







 这篇博客介绍了催收评分卡的制作方法,包括观察期和表现期的选择、数据集划分、变量选取与处理、建模等步骤。强调了时间切片变量衍生的复杂性、变量穿越的避免以及分箱策略的重要性。最后提到了模型调参和催收策略的影响。
这篇博客介绍了催收评分卡的制作方法,包括观察期和表现期的选择、数据集划分、变量选取与处理、建模等步骤。强调了时间切片变量衍生的复杂性、变量穿越的避免以及分箱策略的重要性。最后提到了模型调参和催收策略的影响。
催收评分卡分为滚动率模型、还款率模型和失联模型,市面上介绍C卡的模型较少,本人将收集到的贷后催收评分卡的视频教程整理列举如下:
- 小象学院金融信贷评分卡中的机器学习模型第七课
https://www.bilibili.com/video/BV1pJ411y7yA?p=7- 番茄风控大数据催收评分卡(推荐)
https://www.bilibili.com/video/BV1ZE411V7Mk/
观察期和表现期
本次催收评分卡是M1滚动率模型,即预测当前处于M1状态的用户在本周期内回收(出催)的概率。
贷后催收评分卡需要不断积累建模样本,所以前期通常会制定一些贷后缓催策略,后期积累了一定样本之后再用评分卡来实现更精细化的切分。关于催收评分卡的观察期和表现期,大致有以下3种做法(假定观察期为6个月,表现期为2个月):

第一种:锁定观察期
观察期为放款之后的前6个月,表现期为第7、8个月,也就是将mob账龄锁定。这种方法的观察点为第六期期末的时间,会因为放款月的不同在不断移动,但是观察期+观察点为账龄的前6期。
一般C卡要包含完整的年度数据,即观察点至少需要包含3月、6月、9月、12月四个时间节点,因此这种情况下至少要有18个月的样本数据。
第二种:锁定表现期
表现期锁定为某两个月,比如2020年3月和4月。建模样本则为截止2020年3月账龄大于6期的所有样本。放款月越早,观察点所处的mob就越大。观察期可以取最近6期,也可以取2020年3月之前的所有账期。
第三种:观察期和表现期都在移动
这种方法就是将每一个订单6期之后的数据按账单日拆分成多条,比如一个用户的还款表现为"FFFFFF1212",那么入模的样本就会有"FFFFFF12"和"FFFFFF1212"两条。前面一条的观察期为前6期,表现期为第7、8期;后一条观察期为前8期,表现期为第9、10期,以此类推。这种方法可以扩充建模样本数量,但是X变量的衍生会比较复杂。
本文将采用第三种方法进行评分卡制作,第三种方法的难点在于X变量的衍生。
数据集划分
数据集划分为训练集、测试集、跨时间验证集(5:3:2)。训练集进行模型训练,如果需要进行调参的话还需要对训练集进行切分,划分成训练集和验证集。测试集用于查看模型的泛化能力。跨时间验证集则是监控随着时间变化对模型的预测效果产生的影响。
这里注意一点,分箱的过程应该是基于训练集进行,然后将跨时间验证集的数据根据分箱结果进行映射。之前为了省事直接在数据集上进行分箱,然后再根据放款月份取训练集和跨时间验证集,这样会造成模型过拟合。
变量选取
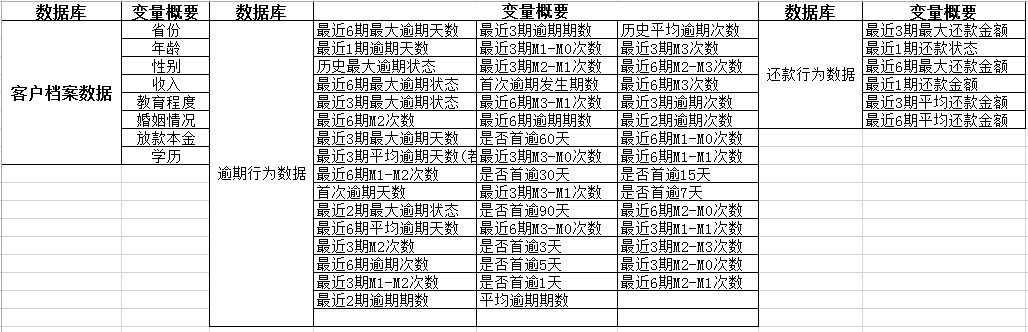
贷后催收评分卡常用到的变量有催收行为数据、逾期行为数据、历史还款数据、客户档案数据以及第三方数据。
催收行为数据:
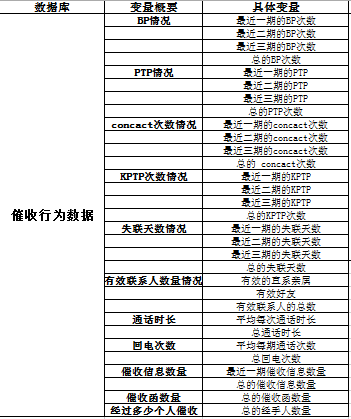
历史还款数据:
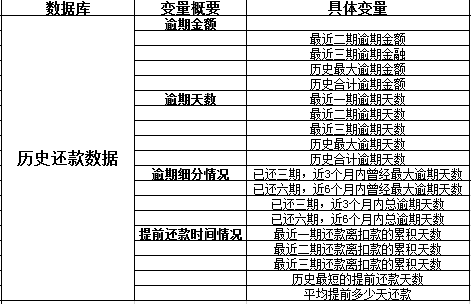
客户档案数据:
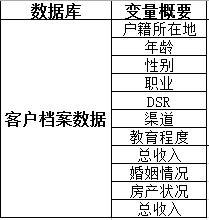
第三方数据:
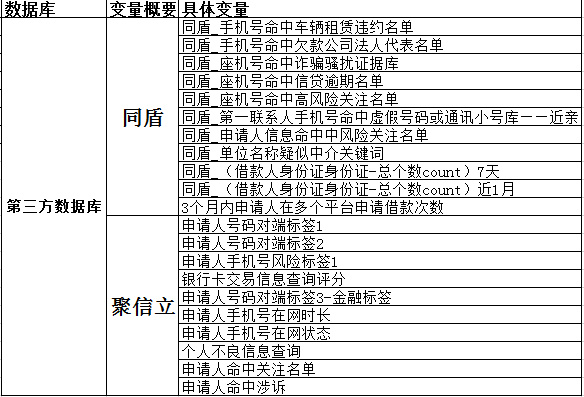
以上是番茄风控老骑士的催收评分卡课程中用到的变量,仅供参考。
以下是结合公司实际数据情况,用到的评分卡变量,主要用到mob表和还款计划表,基于这两张表进行变量的衍生。
特征衍生是催收评分卡制作过程中的重中之重了,一般会衍生很多时间切片变量,反映借款人最近一段时间内的还款能力和意愿。相对于前两种观察期和表现期的取法,一种是固定账龄mob,一种是固定表现月,这两种方法取时间切片变量的时候都相对比较容易。如果是观察期和表现期都不固定的这种,特征衍生的过程会复杂一点。
时间切片变量衍生
首先,会计算出截止每一期的账单日的还款历史状态。大概情况如下:
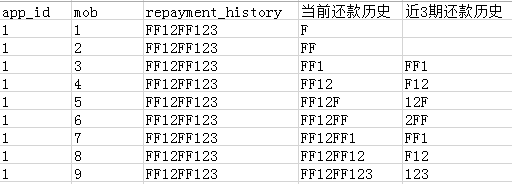
对每一行的repayment_history取长度等于mob的位数就可以得到当期的还款历史字段,然后就可以继续衍生当期而言的近3期、近6期的逾期行为变量。这里只能衍生逾期状态的行为变量,如果需要衍生逾期天数的行为变量,需要根据还款计划表进行计算。
首先,根据还款计划表计算每一期的逾期天数,如果至今未还的话就用当前时间代替。然后衍生一个类似于还款历史的字段,只不过是逾期天数组合成的字段。后面的操作就和逾期状态的处理一样了。
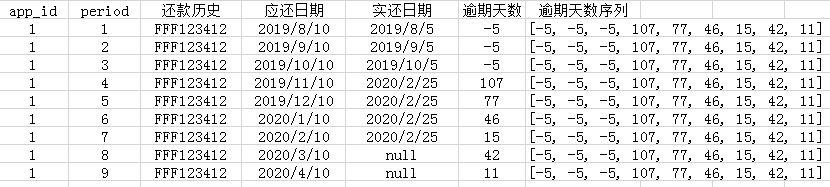
同理,还款金额的时间切片变量也可以这样衍生。
# 生成逾期天数的List
overdue_dict=(df_all.groupby('app_id')['overdue_days'].apply(lambda x:list(x))).to_dict()
df_all['overdue_days_list']=df_all['app_id' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









