



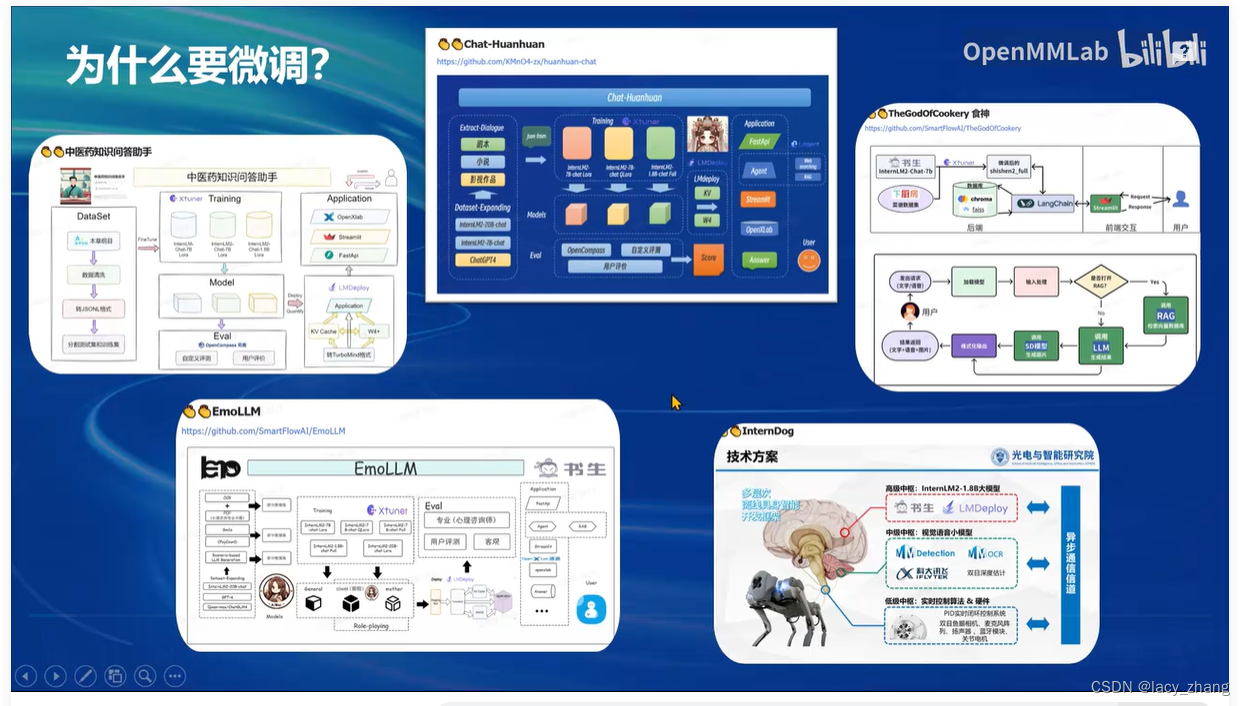
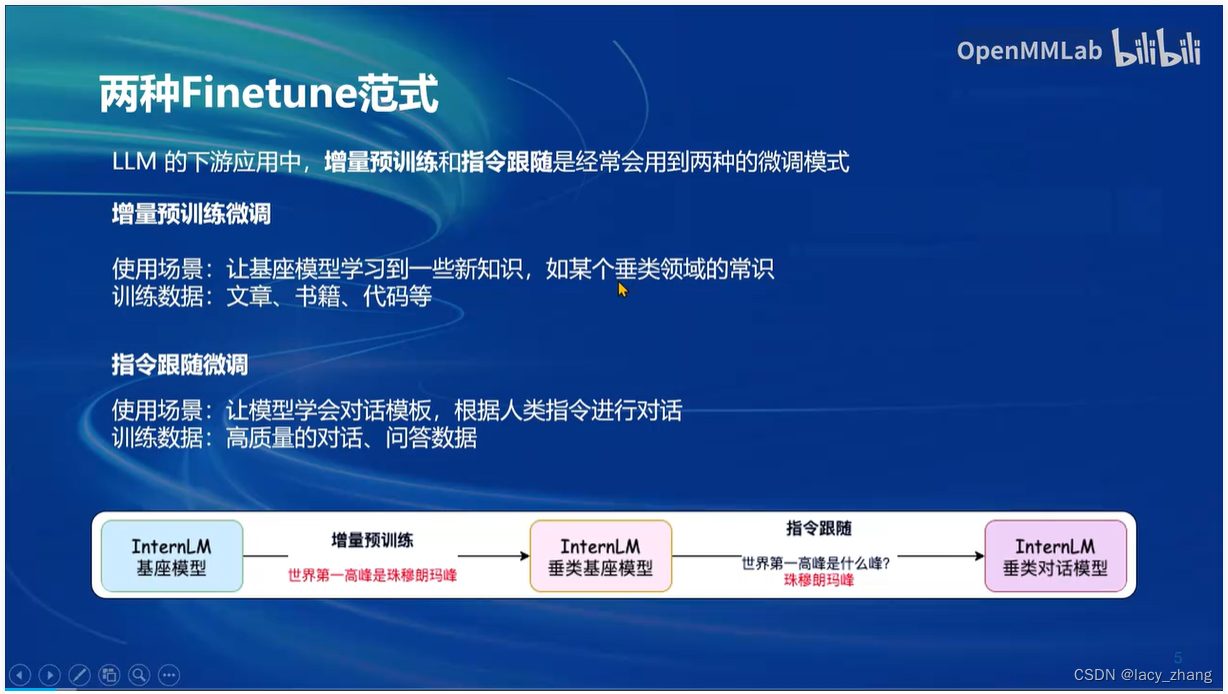
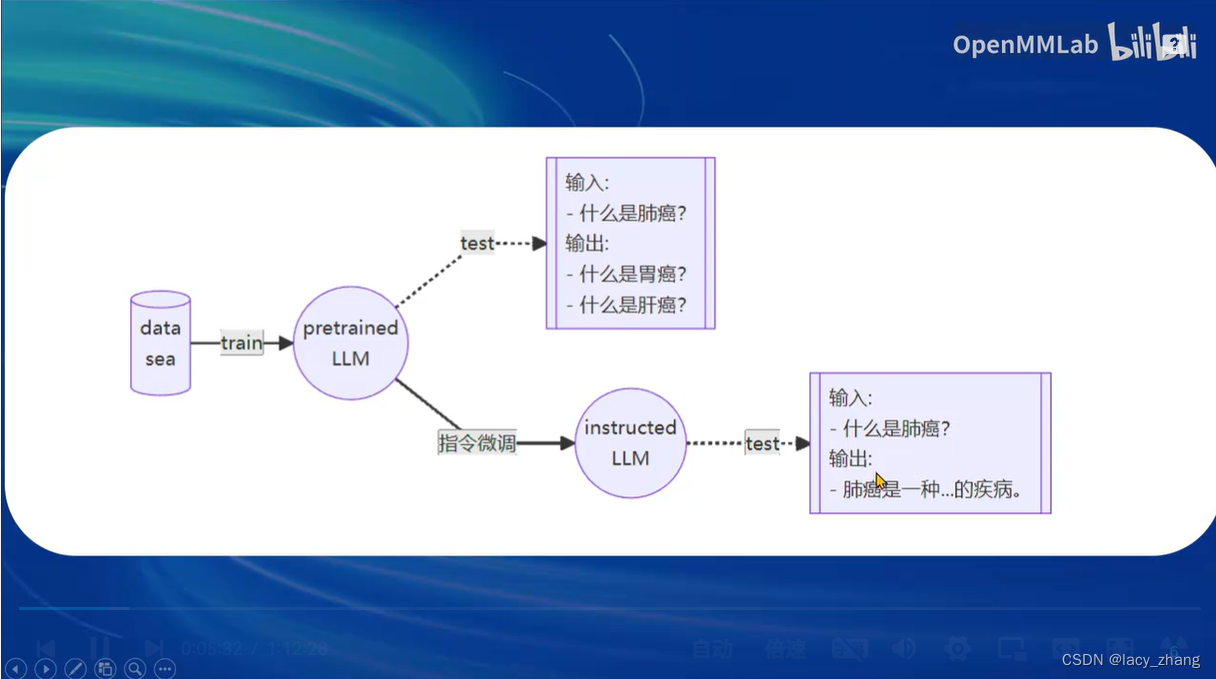
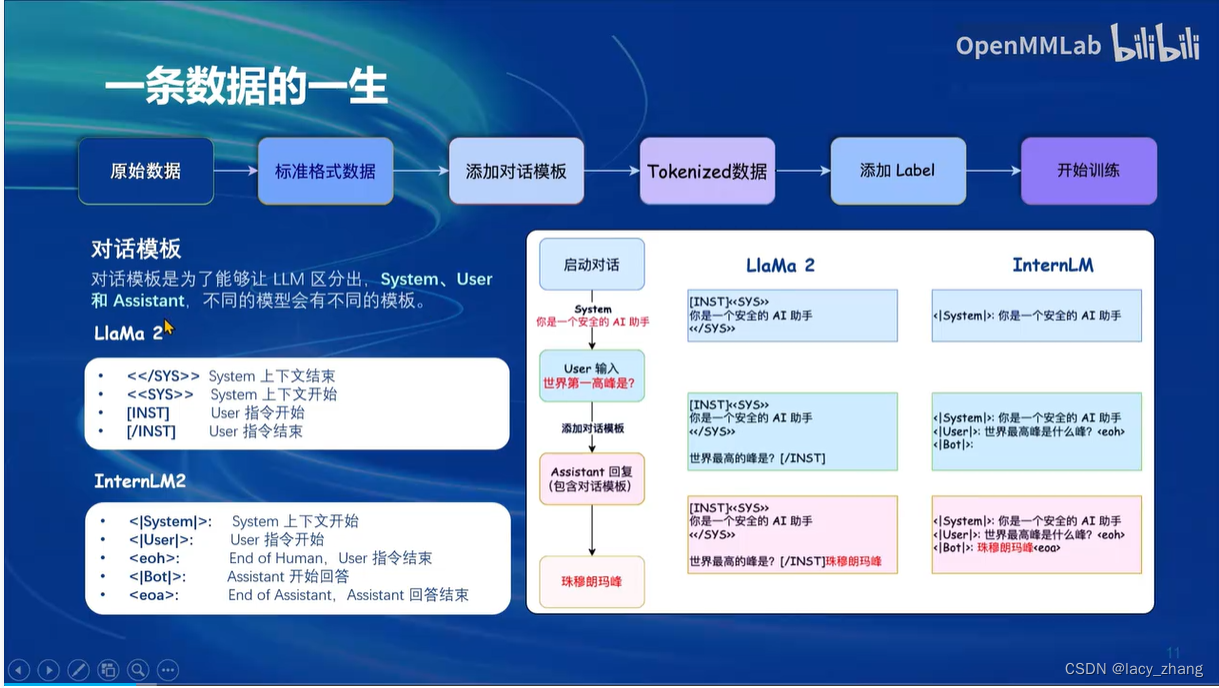
 文章讨论了在微调LLM过程中,数据集的质量对结果的重要性,强调了XTuner作为可靠工具的价值。同时,HaotianLiu等人利用GPT-4V和ImageProjector创建了高质量数据对,以提升文本和图像模型的性能。
文章讨论了在微调LLM过程中,数据集的质量对结果的重要性,强调了XTuner作为可靠工具的价值。同时,HaotianLiu等人利用GPT-4V和ImageProjector创建了高质量数据对,以提升文本和图像模型的性能。
【XTuner 微调 LLM:1.8B、多模态和 Agent】
微调过程常被人们称为“炼丹”,意在强调炼丹过程中的材料选择、火候控制、时间把握以及丹炉的选择都至关重要。在此比喻中,可以将XTuner视为炼丹的丹炉,只要其质量可靠,不会在炼丹过程中出现问题,一般而言便能够顺利进行。
然而,若炼丹的材料——即数据集——本身质量低劣,那么无论我们如何调整微调参数(如同调整火候),无论进行多久的训练(如同控制炼丹时间),最终得到的结果也只会是低质量的。只有当使用了优质的材料,才可以进一步考虑炼丹的时间和方法。因此,学会构建高质量的数据集显得尤为重要。

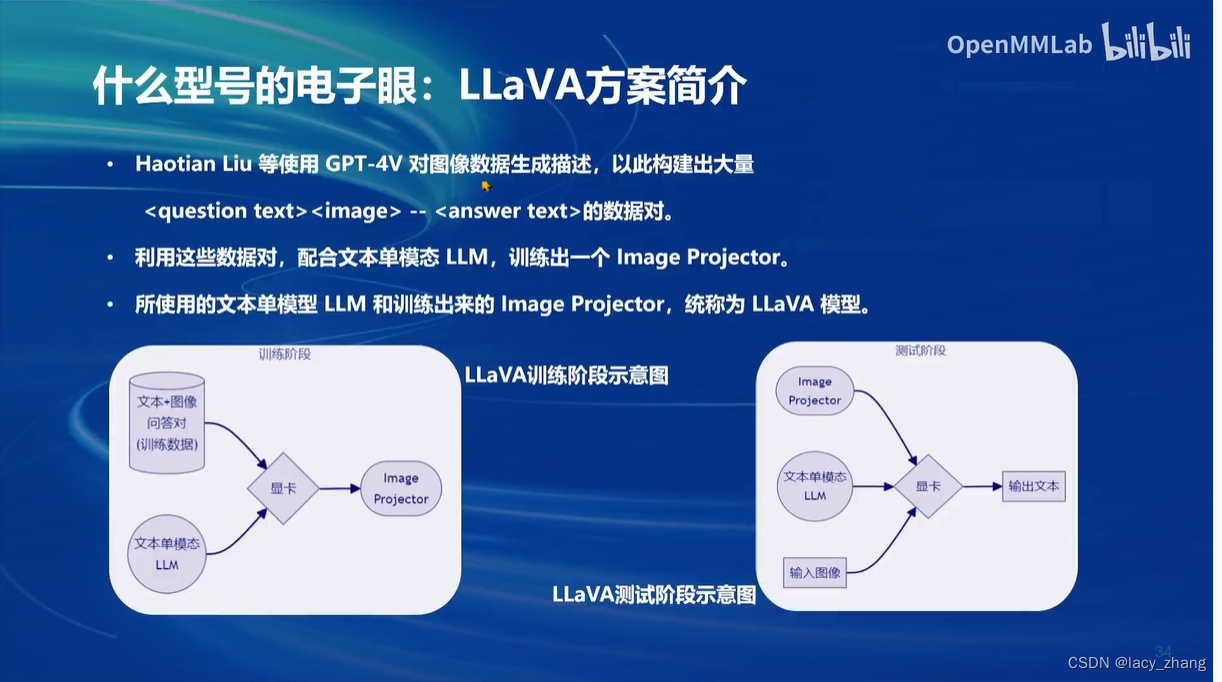
Haotian Liu等使用GPT-4V对图像数据生成描述,以此构建出大量<question text><image> -- <answer text>的数据对。利用这些数据对,配合文本单模态LLM,训练出一个Image Projector。
所使用的文本单模型LLM和训练出来的Image Projector,统称为LLaVA模型。
二者都是在已有LLM的基础上,用新的数据训练一个新的小文件。
只不过,LLM套上LoRA之后,有了新的灵魂(角色);而LLM套上Image Projector之后,才有了眼睛。



















 2247
2247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









