把源图像分别分解为Base和Detai层,然后分别融合。
分别代表什么?-------基础层主要考虑图像的像素强度信息,细节层考虑图像的纹理细节。
本文的手动标注的Mask怎么用的?------设计了一个掩码损失
本文使用了两次GF,将图像分解为一级基础层、二级基础层和细节层,一级基础层的融合使用的基于图像质量和信息熵的熵自适应融合模块
使用了最大绝对值规则来融合二级基础层
对于包含许多纹理和边缘的细节层,我们构建了一个基于掩模引导的深度卷积神经网络来融合它,这里的掩码是在训练集中对IR手动人工标注的、
融合细节层又使用显著掩码分解为前景目标部分和背景部分--------别人都是对源图像做这样的分解
来源:Infrared Physics and Technology 2023 Code
代码公开
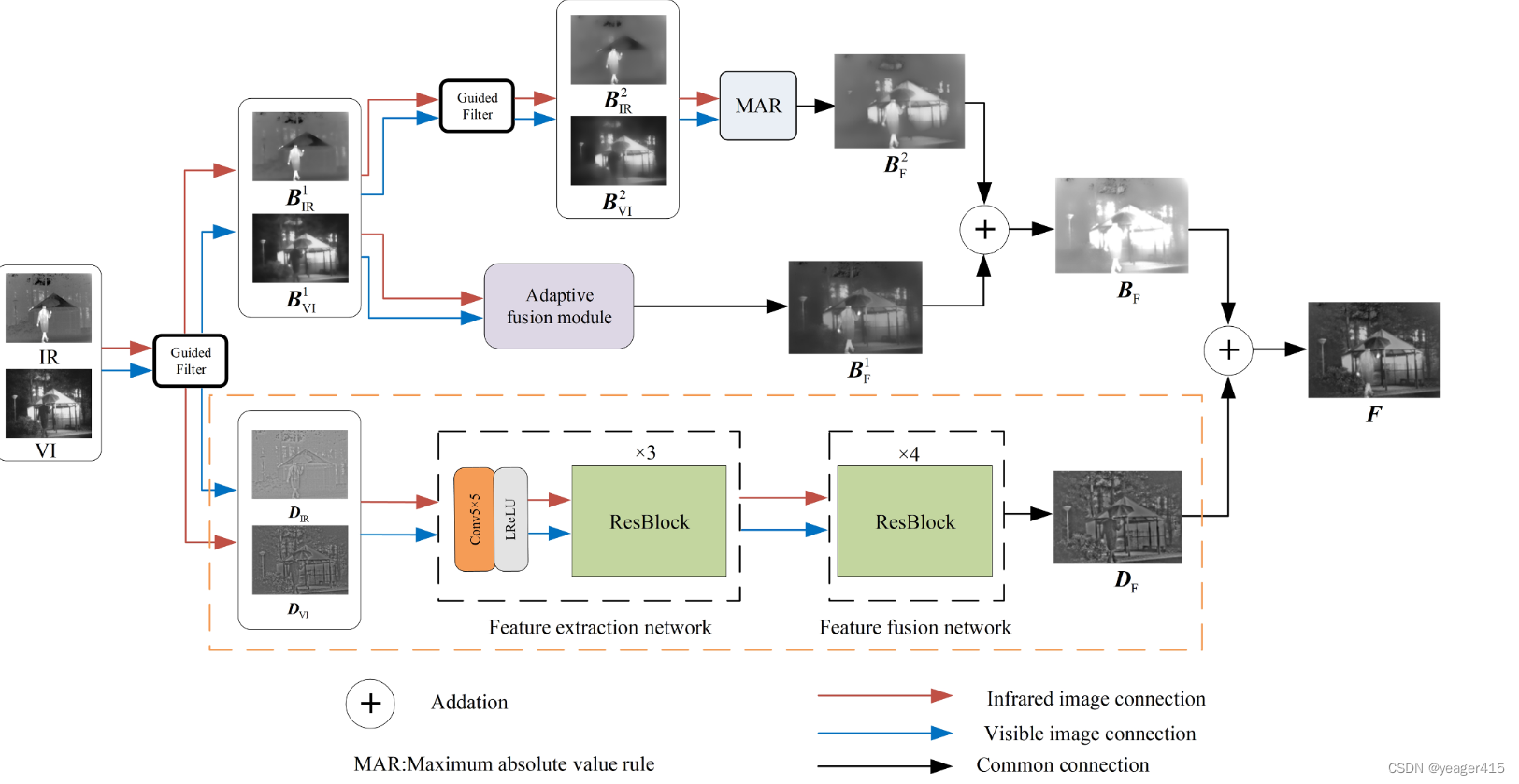
1、怎么分解的?
第一次使用GF得到Base层,源图像减去B就得到Deatil层。
2、Base怎么融合的?
在大多数传统方法中,通常使用平均规则直接融合基础层。在本文中,我们提出根据源图像本身的属性对图像进行自适应融合,并使用深度神经网络进行无参考图像质量评估(IQA)[36]来评估每张图像的质量。IQA分数越高,图像质量越高,模糊和噪点越少。此外,考虑到融合图像应该包含更多的源图像信息,仅依靠IQA无法评估信息的数量。因此,我们使用客观度量熵[37]来度量每个输入图像的平均信息量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









