 Linux 0.11 read()函数剖析
Linux 0.11 read()函数剖析





序
这篇文章带着大家去看linux0.11源码的read函数,大家每天都在读写文件,但是内部的具体流程还是很复杂的,还是从最简单的源码开始看起吧。会讲述一些内核的数据结构,函数调用流程,文件系统等等。
文件系统
linux0.11的文件系统是MINIZX文件系统,包含引导块、超级块、i-node位图、逻辑块位图、i节点与数据区等。如图所示:
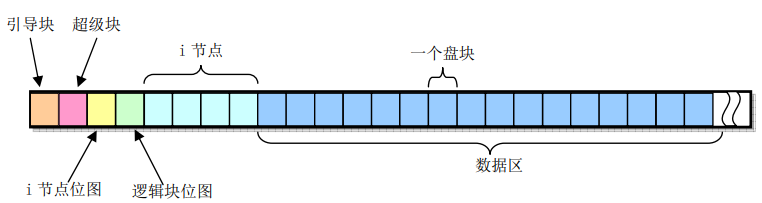
- 引导块就是计算机加电启动时由BIOS自动读入的执行代码和数据,作为引导设备,这篇文章可以忽略
- 超级块用于存储文件系统信息,包括文件系统类型、块大小、块数量、i节点数量、i节点大小、i节点数量、i节点位图大小、逻辑块位图大小、逻辑块大小、逻辑块数量、i节点位图起始块号、逻辑块位图起始块号、根目录i节点号、根目录i节点大小、根目录i节点数量、根目录i节点位图大小、根目录i节点位图起始块号、根目录i节点位图起始块号、根目录i节点位图起始块号
- i节点位图用于记录文件系统中i节点(Inode)的分配状态
- 逻辑块位图用于记录文件系统中数据块的分配状态
- i节点用于存放文件或者目录的元数据,如文件宿主的id,文件所属组id,文件权限,文件大小,文件创建时间等。
- 数据区就是文件的内容
这里比较重要的是i节点的数据结构:
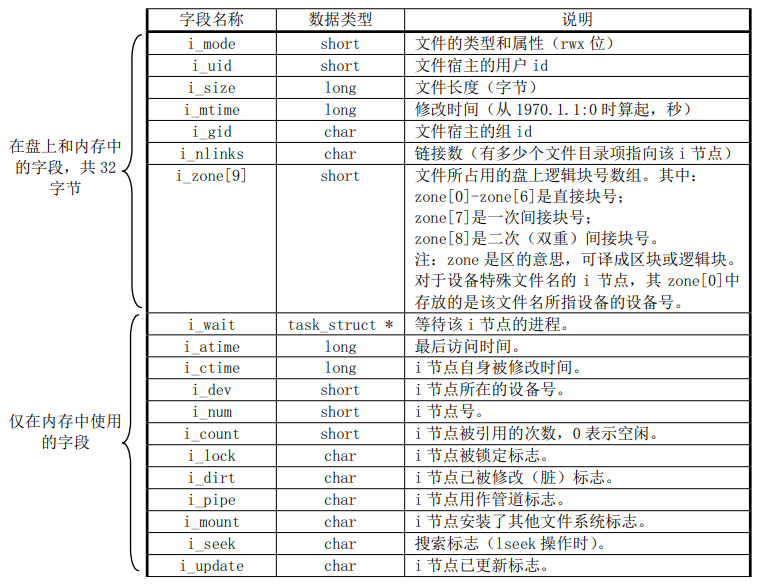
如图所示,分为在内存使用和磁盘内存共用两个部分,当文件被加载或者打开或者进行操作时,会关联一些进程时间等信息,这些都是在内存部分操作,而实际和文件磁盘相关的都是在内存磁盘共用的地方。
有了以上基础,我们进行源码阅读。
源码阅读
sys_read
先找到源码入口
int sys_read(unsigned int fd, char * buf,int count)
{
// ...
}
该函数时平常我们read的入口函数,当我们调用read函数时,会执行系统条用,用户态会切换为内核态,然后就会sys_read函数。
函数参数是fd,buf,count三个参数,fd是文件描述符,在open函数中返回的fd,在该进程中唯一标识一个文件。buf是存放读取数据的缓冲区,count是读取数据的大小。
struct task_struct {
// ...
struct file * filp[NR_OPEN];
// ...
};
这个是表示进程的结构体,filp表示进程打开的文件,NR_OPEN表示进程打开的文件的最大数量。而fd则就是该数组的下标。
继续来看sys_read函数实现:
int sys_read(unsigned int fd, char * buf,int count)
{
if (fd>=NR_OPEN || count<0 || !(file=current->filp[fd]))
return -EINVAL;
if (!count)
return 0;
// ...
}
开始就是判断参数的合法性,并且拿到fd执行的file结构体对象。
struct file {
unsigned short f_mode; // 文件的访问模式,比如读、写或执行权限。
unsigned short f_flags; // 文件标志, ??
unsigned short f_count; // 引用计数,表示当前文件结构被多少个进程共享
struct m_inode * f_inode; // 指向文件的索引节点
off_t f_pos; //文件的偏移量
};
然后继续向下:
int sys_read(unsigned int fd, char * buf,int count)
{
// ...
verify_area(buf,count);
inode = file->f_inode;
if (inode->i_pipe)
return (file->f_mode&1)?read_pipe(inode,buf,count):-EIO;
if (S_ISCHR(inode->i_mode))
return rw_char(READ,inode->i_zone[0],buf,count,&file->f_pos);
if (S_ISBLK(inode->i_mode))
return block_read(inode->i_zone[0],&file->f_pos,buf,count);
if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode)) {
if (count+file->f_pos > inode->i_size)
count = inode->i_size - file->f_pos;
if (count<=0)
return 0;
return file_read(inode,file,buf,count);
}
printk("(Read)inode->i_mode=%06o\n\r",inode->i_mode);
return -EINVAL;
}
首先是对用户传进来的内存区域是否合法,然后判断file的类型,如果是管道类型就去执行read_pipe函数,如果是字符型文件就去执行rw_char函数,如果是块设备文件就去执行block_read。
这里我们关注的是文件的读取,所以会去执行file_read函数。在此之前要先判断从文件的当前偏移(f_pos)加上count的长度是否超过了文件的长度,如果超过了就设定最长读取为文件的长度。
verify_area
我们先去看下verify_area函数,然后再看file_read函数,看一下内核如何验证用户传入的内存是否合法的。
void verify_area(void * addr,int size)
{
unsigned long start;
start = (unsigned long) addr;
size += start & 0xfff;
start &= 0xfffff000;
start += get_base(current->ldt[2]);
while (size>0) {
size -= 4096;
write_verify(start);
start += 4096;
}
}
void write_verify(unsigned long address)
{
unsigned long page;
if (!( (page = *((unsigned long *) ((address>>20) & 0xffc)) )&1))
return;
page &= 0xfffff000;
page += ((address>>10) & 0xffc);
if ((3 & *(unsigned long *) page) == 1)
un_wp_page((unsigned long *) page);
return;
}
verify_area函数开始的几行先将地址对齐,因为他这个是按页(4K大小)来验证的,start += get_base(current->ldt[2])这个让start的地址加上段基址的地址得到线性地址。然后按页来验证该地址是否可写。
然后继续看write_verify函数:
来看线性地址转成物理地址的变换示意图:
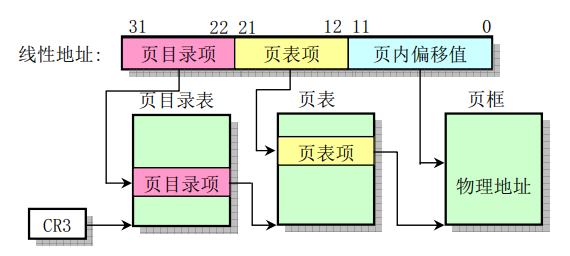
该函数首先把传进来的参数address先右移20位并把后两位置0,然后取这个地址的值判断第一位是否为1,实际他是先移动22位就拿到了页目录项,然后它会在页目录表中计算得到页表地址,但是一个页目录项占用4个字节(指针大小),所以得到的这个值还需要乘以4才是真正的页目录项的地址。所以右移22位再乘以4就是和右移20位再和0xffc做与操作类似。页表的地址的第一位(右起,后边类似表述)表示的是页表是否存在。不存在就直接返回了,因为页表不存在的情况下,对该地址写入操作就会触发缺页异常而去执行,并映射物理页面到该地址。
然后就是获取到页表项的值,然后判断第一位是否是1,第二位是否是0,第一位表示是否存在,第二位表示是否可读写执行(1表示读写执行,0表示读和执行),也就是如果这个页面存在但是只可以读执行就复制该页面供使用,否则就直接返回。
以上我们知道了verify_area函数就是保证用户指定地址的页面可以写,不管是使用缺页异常还是写时复制技巧。本来我们重点不在此,就不深入到这里边的细节了。
file_read
接着我们就回到file_read函数了
int file_read(struct m_inode * inode, struct file * filp, char * buf, int count)
{
int left,chars,nr;
struct buffer_head * bh;
if ((left=count)<=0)
return 0;
while (left) {
if ((nr = bmap(inode,(filp->f_pos)/BLOCK_SIZE))) {
if (!(bh=bread(inode->i_dev,nr)))
break;
} else
bh = NULL;
nr = filp->f_pos % BLOCK_SIZE;
chars = MIN( BLOCK_SIZE-nr , left );
filp->f_pos += chars;
left -= chars;
if (bh) {
char * p = nr + bh->b_data;
while (chars-->0)
put_fs_byte(*(p++),buf++);
brelse(bh);
} else {
while (chars-->0)
put_fs_byte(0,buf++);
}
}
inode->i_atime = CURRENT_TIME;
return (count-left)?(count-left):-ERROR;
}
函数的最开始声明了buffer_head的指针,buffer_head用来管理磁盘数据的缓存,也就是磁盘数据读取到内存中,用buffer_head数据结构管理。
接着代码判断count是否合法,left表示还有多少未读取,初始为count。
然后调用bmap函数,该函数会根据传入的file的inode及文件的偏移,得到这一块(块大小这里是1024)数据在磁盘的逻辑块号。然后就是bread函数将这一块数据读入到内存中,用bh管理。然后迭代left和文件偏移直到left为0。
再然后就是判断是否读取到内存中了数据,如果读取了则使用put_fs_byte函数把内核空间的数据复制到用户空间的缓冲区中。如果没有读取到数据则给用户空间的缓冲区赋值为0。
最后,返回读取的字节数,如果中间读取数据失败就返回error。
bmap
上边我们说到bmap函数,该函数会根据传入的file的inode及文件的偏移,得到这一块(块大小这里是1024)数据在磁盘的逻辑块号。我们也来看下如何实现的:
static int _bmap(struct m_inode * inode, int block, int create)
{
// ...
}
int bmap(struct m_inode * inode,int block)
{
return _bmap(inode,block,0);
}
代码比较多,我们从上到下来看,调用_bmap传入create为0,表示不创建新块,直接返回块号。
然后我们看到block参数是这样赋值传入的(filp->f_pos)/BLOCK_SIZE),也就是这里的block是从文件头开始计算此时偏移所处的块号。
然后我们还得看下inode中如何映射磁盘块(数据)的,如图
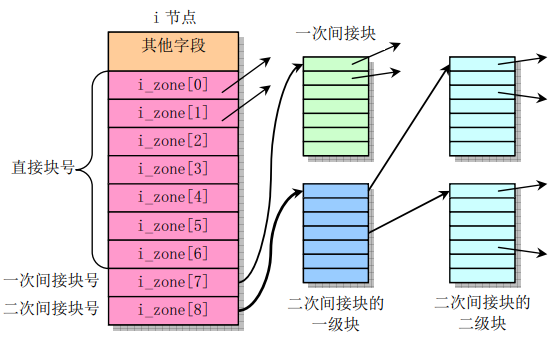
inode使用i_zone数组来映射磁盘的位置,i_zone的0~6项是直接映射磁盘块,7项中映射的磁盘块中存放的是其他磁盘块的块号,称为一次间接块。8项中映射的磁盘块中存放了映射到间接块的块号,称为二次间接块。其中一个磁盘块可以存放512(块号用short存放,1024/2)个指向其他磁盘块的块号。
那也就是说一个文件的inode可以存放7 + 512 + 512 * 512个块。
static int _bmap(struct m_inode * inode, int block, int create)
{
struct buffer_head * bh;
int i;
if (block<0)
panic("_bmap: block<0");
if (block >= 7+512+512*512)
panic("_bmap: block>big");
if (block<7) {
if (create && !inode->i_zone[block])
if ((inode->i_zone[block]=new_block(inode->i_dev))) {
inode->i_ctime=CURRENT_TIME;
inode->i_dirt=1;
}
return inode->i_zone[block];
}
// ...
}
继续看_bmap函数,首先对参数block进行检查,如果block<7,则表示是直接块,直接返回inode->i_zone[block]的值。
static int _bmap(struct m_inode * inode, int block, int create)
{
// ...
block -= 7;
if (block<512) {
if (create && !inode->i_zone[7])
if ((inode->i_zone[7]=new_block(inode->i_dev))) {
inode->i_dirt=1;
inode->i_ctime=CURRENT_TIME;
}
if (!inode->i_zone[7])
return 0;
if (!(bh = bread(inode->i_dev,inode->i_zone[7])))
return 0;
i = ((unsigned short *) (bh->b_data))[block];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block]=i;
bh->b_dirt=1;
}
brelse(bh);
return i;
}
// ...
}
如果block小于7+512,则去读取7号块指向的磁盘块,bh->b_data中存放了读取的内容,进一步从中获取磁盘块的块号。
static int _bmap(struct m_inode * inode, int block, int create)
{
// ...
block -= 512;
if (create && !inode->i_zone[8])
if ((inode->i_zone[8]=new_block(inode->i_dev))) {
inode->i_dirt=1;
inode->i_ctime=CURRENT_TIME;
}
if (!inode->i_zone[8])
return 0;
if (!(bh=bread(inode->i_dev,inode->i_zone[8])))
return 0;
i = ((unsigned short *)bh->b_data)[block>>9];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block>>9]=i;
bh->b_dirt=1;
}
brelse(bh);
if (!i)
return 0;
if (!(bh=bread(inode->i_dev,i)))
return 0;
i = ((unsigned short *)bh->b_data)[block&511];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block&511]=i;
bh->b_dirt=1;
}
brelse(bh);
return i;
}
如果不符合一次间接块,则去二次间接块中寻找,首先读取8号项中指向的磁盘块,拿到了这个磁盘块的数据,继续让block>>9(即除以512)来判断输入那个二次间接磁盘块中,然后再进行一遍读取,并从中获取到块号返回即可。
到这里我们则知道bmap函数是通过计算文件的相对块的块号计算得到实际磁盘的块号。
bread
bread函数是根据磁盘块号读取磁盘数据到内存中,并返回一个buffer_head结构体指针。具体看下函数实现:
struct buffer_head * bread(int dev,int block)
{
struct buffer_head * bh;。
if (!(bh=getblk(dev,block)))
panic("bread: getblk returned NULL\n");
if (bh->b_uptodate)
return bh;
ll_rw_block(READ,bh);
wait_on_buffer(bh);
if (bh->b_uptodate)
return bh;
brelse(bh);
return NULL;
}
看代码先调用getblk从高速缓存中申请一块内存,如果指向该dev/block的有相应的缓冲区,则直接返回了,那么b_uptodate值就为1,也即缓冲区中已经有可用的数据,则直接返回这个bh。
否则要调用ll_rw_block函数去磁盘读取,调用wait_on_buffer来等待读取完成并返回。b_uptodate表示数据有效,当然这里表示数据读取成功了。
ll_rw_block
在看ll_rw_block的函数实现之前,我们先了解下块设备读写的流程及数据结构:
struct blk_dev_struct {
void (*request_fn)(void);
struct request * current_request;
};
struct blk_dev_struct blk_dev[NR_BLK_DEV] = {
{ NULL, NULL }, /* no_dev */
{ NULL, NULL }, /* dev mem */
{ NULL, NULL }, /* dev fd */
{ NULL, NULL }, /* dev hd */
{ NULL, NULL }, /* dev ttyx */
{ NULL, NULL }, /* dev tty */
{ NULL, NULL } /* dev lp */
};
blk_dev_struct用来描述块设备(如硬盘、SSD等)的结构体。因为每次读写设备时,都是构造一个请求,所以我们需要一个请求结构体链表表示,且请求的处理函数使用request_fn的函数指针,不同设备使用不同的函数。
blk_dev是存放所有块设备的数组,我们看到第0项什么也不表示,第一项表示内存设备,第二项表示硬盘设备,第三项表示光驱设备,第四项表示硬盘设备,第五项表示串口设备,第六项表示串口设备。
我们仅仅以硬盘为例,在初始化的时候:
#define MAJOR_NR 3
#define DEVICE_REQUEST do_hd_request
void hd_init(void)
{
blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST; // do_hd_request()
set_intr_gate(0x2E,&hd_interrupt);
outb_p(inb_p(0x21)&0xfb,0x21);
outb(inb_p(0xA1)&0xbf,0xA1);
}
这一段代码的意思就是设定硬盘设备的请求处理函数是do_hd_request, 对于硬盘的中断处理程序hd_interrupt。
然后我们再去看ll_rw_block的函数实现,并假设我们的文件在硬盘上:
void ll_rw_block(int rw, struct buffer_head * bh)
{
unsigned int major;
if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||
!(blk_dev[major].request_fn)) {
printk("Trying to read nonexistent block-device\n\r");
return;
}
make_request(major,rw,bh);
}
最开始是对参数的校验,然后是去构造一个request,这里使用主设备号来表示是硬盘。也就是3。
static void make_request(int major,int rw, struct buffer_head * bh)
{
struct request * req;
int rw_ahead;
// ...
repeat:
if (rw == READ)
req = request+NR_REQUEST;
/* find an empty request */
while (--req >= request)
if (req->dev<0)
break;
/* if none found, sleep on new requests: check for rw_ahead */
if (req < request) {
if (rw_ahead) {
unlock_buffer(bh);
return;
}
sleep_on(&wait_for_request);
goto repeat;
}
/* fill up the request-info, and add it to the queue */
req->dev = bh->b_dev;
req->cmd = rw;
req->errors=0;
req->sector = bh->b_blocknr<<1;
req->nr_sectors = 2;
req->buffer = bh->b_data;
req->waiting = NULL;
req->bh = bh;
req->next = NULL;
add_request(major+blk_dev,req);
}
篇幅所限,我删掉了一些代码,可以看到从request的队尾开始向前搜索找一个空位用来增加一个request,如果没找到就睡眠等待下次寻找。如果找到设定操作的位置及存放的内存等信息,然后调用add_request添加请求到相应设备的请求链表中:
static void add_request(struct blk_dev_struct * dev, struct request * req)
{
struct request * tmp;
req->next = NULL;
cli();
if (req->bh)
req->bh->b_dirt = 0;
if (!(tmp = dev->current_request)) {
dev->current_request = req;
sti();
(dev->request_fn)();
return;
}
for ( ; tmp->next ; tmp=tmp->next)
if ((IN_ORDER(tmp,req) ||
!IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req,tmp->next))
break;
req->next=tmp->next;
tmp->next=req;
sti();
}
这个函数代码意义就是如果添加进来的request在链表中是第一个请求,current_request赋值给这个request,然后就直接调用request_fn函数。否则还是把这个request插入到链表中。
那么然后就是去看下request_fn函数了,也即do_hd_request函数了:
void do_hd_request(void)
{
int i,r = 0;
unsigned int block,dev;
unsigned int sec,head,cyl;
unsigned int nsect;
// ...从请求链表中取出第一个请求结构体对象
// ...计算要读磁盘的具体位置,柱面、磁头、扇区等
if (reset) {
// ...
return;
}
if (recalibrate) {
//...
return;
}
if (CURRENT->cmd == WRITE) {
// ...
} else if (CURRENT->cmd == READ) {
hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);
} else
panic("unknown hd-command");
}
函数比较复杂,为了了解大体脉络,我也删掉了一些代码,包括计算读磁盘的具体位置,柱面、磁头、扇区等,及当发生复位和重新校准等异常情况的处理等。
然后函数通过调用hd_out针对设备的控制器写入命令,然后这个程序就返回了。我们知道当数据准备好后会触发中断,也就是我们上边所说的hd_interrupt,但是在执行hd_out函数时,我们会把read_intr赋值给do_hd,然后触发中断时hd_interrupt对do_hd调用,也就是当执行读取时就调用read_intr,当执行写入时就调用write_intr。
然后我们到read_intr函数中去:
static void read_intr(void)
{
port_read(HD_DATA,CURRENT->buffer,256);
CURRENT->errors = 0;
CURRENT->buffer += 512;
CURRENT->sector++;
if (--CURRENT->nr_sectors) {
do_hd = &read_intr;
return;
}
end_request(1);
do_hd_request();
}
这里看到我们通过port_read来把硬盘控制器准备好的数据读到内存中,然后看下是不是还有剩下数据没读完,如果没读完就返回,以便于下一次读取。如果读取完了就设定结束请求,然后再次调用do_hd_request,处理下一个请求。
到这里我们对于ll_rw_block的全过程就分析完了,这里书上的解释图:
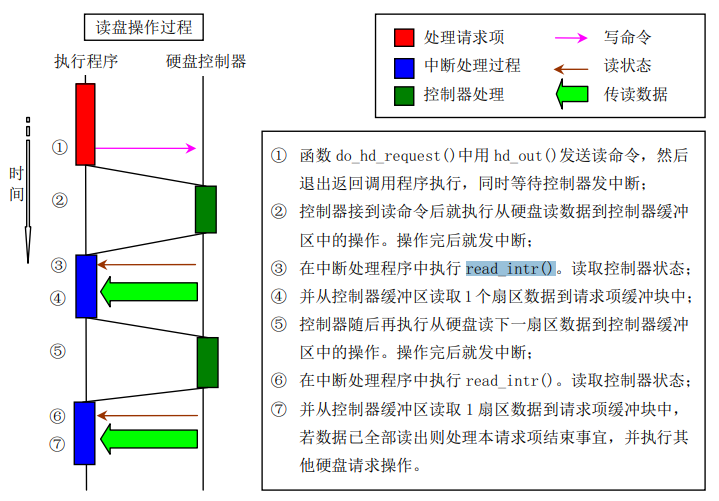
总结
我们这里就对读文件这整个流程做了梳理,内容比较多,感谢大家阅读,里边有很多源码的细则我没有讲到,如果影响你的理解,可以留言探讨。
Ref
《linux内核完全注释》


















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









