







from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
corpus=["我 来到 北京 清华大学",#第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦",#第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院",#第三类文本的切词结果
"我 爱 北京 天安门"]#第四类文本的切词结果
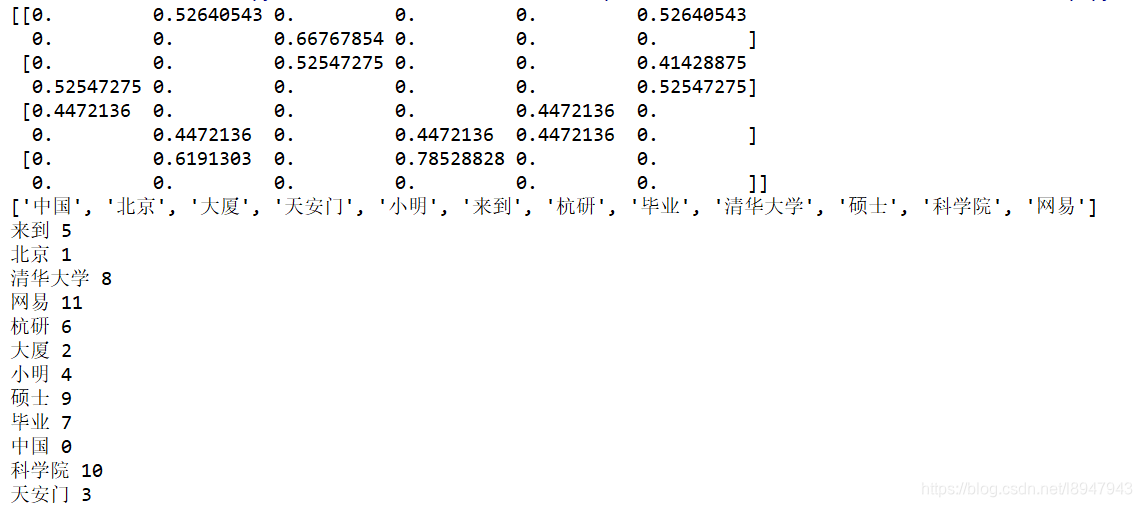
result = tfidf.fit_transform(corpus).toarray()
print(result)
# 统计关键词
word = tfidf.get_feature_names()
print(word)
# 统计关键词出现次数,几句话对比几次
for k,v in tfidf.vocabulary_.items():
print(k,v)
# 对比第i类文本的词语tf-idf权重
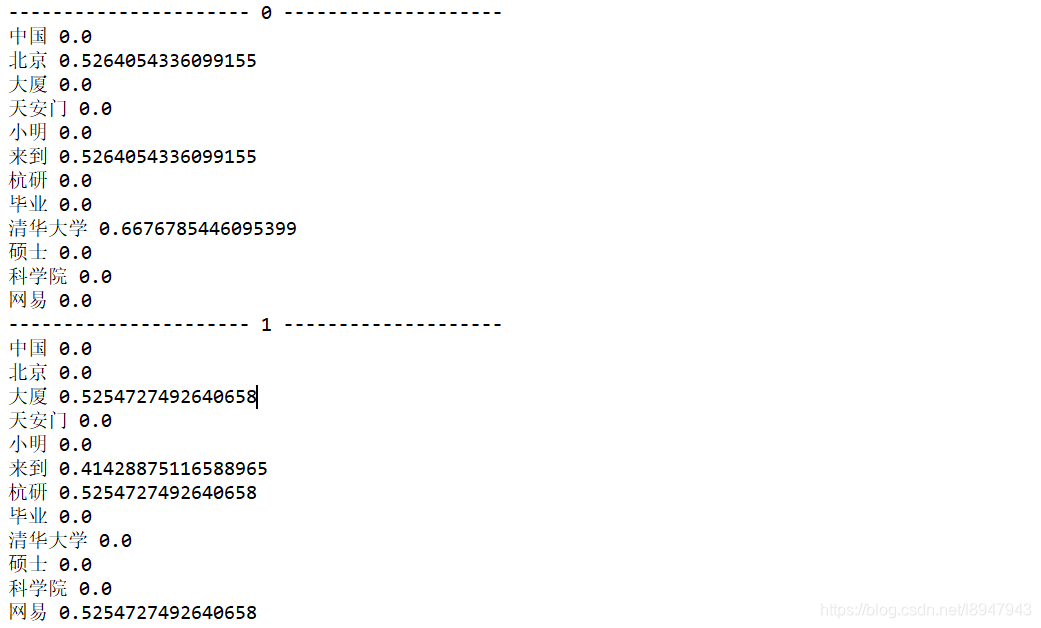
for i in range(len(result)):
print('----------------------',i,'--------------------')
for j in range(len(word)):
print(word[j],result[i][j])
输出结果如图:



















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











