







推荐系统召回算法
协同召回算法
协同过滤召回算法是召回算法的一个早期的经典研究方向。主要是应用在推荐环节的早期阶段,大致可以分为基于用户、基于物品的,两者各有优劣。
UCF和ICF的优点是具有较好的可解释性,缺点是对于稀疏的交互矩阵,效果较差。无法挖掘用户和物品的深层关联。
Swing算法虽然挖掘了用户和物品的关联网络,但是仍然是浅层的分析。基于矩阵分解SVD的算法一定程度解决了这个问题,通过将整个矩阵分解为用户和物品各自的向量,不仅解决了挖掘深度的问题,还可以融入属性信息
下面两个算法最终的目的都是去给用户u推荐物品。通常的实现方式是预测用户u对物品i的评分,将给分高的物品排在前面。但是这样做有一些弊端,只能看到用户对物品的绝对喜好程度,物品之间的先后次序并没有考虑在内。因为推荐的往往是一系列物品,物品之间的次序也会影响到用户的选择。

UserCF
- 表示用户向量:用户评分的0-1向量
- 计算物品之间的相似性
- 找到与用户u的兴趣相近的其他用户
- 筛选出前TopN的用户
- 基于其他用户对物品i的评分,预测用户u对物品i的评分
预测公式1
r
u
i
^
=
∑
j
=
1
N
s
i
m
u
j
∗
(
r
j
i
)
∑
j
=
1
N
s
i
m
u
j
\hat{{r_{ui}}} = \frac{\sum\limits_{j=1}^{N} sim_{uj} * (r_{ji} )}{\sum\limits_{j=1}^{N} sim_{uj}}
rui^=j=1∑Nsimujj=1∑Nsimuj∗(rji)
预测公式2: 相比公式1,好处在于考虑到不同用户评分的差异,例如用户1认为4分为平均水平,用户2认为3分为平均水平。
r u i ^ = r u ‾ + ∑ j = 1 N s i m u j ∗ ( r j i − r j ‾ ) ∑ j = 1 N s i m u j \hat{{r_{ui}}} = \overline{r_{u}} + \frac{\sum\limits_{j=1}^{N} sim_{uj} * (r_{ji} - \overline{r_j})}{\sum\limits_{j=1}^{N} sim_{uj}} rui^=ru+j=1∑Nsimujj=1∑Nsimuj∗(rji−rj)
优劣
优点:良好的可解释性;适合用户少、物品多的场景,例如新闻推荐。
缺点:热门物品具有很强的头部效应,与其他物品之间的相似度较大。越热门的物品也容易被推荐;物品的其他特征没有被使用
ItemCF
- 表示物品向量:物品评分的0-1向量
- 计算物品之间的相似性
- 找到与物品i的相似的其他物品
- 筛选出前TopN的物品
- 基于其他物品与物品i的相似性,预测用户u对物品i的评分
预测公式1
r
u
i
^
=
r
i
‾
+
∑
j
=
1
N
s
i
m
j
i
∗
(
r
u
j
−
r
j
‾
)
∑
j
=
1
N
s
i
m
j
i
\hat{{r_{ui}}} = \overline{r_{i}} + \frac{\sum\limits_{j=1}^{N} sim_{ji} * (r_{uj} - \overline{r_j})}{\sum\limits_{j=1}^{N} sim_{ji}}
rui^=ri+j=1∑Nsimjij=1∑Nsimji∗(ruj−rj)
优劣
优点:良好的可解释性;适合用户少、物品多的场景,例如新闻推荐。
缺点:对于用户的交互记录较少的场景,例如大宗商品,家电、房屋等。计算用户之间的相似度效果较差
UCF和ICF的一般流程
- 表示用户/物品向量
- 相似性计算
- 评分预测公式
Swing
矩阵分解(matrix factorization)
视角一 组合特征的处理
为了发掘复杂关系之间的关联,需要提高模型对高维组合特征的拟合能力。例如下图所示。用户对物品是否点击的反馈记录中,电影有两个特征,分别是语言和类型(这里我们忽略用户和物品ID)。但是仅仅依靠一阶特征很难深入挖掘用户的偏好。
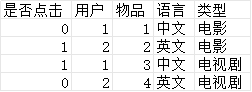
在下图中,将特征按照各自的离散值两两组合,形成了二阶特征。

但是当引入ID类型的特征时,特别是在实际场景中,用户和物品的ID是千万级别的,学习的参数规模为
m
×
n
m \times n
m×n.不可能完全组合。这种情况下,可以将用户和物品分别用K维的低维向量表示。且K远小于用户和物品的个数。此时需要学习的参数规模变为
m
×
k
+
n
×
k
m \times k + n \times k
m×k+n×k。此时用户ID和物品ID的某个组合特征对应的系数就等于各自的embedding相乘。
视角二 分解合并
思想:先分解,再合并
将用户物品的评分矩阵分解为两个部分,用户矩阵
U
U
U和物品矩阵
V
V
V。
预测值
r
u
i
=
∑
k
=
1
d
U
u
k
V
i
k
r_ui = \sum\limits_{k=1}^{d}U_{uk}V_{ik}
rui=k=1∑dUukVik
BiasSVD
预测值
r
u
i
=
μ
+
b
u
+
b
i
+
∑
k
=
1
d
U
u
k
V
i
k
r_ui = \mu + b_u + b_i + \sum\limits_{k=1}^{d}U_{uk}V_{ik}
rui=μ+bu+bi+k=1∑dUukVik
其中,
μ
\mu
μ表示全局的平均评分,
b
u
b_u
bu和
b
i
b_i
bi分别表示用户u的偏置和物品i的偏置
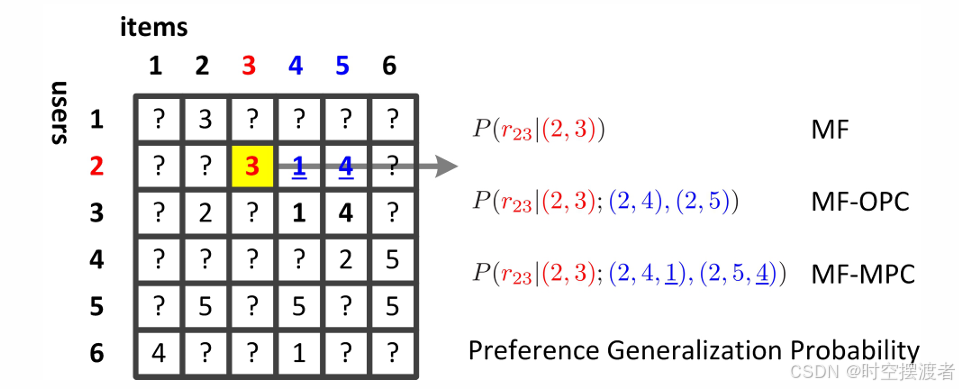
SVD++(MF-OPC)
传统的矩阵分解对于用户u对物品i的评分,认为只与用户u和物品i有关,即
P
{
r
u
i
∣
(
u
,
i
)
}
P\{r_{ui}|(u,i)\}
P{rui∣(u,i)}。
但是SVD++从两个不同角度考虑评分矩阵,既考虑用户对物品的具体评分、又把用户对哪些物品有过评分当作用户的一种虚拟属性。
P
{
r
u
i
∣
(
u
,
1
)
;
(
u
,
2
)
,
.
.
,
(
u
,
i
)
,
(
u
,
i
+
1
)
}
P\{r_{ui}|(u,1);(u,2),..,(u,i),(u,i+1)\}
P{rui∣(u,1);(u,2),..,(u,i),(u,i+1)}
预测值
r
u
i
=
μ
+
b
u
+
b
i
+
∑
k
=
1
d
U
u
k
V
i
k
+
∑
k
=
1
d
U
u
k
−
i
~
V
i
k
r_ui = \mu + b_u + b_i + \sum\limits_{k=1}^{d}U_{uk}V_{ik} + \sum\limits_{k=1}^{d}\widetilde{U_{uk}^{-i}}V_{ik}
rui=μ+bu+bi+k=1∑dUukVik+k=1∑dUuk−i
Vik
∑
k
=
1
d
U
u
k
−
i
~
V
i
k
\sum\limits_{k=1}^{d}\widetilde{U_{uk}^{-i}}V_{ik}
k=1∑dUuk−i
Vik是对单类反馈矩阵进行分解的结果,单类反馈矩阵指的是用户和物品是否交互的0-1矩阵。 所以SVD++也被归于MF-OPC(One class Preference Context)
其中,
U
u
~
\widetilde{{U_u}}
Uu
表示用户u的一种上下文偏好
U
u
~
=
∑
i
′
∈
J
u
−
{
i
}
W
i
′
∣
J
u
−
{
i
}
∣
\widetilde{{U_u}} = \frac{\sum\limits_{i' \in {J_u} - \{i\}}W_{i'}}{\sqrt{|J_u -\{i\}|}}
Uu
=∣Ju−{i}∣i′∈Ju−{i}∑Wi′
可以理解为是对用户u交互过的物品(除带预测的物品i外)的潜在特征求平均得到结果.
MF-MPC(multiclass preference context)
结合多类偏好上下文的矩阵分解,该方法是在SVD++的基础上改进的。SVD++仅考虑到用户对不同物品的评分,但是没有区分评分值。所以这里为
P
{
r
u
i
∣
(
u
,
1
,
3
)
;
(
u
,
2
,
4
)
,
.
.
,
(
u
,
i
)
,
(
u
,
i
+
1
,
3.5
)
}
P\{r_{ui}|(u,1,3);(u,2,4),..,(u,i),(u,i+1,3.5)\}
P{rui∣(u,1,3);(u,2,4),..,(u,i),(u,i+1,3.5)}
预测值
r
u
i
=
μ
+
b
u
+
b
i
+
∑
k
=
1
d
U
u
k
V
i
k
+
∑
k
=
1
d
U
u
k
M
P
C
~
V
i
k
r_ui = \mu + b_u + b_i + \sum\limits_{k=1}^{d}U_{uk}V_{ik} + \sum\limits_{k=1}^{d}\widetilde{U_{uk}^{MPC}}V_{ik}
rui=μ+bu+bi+k=1∑dUukVik+k=1∑dUukMPC
Vik
其中,
U
u
M
P
C
~
\widetilde{{U_u}^{MPC}}
UuMPC
表示用户u的一种多类上下文偏好
U
u
M
P
C
~
=
∑
r
∈
M
∑
i
′
∈
J
u
r
−
{
i
}
M
i
′
r
∣
J
u
r
−
{
i
}
∣
\widetilde{{U_u}^{MPC}} = \sum\limits_{r \in M}\frac{\sum\limits_{i' \in {J_u^r} - \{i\}}M_{i'}^{r}}{\sqrt{|J_u^{r} -\{i\}|}}
UuMPC
=r∈M∑∣Jur−{i}∣i′∈Jur−{i}∑Mi′r
J
u
r
J_u^{r}
Jur是用户交互过的评分为r的数据集;M是评分的集合,{1,2,3,4,5};
M
i
′
r
M_{i'}^{r}
Mi′r 是一种与类别(评分)
r
∈
M
r \in M
r∈M相关的物品i’的潜在特征向量
求解
将其转换为一个最优化问题,加入正则化项后变为RSVD(regularized)
目标函数
min
U
u
,
V
i
,
b
u
,
b
i
∑
(
u
,
i
)
∈
R
(
r
u
i
−
(
μ
+
b
u
+
b
i
+
p
u
T
q
i
)
)
2
+
λ
(
∥
U
u
∥
2
+
∥
V
i
∥
2
+
b
u
2
+
b
i
2
)
\min_{U_u, V_i, b_u, b_i} \sum_{(u, i) \in R} (r_{ui} - (\mu + b_u + b_i + p_u^T q_i))^2 + \lambda ( \| U_u \|^2 + \| V_i \|^2 + b_u^2 + b_i^2 )
Uu,Vi,bu,bimin(u,i)∈R∑(rui−(μ+bu+bi+puTqi))2+λ(∥Uu∥2+∥Vi∥2+bu2+bi2)
注意:
- 这里只对有评分记录的数据进行处理,对于缺失值不做处理。
- 用户和物品矩阵 U , V U,V U,V以及物品的潜在特征向量 W W W初始化为 ( r − 0.5 ) × 0.01 (r-0.5) \times 0.01 (r−0.5)×0.01
参考文献
1.datawhale组队学习 https://datawhalechina.github.io/fun-rec/#/ch02/ch2.1/ch2.1.1/mf
2.《智能推荐技术》潘微科、林晶、明仲 著


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









