






文章目录
引言
在现代计算系统中,并发(Concurrency)与并行(Parallelism)能力是高性能软件的基石。而实现并发的核心,在于对“执行流”的抽象与调度。从早期的多进程模型,到内核线程的普及,再到用户态协程的复兴,操作系统与编程语言不断在资源隔离、切换开销、编程复杂度与硬件利用率之间寻求最优平衡。本文将从硬件基础出发,系统梳理进程、线程、用户级线程与协程四类执行单元的本质特征、实现机制、历史局限及现代演进,并结合 Linux 内核与主流运行时(如 Go、Python)进行深度剖析。
一、底层基础:CPU、中断与上下文切换
要理解所有执行模型,必须首先明确 CPU 如何切换任务。
1. CPU 状态与寄存器上下文
每个执行流在 CPU 上运行时,其状态由一组寄存器体现:
通用寄存器(EAX, EBX, …):存储临时数据。
指令指针(EIP/RIP):指向下一条要执行的指令。
栈指针(ESP/RSP):指向当前栈顶。
段寄存器(CS, SS, …):在 x86 保护模式下定义代码/数据段。
标志寄存器(EFLAGS):记录算术状态(如进位、零标志)。
上下文切换的本质,就是保存当前执行流的寄存器状态,并恢复目标执行流的状态。
2. 内核介入:系统调用与中断
用户态 → 内核态:通过系统调用(syscall)、中断(如时钟中断)或异常(如页错误)触发。
上下文保存:CPU 自动将用户态寄存器压入内核栈,内核调度器再决定是否切换到另一个进程/线程。
开销来源:模式切换、TLB 刷新(进程切换时)、缓存污染。
关键洞察:任何需要内核介入的切换(如进程/内核线程切换)都不可避免地带来微秒级开销;而纯用户态切换可降至纳秒级。
二、进程:强隔离的资源容器
1. 定义与内核结构
在 Linux 中,进程由 task_struct 描述,核心资源包括:
mm_struct:管理虚拟地址空间(页表、VMA 区域)。
files_struct:打开的文件描述符表。
signal_struct:信号处理信息。
独立内核栈:每个进程在内核态有 8KB 独立栈。
2. 创建与切换机制
创建:fork() 通过写时复制(COW)复制父进程地址空间,开销大但安全。
切换:context_switch() 函数执行:
调用 switch_mm() 切换页表(更新 CR3 寄存器)。
调用 switch_to() 汇编宏,保存/恢复寄存器(含 ESP, EIP)。
刷新 TLB(Translation Lookaside Buffer),导致缓存失效。
开销:典型值在 1–10 微秒,随地址空间增大而增加。
3. 适用场景与局限
优势:崩溃隔离、安全沙箱(如 Android 应用、浏览器多进程)。
劣势:通信成本高(需 IPC),创建/切换慢,不适合高频任务。
工程实践:Nginx 采用“多进程 + 共享内存”模型,兼顾隔离与性能。
三、线程:共享地址空间的内核调度单元
1. Linux 中的“线程”本质
Linux 并无独立的“线程”概念。线程是通过 clone() 系统调用创建的特殊进程:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, ...);
CLONE_VM:共享虚拟地址空间。
其他 CLONE_* 标志控制文件描述符、信号处理等资源的共享。
2. 调度与同步
调度:完全由 CFS(Completely Fair Scheduler)管理,可跨 CPU 核心迁移。
同步:依赖 FUTEX(Fast Userspace Mutex)实现高效锁:
无竞争时,纯用户态原子操作。
有竞争时,陷入内核挂起线程。
3. 开销与瓶颈
栈开销:默认 8MB(ulimit -s 可调),限制线程数量(通常 < 10,000)。
切换开销:约 0.5–2 微秒(无 TLB 刷新)。
I/O 阻塞:任一线程阻塞,仅自身被挂起,不影响其他线程。
4. 典型应用
Java Tomcat:每个请求分配一个线程。
多线程渲染引擎(如 Blender)。
注意:线程虽轻于进程,但在 C10K(万级并发)场景下仍显笨重——10,000 个线程需 80GB 虚拟内存(仅栈),且调度器压力剧增。
四、用户级线程:协作式调度的早期尝试
1. 设计动机
1990 年代,内核线程尚未成熟(如 Linux 2.4 之前),或性能不佳。用户级线程库(如 GNU Pth、Java Green Threads)试图在用户空间实现轻量并发。
2. 实现机制
上下文切换:通过 setjmp/longjmp 或汇编直接操作栈指针(ESP)。
调度器:简单的轮转或优先级队列,运行于单一线程内。
I/O 处理:将阻塞 I/O 替换为非阻塞 I/O + select/poll,由调度器代理。
3. 致命缺陷
多核无法利用:内核仅看到一个执行流,无法调度到多核。
阻塞陷阱:若程序员误用阻塞调用(如 sleep()),整个进程挂起。
调试困难:标准调试器(如 GDB)无法感知用户级线程。
4. 历史结局
随着 Linux NPTL(Native POSIX Thread Library)在 2.6 内核引入,1:1 线程模型性能大幅提升,用户级线程彻底退出主流。但其“用户态切换”思想被协程吸收。
五、协程:现代高并发的终极抽象
协程并非新技术(1963 年即提出),但在异步 I/O 与多核时代成为高并发服务的标配。
1. 两种实现范式
(1) 有栈协程(Stackful Coroutine)
原理:为每个协程分配独立栈(通常 2–8KB,可动态伸缩)。
挂起点:可在任意函数调用深度挂起。
切换:保存/恢复完整寄存器上下文(含 ESP)。
代表:Go Goroutine、libco、Boost.Coroutine。
Go 栈管理:初始 2KB 栈,函数调用检测栈溢出,自动分配新栈并复制数据(“栈分裂”或“栈拷贝”)。
(2) 无栈协程(Stackless Coroutine)
原理:复用调用者栈,挂起点必须是顶层函数。
实现:编译器将函数重写为状态机(switch + goto)。
代表:Python async/await、C# async、Rust async。
一、什么是“调用者栈”?
首先明确概念:
在程序执行中,每个线程只有一个栈(即内核分配的线程栈,通常 8MB)。
当函数 A 调用函数 B 时,B 的栈帧(局部变量、返回地址等)会被压入同一个栈中,位于 A 的栈帧之上。
这个由一系列嵌套函数调用形成的、连续的内存区域,就是调用栈(Call Stack)。
“调用者栈”指的就是当前协程所在函数的直接调用者所使用的那个栈帧所在的栈空间。更准确地说,无栈协程自身不分配独立栈,而是借用所在线程的现有调用栈。
二、无栈协程的工作原理:状态机重写
无栈协程的核心思想不是“保存/恢复整个栈”,而是将一个可挂起的函数,编译成一个状态机对象。这个对象保存了函数执行到哪一步(状态)以及局部变量的值(上下文)。
举例:Python async/await
考虑以下代码:
async def foo():
print("1")
await bar()
print("2")
async def bar():
await asyncio.sleep(1)
当调用 foo() 时,Python 并不会为 foo 分配新栈。相反,它会:
创建一个 Coroutine 对象(本质是一个状态机)。
该对象包含:
一个 state 字段(0=未开始, 1=在 await bar() 之后, …)
局部变量(如 foo 中可能有的 x, y)
对 bar() 返回的 Future 的引用
编译器视角(伪代码)
foo 被重写为类似以下结构:
struct foo_state {
int state; // 当前执行到哪一步
int local_x; // 保存局部变量
Future* await_target; // 等待的目标
};
foo_state* foo_resume(foo_state* s) {
switch (s->state) {
case 0:
print("1");
s->await_target = bar(); // 启动 bar
s->state = 1;
return NULL; // 表示挂起
case 1:
// await bar() 已完成
print("2");
s->state = -1; // 结束
return s;
}
}
关键点:整个 foo 的执行状态被“扁平化”为一个结构体,不再依赖函数调用栈的深度。
三、为什么“挂起点必须是顶层函数”?
这句话的准确含义是:await(或 yield)表达式不能出现在嵌套的内部函数中,除非该内部函数本身也是协程。
场景 1:合法(顶层挂起)
async def outer():
await inner() # 合法:outer 是协程,await 在其顶层
await 发生在 outer 函数体的直接作用域内。
编译器可以将 outer 重写为状态机,await 点对应一个状态切换。
场景 2:非法(非顶层挂起)
def inner(): # 普通函数
await asyncio.sleep(1) # 语法错误!await 不能在普通函数中使用
async def outer():
inner() # 即使 outer 是协程,inner 内部也不能 await
场景 3:合法(嵌套协程)
async def inner():
await asyncio.sleep(1) # 合法:inner 自身是协程
async def outer():
await inner() # 合法:outer 挂起等待 inner 完成
这里 outer 并没有在 inner 内部挂起,而是outer 挂起,等待 inner 这个协程对象完成。
inner 有自己的状态机,与 outer 独立。
无栈协程无法做到这一点,因此禁止在非协程函数中挂起,确保所有挂起点都处于可被编译器“扁平化”为状态机的位置。
四、对比:有栈 vs 无栈
特性
有栈协程(Stackful)
无栈协程(Stackless)
栈分配
为每个协程分配独立栈
复用线程栈
挂起点位置
任意函数调用深度
仅限协程函数的顶层
实现复杂度
高(需管理栈内存)
低(编译器转换)
内存开销
较高(每个栈 KB 级)
极低(仅状态机对象)
语言支持
Go, C++20 (with allocator)
Python, C#, Rust, JS (async)
五、总结
“复用调用者栈,挂起点必须是顶层函数”的本质是:
无栈协程没有自己的栈,它依赖所在线程的现有栈。
为了能在挂起后安全恢复,编译器必须能将整个协程函数转换为一个状态机。
这要求所有挂起操作(await/yield),这样编译器才能在函数入口处插入状态机逻辑。
若允许在嵌套的普通函数中挂起,将导致栈帧被“切片”,无法安全恢复,因此被语言设计禁止。
理解这一点,就能明白为何 Python、Rust 等语言的 async fn 必须显式声明,且 await 只能在 async 函数内部使用——这是无栈协程模型在安全性与性能之间做出的必然约束。
2. 调度模型演进
(1) 单线程协程(M:1)
所有协程运行于一个内核线程。
优点:切换最快,无锁。
缺点:无法利用多核;一个协程 CPU 密集计算会阻塞全部。
适用:I/O 密集型(如 Node.js)。
(2) 多线程协程(M:N)
多个协程(M)映射到多个内核线程(N)。
代表:Go 的 GMP 模型:
G(Goroutine):协程。
M(Machine):内核线程。
P(Processor):逻辑处理器,持有 G 的本地队列。
调度:工作窃取(work-stealing)实现负载均衡。
优势:兼具高并发与多核并行。
3. I/O 集成:异步运行时的核心
协程必须与异步 I/O 框架深度绑定:
Linux:基于 epoll(边缘触发)或 io_uring(零拷贝异步 I/O)。
Go:网络 I/O 由 netpoller 管理,goroutine 在 read 时挂起,epoll 事件触发后恢复。
Python:asyncio 事件循环驱动 Future/Task。
关键区别:
用户级线程试图“隐藏”I/O 阻塞,而协程显式将阻塞转化为挂起,使控制流清晰可控。
4. 性能与规模
切换开销:50–200 纳秒(纯用户态寄存器操作)。
内存占用:Go Goroutine 初始栈仅 2KB,百万级并发内存 < 2GB。
吞吐量:单机可轻松处理 100,000+ 并发连接(如 Discord 用 Go 支撑 5M 用户)。
六、四者对比与工程选型指南
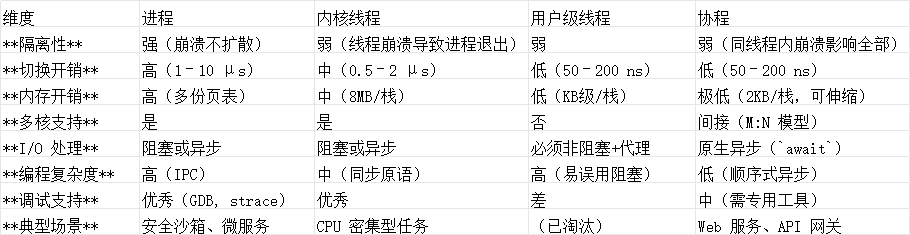
工程选型建议:
强安全隔离:多进程(如 Chrome、PostgreSQL)。
CPU 密集型计算:内核线程池(如视频编码、科学计算)。
高并发 I/O 服务:协程(Go、Rust async)。
混合架构:Nginx(多进程) + 内部线程池 + 异步 I/O。
七、未来趋势:统一与融合
现代系统不再局限于单一模型,而是混合使用:
Linux 新特性:io_uring 提供真正的内核级异步 I/O,可与协程结合,进一步降低延迟。
语言运行时:Go、Java Loom(虚拟线程)、.NET 均在探索“轻量线程”模型,模糊线程与协程边界。
硬件支持:Intel CET(控制流增强技术)可防止栈溢出攻击,为有栈协程提供硬件级安全。
终极目标:提供高吞吐、低延迟、强隔离、易编程的统一并发抽象。
结语
从进程到协程的演进,是一部不断降低抽象开销、提升硬件利用率、简化并发编程的历史。理解其底层机制——寄存器上下文、栈管理、调度策略、I/O 模型——是每一位系统程序员的必修课。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











