




 本文详细介绍了在CentOS 7.4环境下手动部署Hadoop集群的过程,包括环境初始化、SSH免密配置、JDK安装、Hadoop配置及分布式集群启动等关键步骤。
本文详细介绍了在CentOS 7.4环境下手动部署Hadoop集群的过程,包括环境初始化、SSH免密配置、JDK安装、Hadoop配置及分布式集群启动等关键步骤。
目的:新项目的一个测试环境,需要手动部署集群,由于之前都是用ambari进行部署,好久没有手动了,因此借此机会整理下部署文档,方便以后查看
环境信息
[root@test-01 ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
| 主机名 | IP | 部署内容 |
|---|---|---|
| test-01 | 172.18.0.1 | NameNode、SecondaryNameNode、ResourceManager |
| test-02 | 172.18.0.2 | NodeManager、DataNode |
| test-03 | 172.18.0.3 | NodeManager、DataNode |
部署前提
1、环境初始化(各个节点执行)
包括句柄数,调参
echo -e '* soft nofile 102400\n* hard nofile 102400\n* soft nproc 102400\n* hard nproc 102400' >> /etc/security/limits.conf
2、更改主机名并配置hosts文件
因为之前其他环境部署过ansible,因此此步骤使用ansible直接执行,过程略
更改后/etc/hosts为:
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.18.0.1 test-01
172.18.0.2 test-02
172.18.0.3 test-03
3、配置SSH免密
a.新建用户组(各个节点执行)
groupadd hadoop
b.新建hdfs用户,其中需设定userID<1000
useradd -u 501 hdfs -g hadoop
c.并使用passwd命令为新建用户设置密码
passwd hdfs 输入新密码
d.用户建好后,用id user命令查看用户信息如下所示
[root@test-01 /tmp]# id hdfs
uid=501(hdfs) gid=1002(hadoop) groups=1002(hadoop)
e.配置root、hdfs免密
以hdfs用户为例配置免密登录:
- 分别在master和worker上执行
ssh-keygen -t rsa
执行完命令后 在/home/hdfs/.ssh目录下生成如下两个文件
id_rsa 私钥文件
id_rsa.pub 公钥文件
- 分别在master和worker上执行以下命令
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub ${ip}
其中,如果在test-01上执行,则写test-02节点对应的ip
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub 172.18.0.1
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub 172.18.0.2
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub 172.18.0.3
- 验证是否配置成功
ssh hdfs@test-01
ssh hdfs@test-02
ssh hdfs@test-03
继续为root用户配置免密,步骤略
4、安装jdk
此步骤依然使用ansible进行部署,jdk版本为
[root@test-01]#java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
下载Hadoop并安装(主节点)
cd /opt
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
#下载后解压
tar xf hadoop-2.7.2.tar.gz
配置hadoop-env.sh中jdk信息
cd /opt/hadoop-2.7.2/etc/hadoop
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# echo $JAVA_HOME
/opt/java
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/opt/java
为了方便我们以后开机之后可以立刻使用到Hadoop的bin目录下的相关命令,可以把Hadoop的环境变量加到/etc/profile.d/下
[root@test-01 /etc/profile.d]# cat hadoop.sh
export HADOOP_HOME=/opt/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
使得命令配置信息生效,是否生效可以通过
source /etc/profile.d/hadoop.sh
#查看
hadoop version
配置Hadoop分布式集群(主节点)
在hadoop安装目录下创建四个文件夹
mkdir -p current/tmp hdfs hdfs/data hdfs/name
其中:
目录current/tmp,用来存储临时生成的文件
目录/hdfs,用来存储集群数据
目录hdfs/data,用来存储真正的数据
目录hdfs/name,用来存储文件系统元数据
配置hadoop文件
1、修改core-site.xml
cd /opt/hadoop-2.7.2/etc/hadoop/
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim core-site.xml
<!-- 添加以下内容 -->
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://test-01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.2/current/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
变量fs.defaultFS保存了NameNode的位置,HDFS和MapReduce组件都需要它。这就是它出现在core-site.xml文件中而不是hdfs-site.xml文件中的原因。
2、修改mapred-site.xml
默认没有mapred-site.xml文件,需要从模板复制一份
cp mapred-site.xml.template mapred-site.xml
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim mapred-site.xml
<!--添加如下内容-->
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>test-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>test-01:19888</value>
</property>
3、修改hdfs-site.xml
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim hdfs-site.xml
<!--添加如下内容-->
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.2/hdfs/name</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.2/hdfs/data</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>test-01:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
PS:变量dfs.replication指定了每个HDFS数据块的复制次数,即HDFS存储文件的副本个数.我的实验环境只有一台Master和两台Worker(DataNode),所以修改为2。
4、配置yarn-site.xml
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim yarn-site.xml
<!--添加如下内容-->
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>test-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>test-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>test-01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>test-01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>test-01:8088</value>
</property>
5、修改slaves内容
将localhost修改成 test-02、 test-03
[root@test-01 /opt/hadoop-2.7.2/etc/hadoop]# vim slaves
test-02
test-03
分发hadoop目录(主节点)
将配置好的hadoop目录分发的其他节点上
cd /opt/
rsync -av hadoop-2.7.2 root@test-02:/opt
rsync -av hadoop-2.7.2 root@test-03:/opt
启动hadoop分布式集群(主节点)
1、在主节点上格式化集群的文件系统
hadoop namenode -format
2、启动集群
cd /opt/hadoop-2.7.2/sbin
[root@test-01 /opt/hadoop-2.7.2/sbin]# ./start-all.sh
3、查看各个节点的进程
jps
可以看到
#test-01:
SecondaryNameNode
NameNode
ResourceManager
#test-02:
DataNode
NodeManager
#test-03:
DataNode
NodeManager
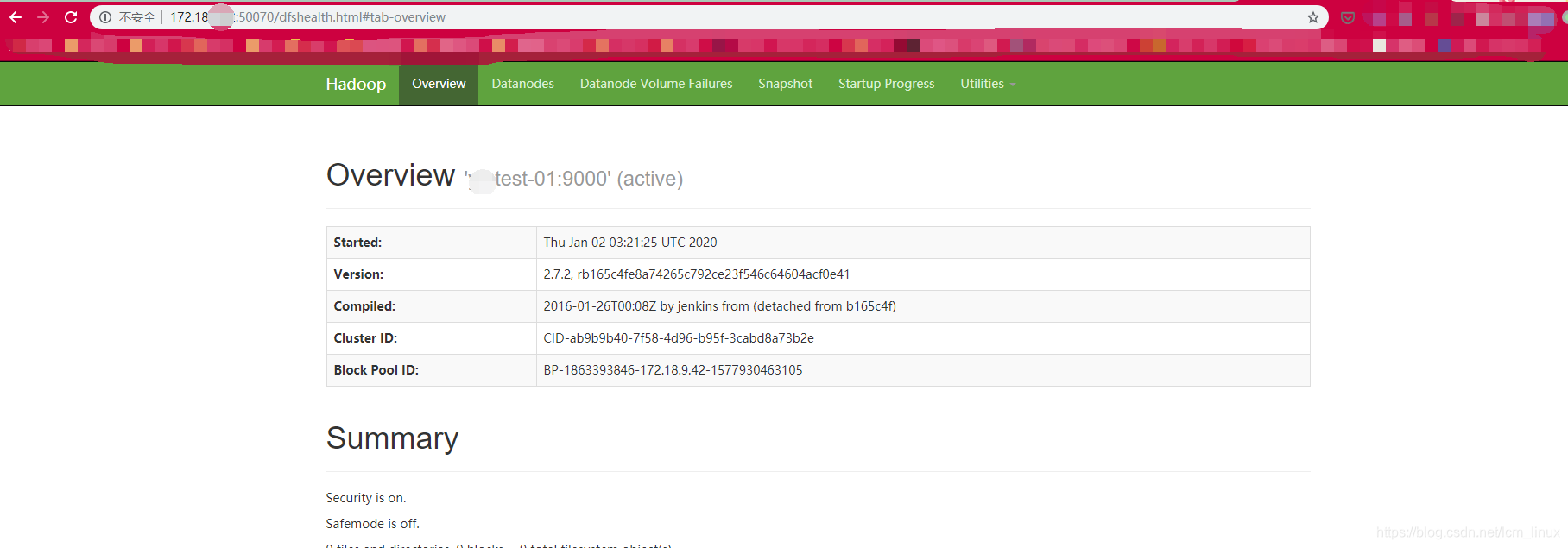
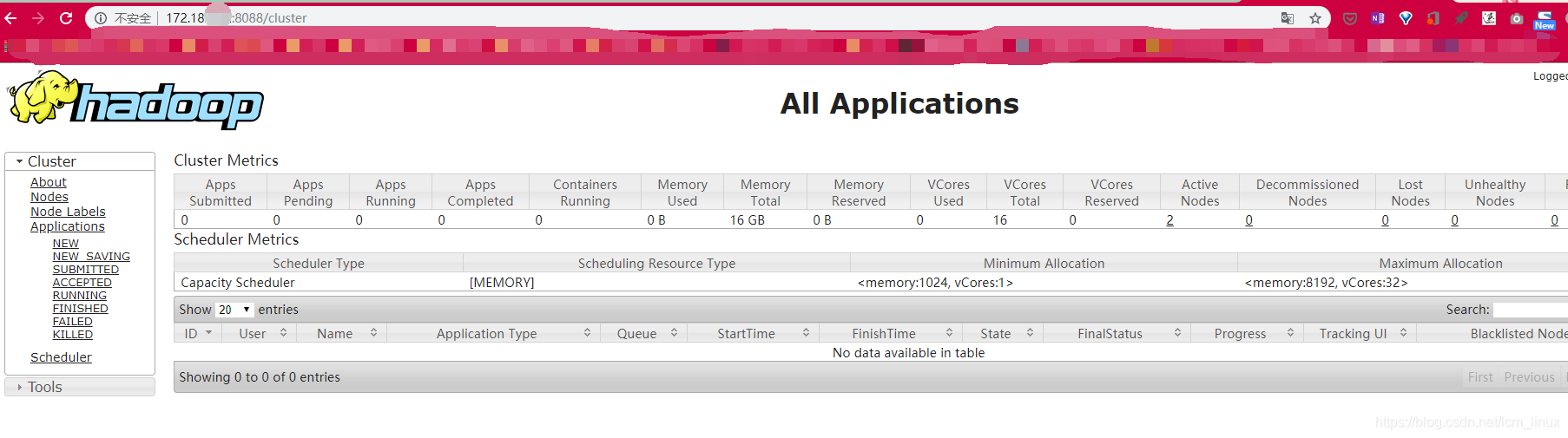
此时分布式的hadoop集群已经搭好了
在浏览器输入:
172.18.0.1:50070
172.18.0.1:8088

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









