





LLM令人兴奋的技术特点之一是,它能够为完全相同的提示词生成不同的响应。每当LLM需要生成一个词元时,它都会为每个可能的词元分配一个可能性分数。如图-1所示,在句子“I am driving a…”(我正在开……)中,a后面接词元car(车)或truck(卡车)的可能性通常比接词元elephant(大象)要大。然而,生成elephant的可能性仍然存在,只是要小得多。
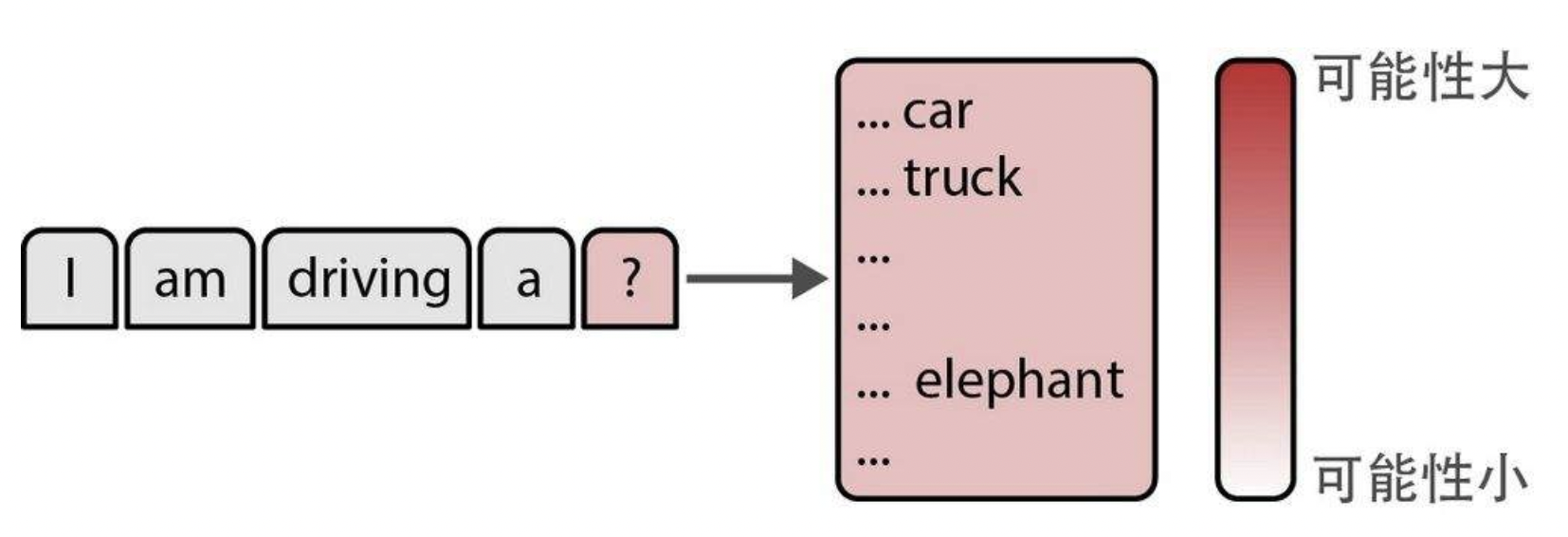
图-1 模型根据可能性选择下一个要生成的词元
temperature参数
temperature(温度)决定生成文本的随机性或创造性。它定义了选择本来不太可能出现的词元的概率。其基本原理是,temperature为0时每次都会生成相同的响应,因为它总是选择可能性最大的词。如图-2所示,较高的temperature值允许生成可能性更小的词。
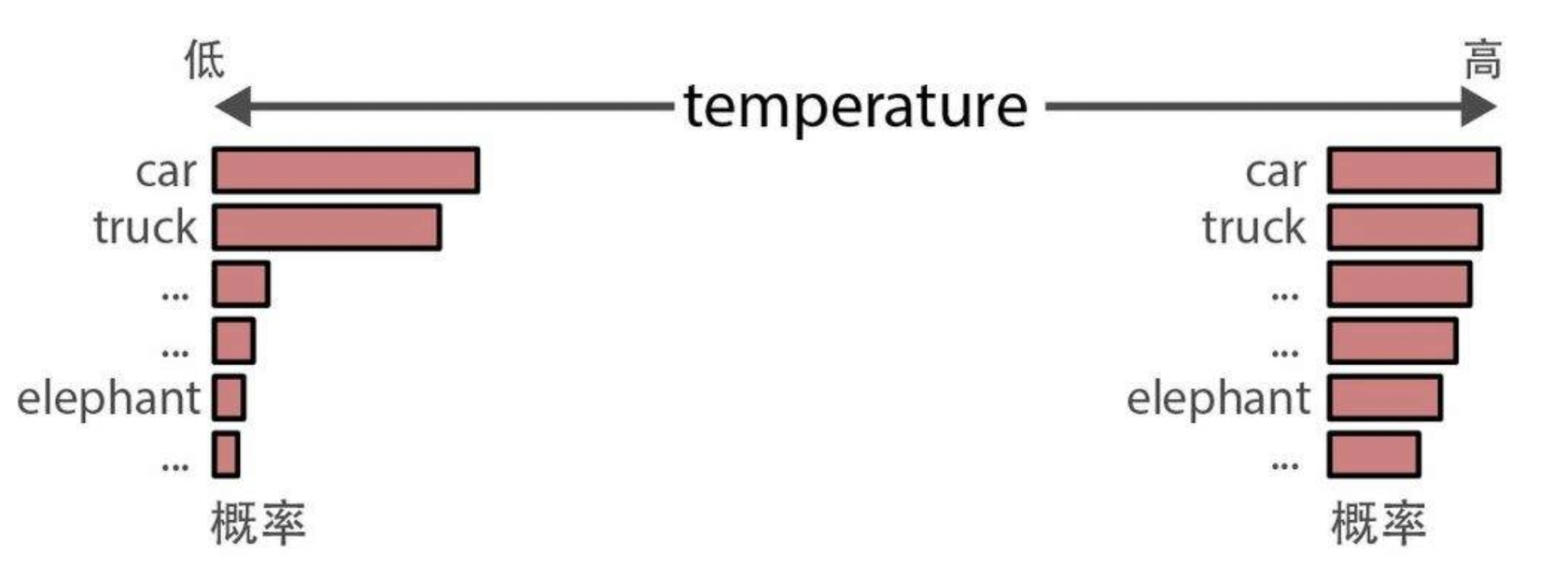
图-2
因此,较高的temperature(如0.8)通常会产生更多样化的输出,而较低的temperature(如0.2)会产生更具确定性的输出。
top_p参数
top-p采样,也称为核采样(nucleus sampling),是一种控制LLM可以考虑哪些词元子集(核)的采样技术。它会考虑概率最高的若干词元,直到达到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6875
6875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









