







 本文介绍如何解决使用PyTorch训练模型时遇到的标签类型错误问题,通过使用sklearn.preprocessing.LabelEncoder将标签集中的类别转换为整数,从而避免TypeError。
本文介绍如何解决使用PyTorch训练模型时遇到的标签类型错误问题,通过使用sklearn.preprocessing.LabelEncoder将标签集中的类别转换为整数,从而避免TypeError。
但愿有人能明白我标题的意思,因为自己在找相关解决办法的时候这样搜没有找到,所以写这篇博客记录下。
问题:
我要放入模型中的训练集和标签是这样的(都是numpy格式的文件):


标签集中共有1926个标签,10个类别,(类别前边的数字,代表的是对应的第几张图片)。
然后,直接把他放进模型中训练,但是把标签数组转换成张量的过程中出现了类型不匹配问题
Ytr = np.load('train1/'+'Ytr01.npy',allow_pickle=True)
y_data = torch.from_numpy(Ytr).reshape(1926,).type(torch.FloatTensor)
Traceback (most recent call last):
File "train.py", line 81, in <module>
y_data = torch.from_numpy(Ytr).reshape(1926,).type(torch.FloatTensor) #
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.
那么,接下来就是解决TypeError: can't convert np.ndarray of type numpy.object_.
思路就是把原标签集中标签的类型改为上述错误中的任一基本类型,可以直接将标签集中的每个类别转换成一个整数。
这里要用到sklearn.preprocessing.LabelEncoder这个工具,文档写了多种转换方式,我根据自己的需要选择了其中一种:
import numpy as np
from sklearn.preprocessing import LabelEncoder
#先把原标签集加载进来
y = np.load('Desktop/UCF10/train1/'+'Ytr01.npy')
#转换
le = preprocessing.LabelEncoder()
y=le.fit_transform(y)
#保存新标签集
np.save("Desktop/UCF10/train1/Ytr01", y)就是这点代码!顺便把测试标签也转了
看下效果:
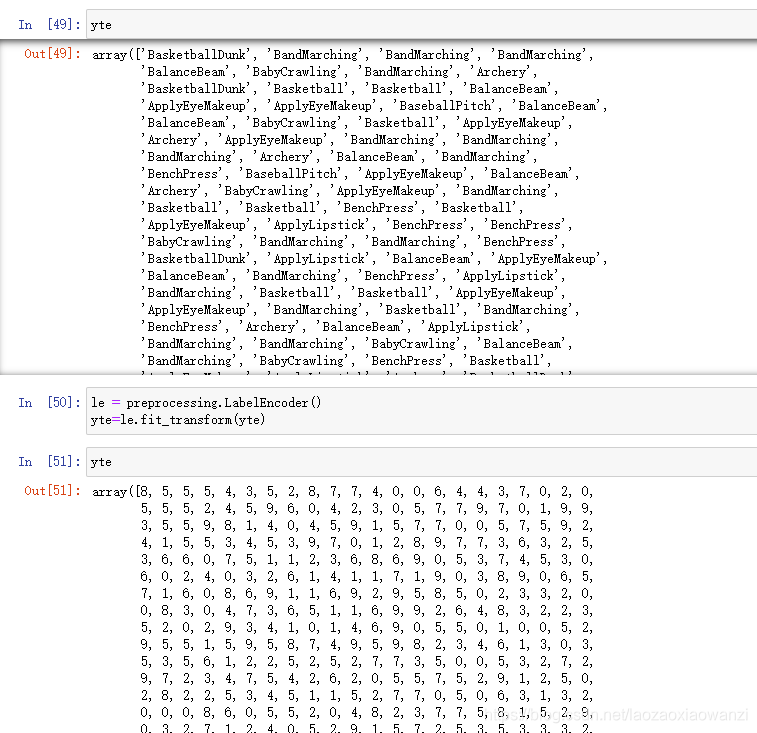
自动转好~~,具体解释看官放文档,用哪个理解哪个。官方
再放进模型中就可以正常跑了。。。


















 5504
5504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











