









 本文详细介绍音频特征提取过程,包括预加重、分帧、加窗、FFT等步骤,并深入讲解声谱图、梅尔频谱、梅尔倒谱的概念及其在语音合成与识别中的应用。
本文详细介绍音频特征提取过程,包括预加重、分帧、加窗、FFT等步骤,并深入讲解声谱图、梅尔频谱、梅尔倒谱的概念及其在语音合成与识别中的应用。
文章目录
提取音频的整体步骤
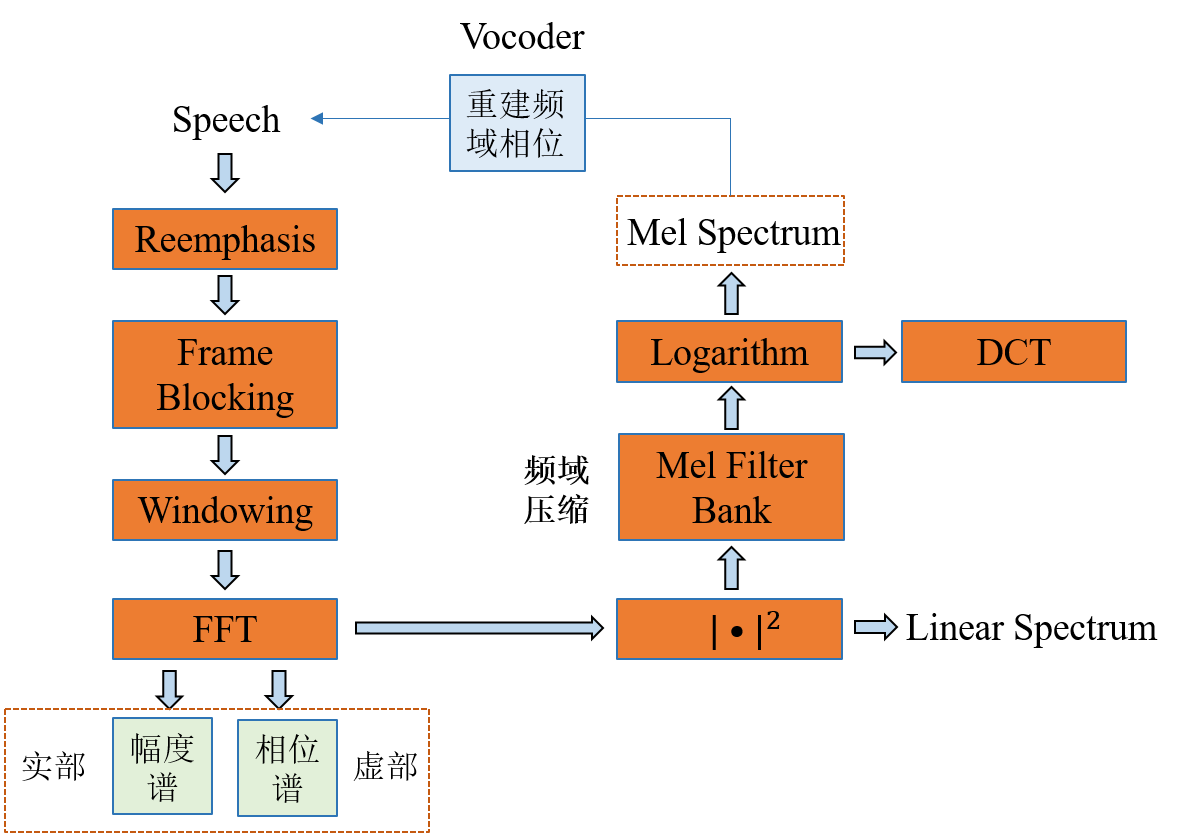
预加重
- 解释一下信噪比:
信噪比的计量单位是dB,其计算方法是10lg(Ps/Pn),其中Ps和Pn分别代表信号和噪声的有效功率,也可以换算成电压幅值的比率关系:20Lg(Vs/Vn),Vs和Vn分别代表信号和噪声电压的“有效值”。在音频放大器中,我们希望的是该放大器除了放大信号外,不应该添加任何其它额外的东西。因此,信噪比应该越高越好。
例如,某音箱的信噪比为80dB,即输出信号功率是噪音功率的
1
0
8
10^8
108 倍,信噪比数值越高,相对噪音越小。
预加重的目的是提升高频部分,对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。原因是因为对于语音信号来说,语音的低频段能量较大,能量主要分布在低频段,语音的功率谱密度随频率的增高而下降,这样,鉴频器输出就会高频段的输出信噪比明显下降,从而导致高频传输衰弱,使高频传输困难,这对信号的质量会带来很大的影响。因此,在传输之前把信号的高频部分进行加重,然后接收端再去重,能够提高信号传输质量。
分帧
一般取这个
加窗
每帧信号通常要与一个平滑的窗函数相乘,让帧两端平滑地衰减到零,这样可以降低傅里叶变换后旁瓣的强度,取得更高质量的频谱。对每一帧,选择一个窗函数,窗函数的宽度就是帧长。常用的窗函数有矩形窗、汉明窗、汉宁窗、高斯窗等。
- 以汉明窗为例:时间跨度为20ms-40ms。
w h a m ( n ) = α − β ⋅ c o s ( 2 π n N − 1 ) w_{ham}(n)=α−β⋅cos(\frac{2πn}{N−1}) wham(n)=α−β⋅cos(N−12πn) , α = 0.53836 , β = 0.46164 α=0.53836,β=0.46164 α=0.53836,β=0.46164
FFT(快速傅里叶变换)
- 之前有介绍过,FFT是快速计算DFT的一种方法, DFT是根据N个采样点判断是哪个正弦还是余弦信号, 得到频谱图, 这种对帧信号加窗再FFT叫做短时傅里叶变换
声谱图(Spectrogram)
通过前面几步,我们把一段语音进行预加重,分帧,加窗后进行FFT后,每帧语音都对应于一个频谱(Spectrum)。这其实也是短时傅里叶变换
得到音频的振幅和相位谱,需要对频谱取模平方得到语音信号的功率谱,也就是语音合成上常说的线性频谱。
梅尔频谱和梅尔倒谱
频率的单位是赫兹(Hz),人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系。例如如果我们适应了1000Hz的音调,如果把音调频率提高到2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。如果将普通的频率标度转化为梅尔频率标度,映射关系如下式所示:
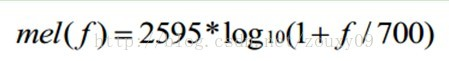
声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组(mel-scale filter banks),变换为梅尔频谱。
也就是说从上面的声谱图到梅尔声谱图只是坐标变化了, 线性坐标到梅尔坐标的变换,通常使用带通滤波器来实现
只需将线性谱乘以三角带通滤波器,并取对数就能得到mel频谱
通常语音合成的任务的音频特征提取一般就到这,mel频谱作为音频特征基本满足了一些语音合成任务的需求。但在语音识别中还需要再做一次离散余弦变换(DCT变换),因为不同的Mel滤波器是有交集的,因此它们是相关的,我们可以用DCT变换去掉这些相关性可以提高识别的准确率,但在语音合成中需要保留这种相关性,所以只有识别中需要做DCT变换。
倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱
记住一句话,在梅尔频谱上做倒谱分析(取对数,做DCT变换)就得到了梅尔倒谱。
1)先对语音进行预加重、分帧和加窗;
2)对每一个短时分析窗,通过FFT得到对应的频谱;
3)将上面的频谱通过Mel滤波器组得到Mel频谱;
4)在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC,这个MFCC就是这帧语音的特征;
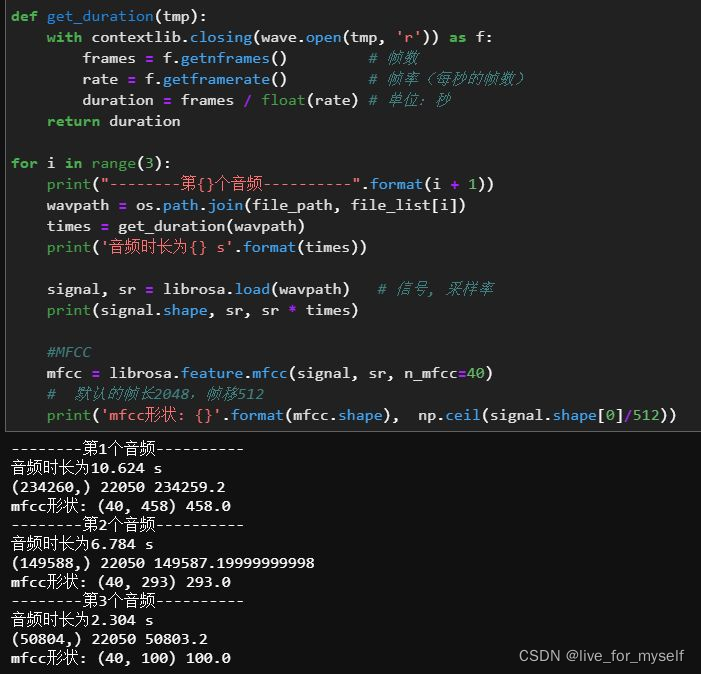
librosa.feature.mfcc()提取的特征如何理解
- 输出是nmfcc, a这样的维度, a是怎么来的呢?
首先给定一个音频文件,通过load加载进来得到signal,shape是(m, ),m=采样率*时间,比如以下代码采样率sr(sampling rate)默认是22050,音频时间为10.624秒,两者相乘即等于m。
至于mfcc的a,一般默认帧长为2048,帧移为512。
先举个例子吧,假设一个音频向量为:[0, 1, 2, 3, 4, 5],若帧长为4,帧移为1,则分帧后得到的矩阵为:[[0,1,2,3] , [1,2,3,4], [2,3,4,5], [3,4,5,pad] … ],每一帧都有4个基本元素,帧移表示两个相邻的帧之间有一定的重叠,帧长度减掉这个重叠后的长度就是帧移,此外mfcc还会事先补齐(padding)。
所以最后mfcc的a 就等于 ceil(m / 帧移)。ceil表示向上取整,m表示音频信号长度。
代码解析
import librosa
config = {
'sample_interval': 1 / 25,
'window_len': 0.025,
'n_mfcc': 14,
'input_dir': 'audio',
}
def _melspectrogram_from_file(audio_path, window_len=config['window_len'], sample_interval=config['sample_interval']):
audio, sr = librosa.load(audio_path, sr=None) # sr 48000
melspectrogram = librosa.feature.melspectrogram(y=audio, sr=sr, n_fft=int(window_len * sr),
hop_length=int(sample_interval * sr))
- 所以这里的n_fft为什么是窗的宽度乘采样率也很好理解了, 就是按窗函数的大小取了这些点, 假如不取这么多点那么FFT和窗指定的时间范围就矛盾了


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











