









为什么要引入残差连接(Residual Connection)?
当网络深度不断增加时,直接堆叠更多的卷积/全连接层会遇到 优化困难 和 性能退化。
残差连接通过 “旁路”(skip‑connection) 把输入
x
\mathbf{x}
x 直接加到一段变换
F
(
x
,
{
W
}
)
\mathcal{F}(\mathbf{x},\{\mathbf{W}\})
F(x,{W}) 的输出上,形成
y
=
F
(
x
,
{
W
}
)
+
x
\boxed{\; \mathbf{y} \;=\; \mathcal{F}(\mathbf{x},\{\mathbf{W}\}) + \mathbf{x}\;}
y=F(x,{W})+x
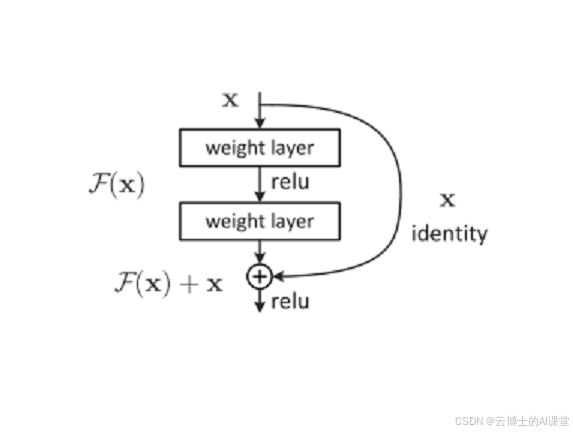
从而让网络学习 残差映射 F ( x ) = H ( x ) − x \mathcal{F}(\mathbf{x}) = H(\mathbf{x}) - \mathbf{x} F(x)=H(x)−x 而不是完整映射 H ( x ) H(\mathbf{x}) H(x)。这一步骤同时解决了深层网络的两大核心问题:
| 需解决的核心问题 | 残差连接的作用 |
|---|---|
| 1. 梯度消失/爆炸(Vanishing & Exploding Gradients) 深层网络的链式求导会把梯度连乘,导致梯度在前层迅速缩小或放大,训练极难收敛。 | 残差中的恒等路径为梯度提供了一条 无衰减的直通通道: ∂ L ∂ x = ∂ L ∂ y ( 1 + ∂ F ∂ x ) \frac{\partial \mathcal{L}}{\partial \mathbf{x}} \;=\; \frac{\partial \mathcal{L}}{\partial \mathbf{y}}\bigl(1 + \frac{\partial \mathcal{F}}{\partial \mathbf{x}}\bigr) ∂x∂L=∂y∂L(1+∂x∂F) 即使 ∂ F ∂ x \frac{\partial \mathcal{F}}{\partial \mathbf{x}} ∂x∂F 很小(或很大),仍有 1 直接参与反向传播,显著缓解梯度消失/爆炸。 |
| 2. 退化问题(Degradation Problem) 当层数加深时,训练误差反而升高:网络“想学却学不到”比浅层更优的表示。 | 若深层网络只需实现恒等映射,理应不比浅层差;残差结构显式提供 x \mathbf{x} x,因此网络 至少可以退化成恒等映射,避免训练误差随深度上升;同时让每个残差块专注于学习“增量改进” F ( x ) \mathcal{F}(\mathbf{x}) F(x),更易优化。 |
小结
- 残差连接 = 恒等快捷路径 + 残差映射。
- 它通过提供 直接的信息与梯度通道,同时解决了
- 梯度消失/爆炸 的优化难题;
- 性能退化 的表示瓶颈。
- 因此,网络可以安全地扩展到上百甚至上千层,而仍保持可训练性与高精度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









