 CUDA编程并行化向量加法练习
CUDA编程并行化向量加法练习





近年来,随着人工智能的发展,“卖铲人”NVIDIA在人工智能行业的地位越来越重要。CUDA编程也是人工智能重要知识点,本系列通过学习三章文章对CUDA编程有个快速理解和入门:第一章介绍基础知识点,理解CUDA编程基础概念;第二章通过2个简单程序的编程、编译和执行对CUDA编程有个初步掌握;第三章通过CUDA并行编程的实操掌握入门。
介绍
第二章中,我们仅使用一个 GPU 线程在 CUDA 中实现了向量加法。然而,GPU 的优势在于其强大的并行性。在本章中,我们将探索如何利用 GPU 并行性。并行
CUDA 使用内核执行配置<<<...>>>来告诉 CUDA 运行时在 GPU 上启动多少个线程。CUDA 将线程组织成一个称为“thread block”的组。内核可以启动多个线程块,这些线程块被组织成一个“grid”结构。内核执行配置的语法如下
<<< M , T >>>
这表明内核以M线程块网格启动。每个线程块都有T并行线程。
练习 1:使用多线程并行化向量加法
在本练习中,我们将使用具有 256 个线程的线程块并行化第2章中的向量加法[vector_add.cu]。新的内核执行配置如下所示。vector_add <<< 1 , 256 >>> (d_out, d_a, d_b, N);
CUDA 提供了用于访问线程信息的内置变量。在本练习中,我们将使用其中两个:threadIdx.x和blockDim.x。
- threadIdx.x包含块内线程的索引
- blockDim.x包含线程块的大小(线程块中的线程数)。
对于vector_add()配置,的取值范围threadIdx.x是0至255,的值为blockDim.x256。
并行化理念
回顾单线程版本内核[vector_add.cu]。请注意,我们对vector_add()内核进行了一些修改,以便于解释。__global__ void vector_add(float *out, float *a, float *b, int n) {
int index = 0;
int stride = 1
for(int i = index; i < n; i += stride){
out[i] = a[i] + b[i];
}
}
在此实现中,只有一个线程通过遍历整个数组来计算向量加法。使用 256 个线程,加法可以分散到各个线程并同时计算。
对于k第 - 个线程,循环从k第 - 个元素开始,并以 256 次循环遍历数组。stride例如,在第 0 次迭代中,k第 - 个线程计算第 - 个元素的加法k。在下一次迭代中,k第 - 个线程计算第 - 个元素的加法(k+256),依此类推。下图显示了该想法的说明。

练习:尝试在vector_add_thread.cu
- 复制vector_add.cu到vector_add_thread.cu
$> cp vector_add.cu vector_add_thread.cu
- vector_add()使用具有 256 个线程的线程块进行并行化。
- 编译并分析程序
$> nvcc vector_add_thread.cu -o vector_add_thread
$> nvprof ./vector_add_thread
表现
以下是 Tesla M2050 的分析结果==6430== Profiling application: ./vector_add_thread
==6430== Profiling result:
Time(%) Time Calls Avg Min Max Name
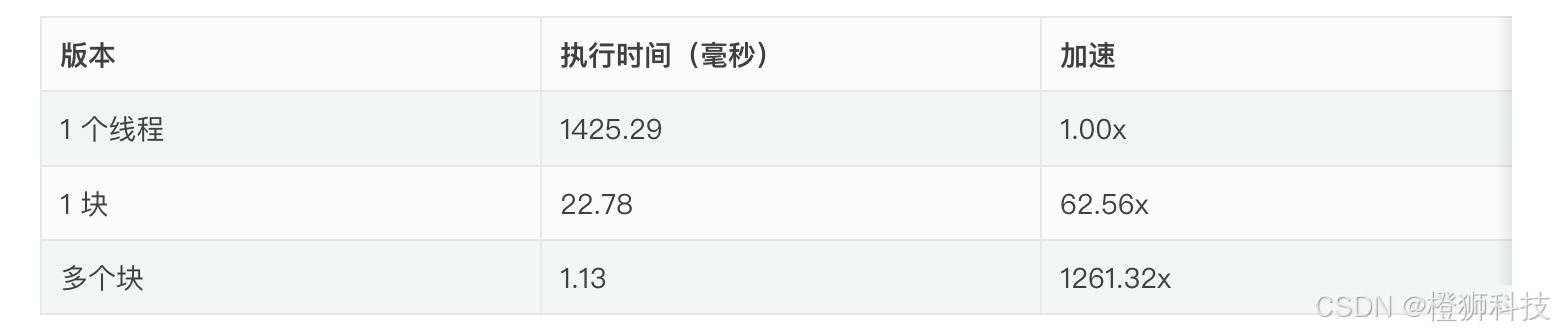
39.18% 22.780ms 1 22.780ms 22.780ms 22.780ms vector_add(float*, float*, float*, int)
34.93% 20.310ms 2 10.155ms 10.137ms 10.173ms [CUDA memcpy HtoD]
25.89% 15.055ms 1 15.055ms 15.055ms 15.055ms [CUDA memcpy DtoH]
练习 2:添加更多线程块
CUDA GPU 具有多个并行处理器,称为流式多处理器或SM。每个 SM 由多个并行处理器组成,可以运行多个并发线程块。要充分利用 CUDA GPU,内核应使用多个线程块启动。本练习将练习 1 中的向量加法扩展到使用多个线程块。与线程信息类似,CUDA 提供了用于访问块信息的内置变量。在本练习中,我们将使用其中两个:blockIdx.x和gridDim.x。
- blockIdx.x包含网格中块的索引
- gridDim.x包含网格的大小
并行化理念
我们不使用线程块来迭代数组,而是使用多个线程块来创建N线程;每个线程处理数组的一个元素。以下是并行化思想的说明。
每个线程块有 256 个线程,因此我们至少需要N/256线程块才能拥有总共的N线程。要将线程分配给特定元素,我们需要知道每个线程的唯一索引。此类索引可以按以下方式计算
int tid = blockIdx.x * blockDim.x + threadIdx.x;
练习:尝试在vector_add_grid.cu
- 复制vector_add.cu到vector_add_grid.cu
$> cp vector_add.cu vector_add_thread.cu
- 使用多个线程块进行并行化vector_add()。
- 处理为N任意数字的情况。
- 提示:添加一个条件来检查线程是否在可接受的数组索引范围内工作。
- 编译并分析程序
$> nvcc vector_add_grid.cu -o vector_add_grid
$> nvprof ./vector_add_grid
表现
以下是 Tesla M2050 的分析结果==6564== Profiling application: ./vector_add_grid
==6564== Profiling result:
Time(%) Time Calls Avg Min Max Name
55.65% 20.312ms 2 10.156ms 10.150ms 10.162ms [CUDA memcpy HtoD]
41.24% 15.050ms 1 15.050ms 15.050ms 15.050ms [CUDA memcpy DtoH]
3.11% 1.1347ms 1 1.1347ms 1.1347ms 1.1347ms vector_add(float*, float*, float*, int)
性能比较



















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









