




目录
1、Prophet 简介
2、Prophet 适用场景
3、Prophet 算法的输入输出
4、Prophet 算法原理
5、Prophet 使用时可设置的参数
6、Prophet 学习资料参考
7、Prophet 模型应用
- 7.0 背景描述
- 7.1 导入数据
- 7.2 拟合模型
- 7.3 预测(使用默认参数)
- 7.4 趋势突变点
- 7.5 季节性、假期效应
- 7.6 模型诊断(内置方法)
- 7.7 模型评估
正文
1、Prophet 简介
fbprophet是facebook开源的一个时间序列预测算法。
prophet库可以做的
- Saturating Forecasts
- Trend Changepoints
- Seasonality, Holidays Effects
- Multiplicative Seasonality
- Uncertainty Intervals
- Outliers
- Non-Daily Data
- Diagnostics
2、Prophet 适用场景
Prophet适用于具有明显的内在规律的商业行为数据,例如:有如下特征的业务问题:
- a.有至少几个月(最好是一年)的每小时、每天或每周观察的历史数据;
- b.有多种人类规模级别的较强的季节性趋势:每周的一些天和每年的一些时间;
- c.有事先知道的以不定期的间隔发生的重要节假日(比如国庆节);
- d.缺失的历史数据或较大的异常数据的数量在合理范围内;
- e.有历史趋势的变化(比如因为产品发布);
- f.对于数据中蕴含的非线性增长的趋势都有一个自然极限或饱和状态。
3、Prophet 算法的输入输出
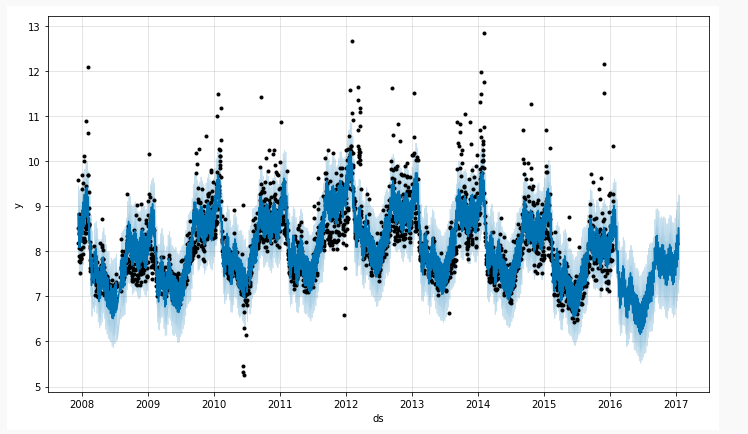
上图为一个时间序列场景:
黑色表示原始的时间序列离散点
深蓝色的线表示使用时间序列来拟合所得到的取值
浅蓝色的线表示时间序列的一个置信区间,也就是所谓的合理的上界和下界
prophet 所做的事情就是:
输入已知的时间序列的时间戳和相应的值;
输入需要预测的时间序列的长度;
输出未来的时间序列走势。
输出结果可以提供必要的统计指标,包括拟合曲线,上界和下界等。
传入prophet的数据
分为两列 ds 和 y, 【 ds表示时间序列的时间戳,y表示时间序列的取值 】
其中:
ds是pandas的日期格式,样式类似与
YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS;y列必须是数值型,代表着我们希望预测的值。
通过 prophet 的计算,可以计算出:
-
yhat,表示时间序列的预测值
-
yhat_lower,表示预测值的下界
-
yhat_upper,表示预测值的上界
4、Prophet 算法原理
算法模型:
模型整体由三部分组成:
- growth(增长趋势)
- seasonality(季节趋势)
- holidays(节假日对预测值的影响)
其中:
- g(t) 表示趋势项,它表示时间序列在非周期上面的变化趋势;
- s(t) 表示周期项,或者称为季节项,一般来说是以周或者年为单位;
- h(t) 表示节假日项,表示时间序列中那些潜在的具有非固定周期的节假日对预测值造成的影响;
即误差项或者称为剩余项,表示模型未预测到的波动,
Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
4.1 趋势项模型
趋势项有两个重要的函数,一个是基于逻辑回归函数的(非线性增长),另一个是基于分段线性函数的(线性增长)
4.1.1 基于逻辑回归的趋势项:
,
其中,
-
C(t)表示承载量:
- 它是一个随时间变化的函数,限定了所能增长的最大值
- 在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好 C(t) 的取值才行
-
k 表示增长率:
-
在现实的时间序列中,曲线的走势肯定不会一直保持不变,在某些特定的时候或者有着某种潜在的周期曲线会发生变化,模型定义了增长率k发生变化时对应的点,将其称作changepoints。
-
在 Prophet 里面,是需要设置变点的位置的,而每一段的趋势和走势也是会根据变点的情况而改变的。在程序里面有两种方法,一种是通过人工指定的方式指定变点的位置;另外一种是通过算法来自动选择。在默认的函数里面,Prophet 会选择 n_changepoints = 25 个变点,然后设置变点的范围是前 80%,也就是在时间序列的前 80% 的区间内会设置变点。之后还要看一些边界条件是否合理,例如时间序列的点数是否少于 n_changepoints 等内容;其次如果边界条件符合,那变点的位置就是均匀分布的。
-
下面假设已经放置了 S 个变点,并且变点的位置是在时间戳
上,那么在这些时间戳上,就需要给出增长率的变化,也就是在时间戳
上发生的 change in rate。可以假设有这样一个向量:
, 其中
表示在时间戳
 ,通过一个指示函数
,通过一个指示函数, 就是
在时间戳 t 上面的增长率就是
.
-
-
m 表示偏移量:
- 当增长率k调整后,每个changepoint点对应的偏移量m也应该相应调整以连接每个分段的最后一个时间点,表达式如下:
4.1 2 基于分段线性函数的趋势项:
其中,
- k 表示增长率
表示增长率的变化量
- m 表示偏移量
- 分段线性函数与逻辑回归函数最大的区别就是
的设置不一样,在分段线性函数中
. 这与之前逻辑回归函数中的设置是不一样的。
- 在分段线性函数中,是不需要 capacity 这个指标的,因此 m = Prophet() 这个函数默认的使用 growth = ‘linear’ 这个增长函数,也可以写作 m = Prophet(growth = ‘linear’);
4.1.3 变点的选择
在 Prophet 算法中,有三个比较重要的指标,分别为:
- changepoint_range:变点的位置
- n_changepoint:变点的个数
- changepoint_prior_scale:增长的变化率
其中:
- changepoint_range 指的是百分比,需要在前 changepoint_range 那么长的时间序列中设置变点,在默认的函数中是 changepoint_range = 0.8。
- n_changepoint 表示变点的个数,在默认的函数中是 n_changepoint = 25。
- changepoint_prior_scale 表示变点增长率的分布情况,在论文中,
,这里的
就是 change_point_scale。
在默认的场景下,变点的选择是基于时间序列的前 80% 的历史数据,然后通过等分的方法找到 25 个变点,而变点的增长率是满足 Laplace 分布的。因此,当
趋近于零的时候,
也是趋向于零的,此时的增长函数将变成全段的逻辑回归函数或者线性函数。
4.1.4 对未来的预估
- 从历史上长度为T的数据中,可以选择出 S 个变点,它们所对应的增长率的变化量是
- 此时我们需要预测未来,因此也需要设置相应的变点的位置,此时通过 Poisson 分布等概率分布方法找到新增的changepoint_ts_new 的位置,
- 然后与 changepoint_t 拼接在一起就得到了整段序列的 changepoint_ts。
4.2 季节性趋势
由于时间序列中有可能包含多种天,周,月,年等周期类型的季节性趋势,因此,傅里叶级数可以用来近似表达这个周期属性。
使用傅立叶级数来模拟时间序列的周期性:假设 P 表示时间序列的周期,P = 365.25 表示以年为周期,P = 7 表示以周为周期。
它的傅立叶级数的形式都是:
N表示希望在模型中使用的这种周期的个数,较大的N值可以拟合出更复杂的季节性函数,然而也会带来更多的过拟合问题。
按照经验值,对于以年为周期的序列(P = 365.25)而言,N = 10;对于以周为周期的序列(P = 7 )而言,N = 3
- 当 N = 10 时,
- 当 N = 3 时,
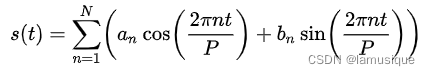
因此时间序列的季节项就是:
其中,
的初始化是
。
- 这里的
是通过 seasonality_prior_scale 来控制的,也就是说
- 在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。
4.3 节假日效应
- 在现实环境中,节假日或者是一些大事件都会对时间序列造成很大影响,而且这些时间点往往不存在周期性,对这些点的分析是极其必要的.
- 在 Prophet 里面,收集了各个国家的特殊节假日。除了节假日之外,用户还可以根据自身的情况来设置必要的假期,例如双十一.
- 由于每个节假日或者某个已知的大事件对时间序列的影响程度不一样,例如春节,国庆节则是七天的假期,对于劳动节等假期来说则假日较短.
- 因此,节假日模型将不同节假日在不同时间点下的影响视作独立的模型,并且可以为不同的节假日设置不同的前后窗口值,表示该节假日会影响前后一段时间的时间序列.
- 对于第 i 个节假日来说,
表示该节假日的前后一段时间.
- 为了表示节假日效应,需要一个相应的指示函数,同时需要一个参数
来表示节假日的影响范围.
假设有 L 个节假日,那么节假日效应模型就是:
其中 和
 .
.
其中,
并且该正态分布是受到 v = holidays_prior_scale 这个指标影响的。
- 默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。
- 该参数可自行调整。
5、Prophet 使用时可设置的参数
-
growth:增长趋势模型。分为两种:”linear”与”logistic”,分别代表线性与非线性的增长,默认值:”linear”.
-
Capacity:在增量函数是逻辑回归函数的时候,需要设置的容量值,表示非线性增长趋势中限定的最大值,预测值将在该点达到饱和.
-
Change Points:可以通过 n_changepoints 和 changepoint_range 来进行等距的变点设置,也可以通过人工设置的方式来指定时间序列的变点,默认值:“None”.
-
n_changepoints:用户指定潜在的”changepoint”的个数,默认值:25。
-
changepoint_prior_scale:增长趋势模型的灵活度。调节”changepoint”选择的灵活度,值越大,选择的”changepoint”越多,从而使模型对历史数据的拟合程度变强,然而也增加了过拟合的风险。默认值:0.05。
-
seasonality_prior_scale(seasonality模型中的):调节季节性组件的强度。值越大,模型将适应更强的季节性波动,值越小,越抑制季节性波动,默认值:10.0.
-
holidays_prior_scale(holidays模型中的):调节节假日模型组件的强度。值越大,该节假日对模型的影响越大,值越小,节假日的影响越小,默认值:10.0。
-
freq:数据中时间的统计单位(频率),默认为”D”,按天统计.
-
periods:需要预测的未来时间的个数。例如按天统计的数据,想要预测未来一年时间内的情况,则需填写365。
-
mcmc_samples:mcmc采样,用于获得预测未来的不确定性。若大于0,将做mcmc样本的全贝叶斯推理,如果为0,将做最大后验估计,默认值:0。
-
interval_width:衡量未来时间内趋势改变的程度。表示预测未来时使用的趋势间隔出现的频率和幅度与历史数据的相似度,值越大越相似,默认值:0.80。当mcmc_samples = 0时,该参数仅用于增长趋势模型的改变程度,当mcmc_samples > 0时,该参数也包括了季节性趋势改变的程度。
-
uncertainty_samples:用于估计未来时间的增长趋势间隔的仿真绘制数,默认值:1000。
6、Prophet 学习资料参考
官方链接:
-
论文:《Forecasting at scale》,https://peerj.com/preprints/3190/
案例链接:
-
预测股价并进行多策略交易:https://mp.weixin.qq.com/s/bf_CHcoZMjqP6Is4ebD58g
-
预测Medium每天发表的文章数:https://mp.weixin.qq.com/s/1wujYYDP_P2uerZzZBaspg
-
预测客运量:https://www.analyticsvidhya.com/blog/2018/05/generate-accurate-forecasts-facebook-prophet-python-r/
作者:小小孩儿的碎碎念
链接:https://www.jianshu.com/p/218757bee516
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









