







上海AI实验室提出CVT-Occ:通过时间融合利用视差搜索刷新occ3D-Waymo SOTA
Abstract
基于视觉的3D占据预测由于单目视觉在深度估计上的固有局限性而面临显著挑战。本文介绍了CVT-Occ,一种新颖的方法,通过时间上的体素几何对应进行时间融合,以提高3D占据预测的准确性。通过在每个体素的视线方向上采样点并整合这些点的历史帧特征,我们构建了一个代价体积特征图,从而优化当前体积特征以改进预测结果。我们的方法利用了历史观察中的视差线索,并采用数据驱动的方法学习代价体积。通过在Occ3D-Waymo数据集上的严格实验验证了CVT-Occ的有效性,在3D占据预测任务上以最小的额外计算成本超越了最新的方法。
代码获取:https://github.com/Tsinghua-MARS-Lab/CVT-Occ
欢迎加入自动驾驶实战群
ntroduction
基于视觉的3D语义占据预测在3D感知领域迅速发展,推动了其在自动驾驶、机器人和增强现实中的关键应用。该任务旨在通过视觉输入估计3D空间内每个体素的占据状态和语义标签。
尽管其重要性显著,3D占据预测面临着巨大的挑战。单靠单目视觉时,深度估计的模糊性尤为突出。虽然立体视觉已被提出作为提高深度估计准确性的一种解决方案,但其在实际应用中仍然有限。立体相机的使用在自动驾驶车辆和机器人系统中是不切实际的,因为它需要大量的校准和重新校准。一种更具前景的替代方法是使用多视角时间融合,它可以利用随时间延伸的多视角基线来增强3D感知任务。
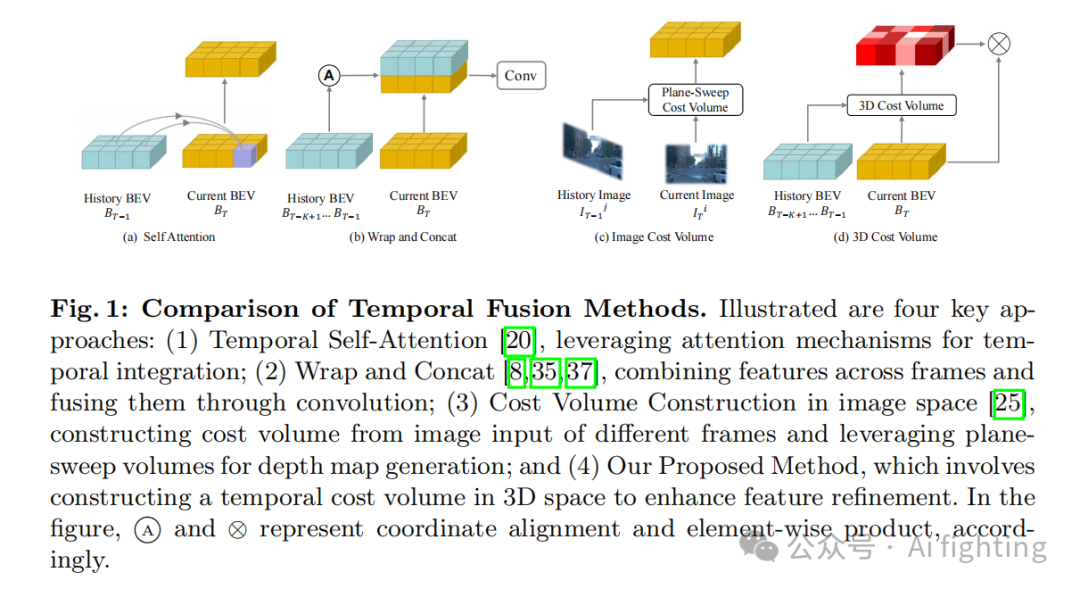
近年来,视觉3D目标检测的进展表明,结合时间观察可以提升检测性能。在我们的研究中,我们将新兴的时间融合方法分为三类,详见图1。前两类方法基于扭曲,使用IMU数据对齐不同时间点的鸟瞰视图特征图,并通过自注意机制或拼接和卷积操作进行特征融合。这些方法隐式地使用时间信息,但没有充分利用3D空间中的几何约束。第三类方法,如图1©所示,使用成本体积技术,能够更好地利用几何约束来获得深度感知的特征,但处理多视角任务时计算成本较高。总的来说,这些方法在利用时间信息和3D几何约束方面存在局限性,尤其是在处理多视角和长时间跨度的数据时。
鉴于这些方法的局限性,我们提出了一种新范式,如图1中的(d)所示。本文中,我们引入了CVT-Occ,这是一种创新的时间融合方法,旨在利用随时间变化的体素几何对应来提高占据预测的准确性。我们的方法涉及沿着每个体素的视线方向采样点——定义为体素与相机光学中心相连的直线——并根据相对相机姿态确定这些点在历史帧中的对应3D位置。然后,我们从历史帧中采样这些点的特征,并将它们与当前体素特征进行整合,构建一个代价体积特征图。该特征图随后用于优化当前体积的特征,从而提高占据预测的准确性。
3.Method
3.1 问题设置
仅给定RGB图像作为输入,模型旨在预测特定体积内的密集语义场景。具体来说,我们利用当前时间戳t及之前的图像,表示为
![]()
,
![]()
,其中L代表相机的数量。我们的输出定义为体素网格
![]()
,位于时间戳t的自车坐标系中。该网格内的每个体素要么为空(由表示),要么由特定的语义类别
![]()
占据。这里,M表示感兴趣类别的总数,而H, W, Z分别表示网格的长度、宽度和高度。主要目标是训练神经网络Θ(·)生成语义体素网格
![]()
,以逼近真实值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









