







本次学习的重点是FM系列和WideNDeep系列。其实这两个模型是存在因果关系的。从最初的LR模型开始,因为缺失高效的特征交互方式,产生了FM模型,即通过向量内积代替特征之间的两两交互的参数。最后DNN的引入可以建模更高阶的特征。但是DNN如何与FM相结合,有两种方式,分别是并行和串行,串行引出了FNN、PNN等模型,但是浅层的特征在高层的隐藏层起不到作用。所以WideAndDeep诞生,直接将浅层和深层结合。但是这样会缺失重点,因此采用FM代替浅层,得到DeepFM模型
逻辑回归系列
协同过滤和矩阵分解的算法主要利用用户和物品之间的相似度进行推荐。但是逻辑回归将推荐问题看作一个回归问题,通过预测正样本的概率对物品进行排序(正样本指的是用户可能交互的物品,例如点击了某个新闻、购买了某个物品、观看某个视频)。此时的推荐问题变为点击率预估问题(Click Through Rate,CTR)。
Linear Regression
- 特征工程:将用户年龄、性别、点击数等统计特征和物品的标签以及统计特征变为数值型特征向量。
假设特征 X = x 1 , . . . , x n X = {x_1,...,x_n} X=x1,...,xn,其中包括了用户、物品和环境的特征向量。
- 确定优化目标,例如点击率。训练模型,确定权重参数。
通过模型学习到各个特征对应的推荐权重 W = ( w 1 , . . . , w n ) W=(w_1,...,w_n) W=(w1,...,wn)
- 模型上线时,输入用户和物品的实时特征,得到预估物品的点击率,并根据点击率排序,得到推荐结果。
将各个特征加权求和,得到 Z = W T X Z = \mathbf{W}^TX Z=WTX。输入Sigmoid激活函数得到0~1之间的概率值 S i g m o i d ( Z ) = 1 1 + e − W T X Sigmoid(Z) = \frac{1}{1+e^{-\mathbf{W}^TX}} Sigmoid(Z)=1+e−WTX1
损失函数及优化过程
这里推导梯度下降法求解权重参数的过程。
- 假设模型对正样本的预估概率为 P ( y = 1 ∣ x ; w ) = f w ( x ) P(y=1|x;w) = f_w(x) P(y=1∣x;w)=fw(x),那么对负样本的预估概率为 P ( y = 0 ∣ x ; w ) = 1 − f w ( x ) P(y=0|x;w) = 1 - f_w(x) P(y=0∣x;w)=1−fw(x)。
这里 f w ( x ) = 1 1 + e − w T x f_w(x)=\frac{1}{1+e^{-\mathbf{w}^Tx}} fw(x)=1+e−wTx1,其含义为某个样本为正样本的概率。 负样本的定义:已经曝光,即在页面上展示,但用户未点击的商品
- 将概率值统一起来,对于任意样本
x
x
x,其属于类别
y
y
y的概率为
P ( y ∣ x ; w ) = f w ( x ) y ( 1 − f w ( x ) ) 1 − y = ( 1 1 + e − w T x ) y ( 1 − 1 1 + e − w T x ) 1 − y P(y|x;w) = f_w(x)^y {(1-f_w(x))^{1-y}}= (\frac{1}{1+e^{-\mathbf{w}^Tx}})^{y} (1 - \frac{1}{1+e^{-\mathbf{w}^Tx}})^{1-y} P(y∣x;w)=fw(x)y(1−fw(x))1−y=(1+e−wTx1)y(1−1+e−wTx1)1−y
3.极大似然法得到损失函数,对于大小为n的样本集合,我们希望在所有样本上的预测概率均最大
m a x w L ( w ) = m a x w ∏ i = 1 n P ( y i ∣ x i ; w ) max_{w} L(w) = max_{w} \prod_{i = 1}^{n} P(y_i|x_i;w) maxwL(w)=maxwi=1∏nP(yi∣xi;w)
- 为了方便求导,在等式两侧取对数将连乘变为连加; 并乘一个负系数,将最大化变为最小化。
m i n w L ( w ) = m i n w − 1 m ∑ i = 1 n y i l n f w ( x i ) + ( 1 − y i ) l n ( 1 − f w ( x i ) ) min_{w} L(w) = min_{w} -\frac{1}{m}\sum_{i = 1}^{n} y_i ln{f_w(x_i)} + (1-y_i)ln{(1-f_w(x_i))} minwL(w)=minw−m1i=1∑nyilnfw(xi)+(1−yi)ln(1−fw(xi))
总结:LR模型有三个优点:
- 数学含义的支持
- 可解释性强
- 工程化的需要
缺点:缺少特征的组合,对特征的深度挖掘不足
特征交叉
下面是一个特征交叉的训练样本的案例
| 电影名称 | 电影类型 | 上映年份 | 导演评分(满分 10 分) | 主演人气(取值范围 1 - 100) | 电影时长(分钟) | 科幻_2000 | 科幻_2001 | … | 爱情_2000 | 爱情_2001 | … | 科幻_导演评分8 | 科幻_导演评分8.5 | … | 爱情_主演人气70 | 爱情_主演人气75 | … | 用户评分(目标变量,满分 10 分) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 《星际穿越》 | 科幻 | 2014 | 8 | 80 | 169 | 0 | 0 | … | 0 | 0 | … | 1 | 0 | … | 0 | 0 | … | 8.5 |
| 《泰坦尼克号》 | 爱情 | 1997 | 9 | 90 | 194 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 9.0 |
| 《复仇者联盟 4》 | 科幻 | 2019 | 7 | 95 | 181 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.2 |
| 《千与千寻》 | 动画 | 2001 | 8.5 | 85 | 125 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.8 |
| 《寄生虫》 | 剧情 | 2019 | 8 | 70 | 132 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.0 |
| 《速度与激情 7》 | 动作 | 2015 | 7.5 | 90 | 137 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 7.8 |
| 《哈利·波特与魔法石》 | 奇幻 | 2001 | 8 | 80 | 152 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.3 |
| 《摔跤吧!爸爸》 | 剧情 | 2016 | 8.2 | 75 | 140 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.4 |
| 《阿凡达》 | 科幻 | 2009 | 8.5 | 88 | 162 | 0 | 0 | … | 0 | 0 | … | 0 | 1 | … | 0 | 0 | … | 8.6 |
| 《疯狂动物城》 | 动画 | 2016 | 8 | 82 | 108 | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 0 | 0 | … | 8.7 |
POLY2
f
P
O
L
Y
2
(
x
)
=
s
i
g
m
o
i
d
(
w
0
+
w
1
x
+
P
O
L
Y
2
(
w
2
,
x
)
)
f_{POLY2}(x) = sigmoid(w_0 + w_1x + POLY2(w2,x))
fPOLY2(x)=sigmoid(w0+w1x+POLY2(w2,x))
P
O
L
Y
2
(
w
,
x
)
=
∑
j
1
=
1
n
−
1
∑
j
2
=
j
1
+
1
n
w
j
1
,
j
2
x
j
1
x
j
2
POLY2(w,x) = \sum_{j_1=1}^{n-1}\sum_{j_2=j_1+1}^{n} w_{j_1,j_2}x_{j_1}x_{j_2}
POLY2(w,x)=j1=1∑n−1j2=j1+1∑nwj1,j2xj1xj2
保留LR模型的一阶部分,加入对所有特征的两两组合,通过学习得到组合特征的系数。
优点:仍然是线性模型,训练方式与LR兼容。
缺点:
- 模型难以收敛:因为本来的类别型特征向量就很稀疏,两两组合后就更加稀疏,缺少有效的数据进行训练
- 模型的权重参数的数量级变为 n 2 n^{2} n2
FM
f
F
M
(
x
)
=
s
i
g
m
o
i
d
(
w
0
+
w
1
x
+
F
M
(
w
2
,
x
)
)
f_{FM}(x) = sigmoid(w_0 + w_1x + FM(w2,x))
fFM(x)=sigmoid(w0+w1x+FM(w2,x))
F
M
(
w
,
x
)
=
∑
j
1
=
1
n
−
1
∑
j
2
=
j
1
+
1
n
w
j
1
w
j
2
x
j
1
x
j
2
FM(w,x) = \sum_{j_1=1}^{n-1}\sum_{j_2=j_1+1}^{n} w_{j_1}w_{j_2}x_{j_1}x_{j_2}
FM(w,x)=j1=1∑n−1j2=j1+1∑nwj1wj2xj1xj2
这里的思路与矩阵分解异曲同工,矩阵分解是得到用户和物品的隐向量。这里是对每个特征学习一个隐向量,两两特征的系数就是各自的隐向量的内积。因此权重参数的数量级降为
k
n
kn
kn,k为隐向量的维度。计算公式的推导如下。
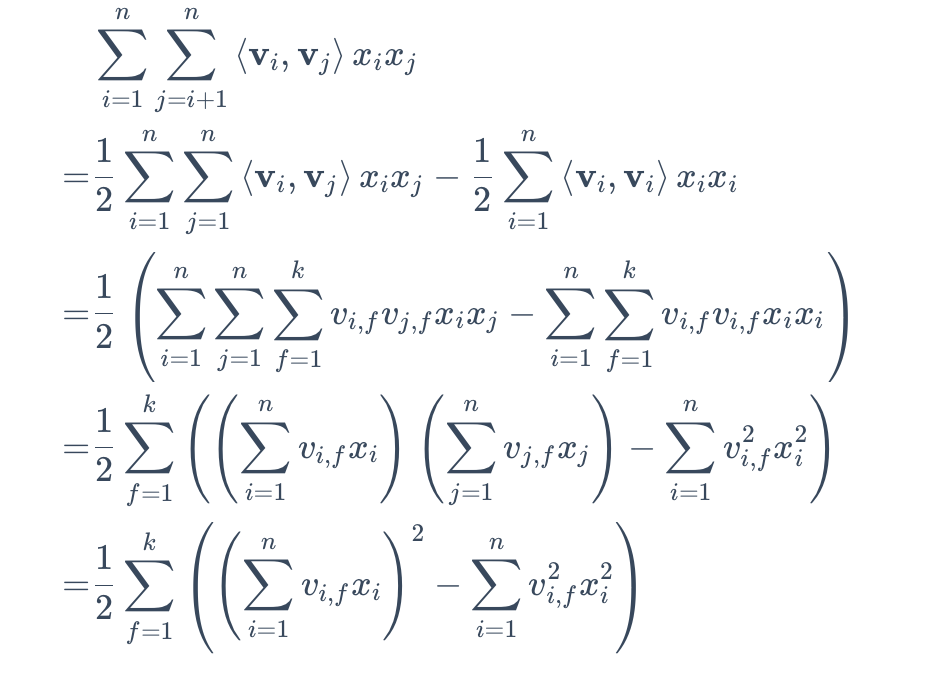
在预测时,要计算用户对物品的点击概率。该公式中的一阶特征项和二阶特征项中的n个特征可以进一步分解用户部分和物品部分。
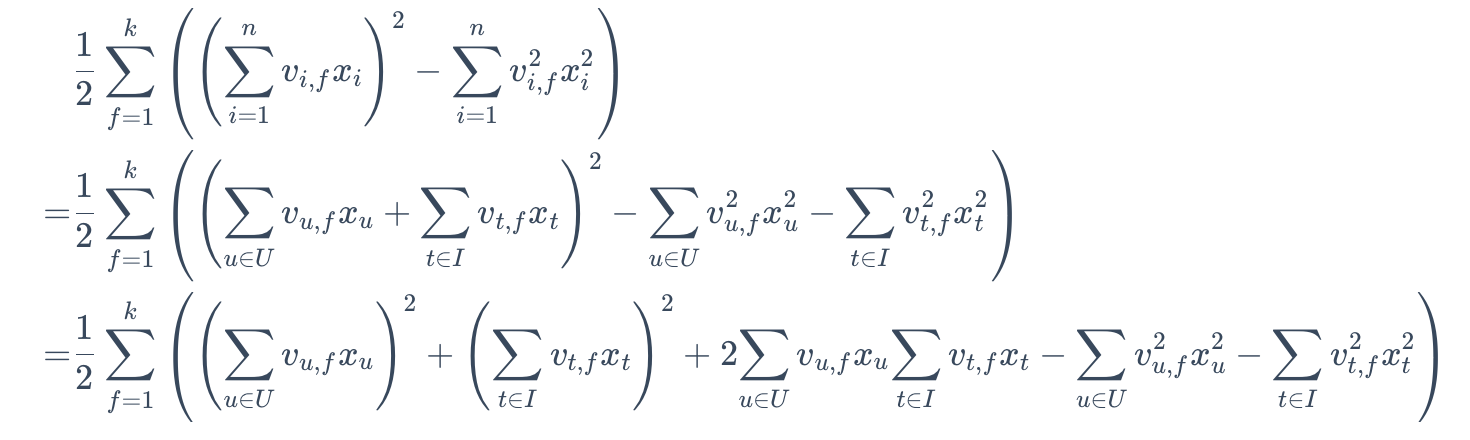
进一步,因为同一个用户对于不同物品的点击概率计算时,用户内部的特征是一致的,所以可以忽略,只需要比较(1)物品内部之间的特征交互得分;(2)用户和物品之间的特征交互得分。
忽略用户内部的特征交互部分得到:
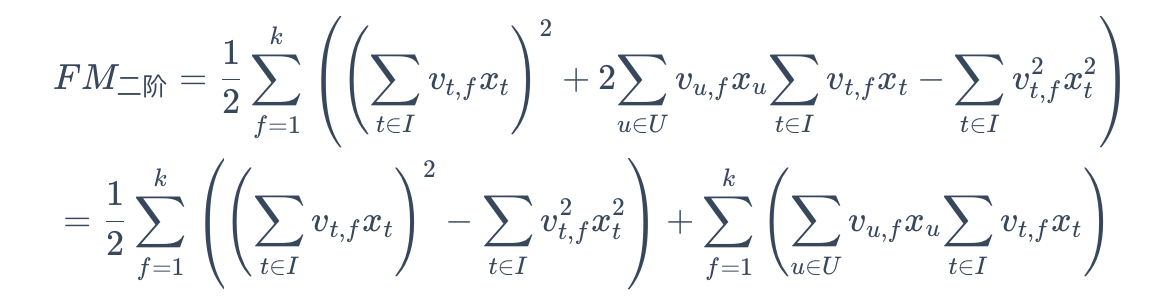
最终的计算公式为:
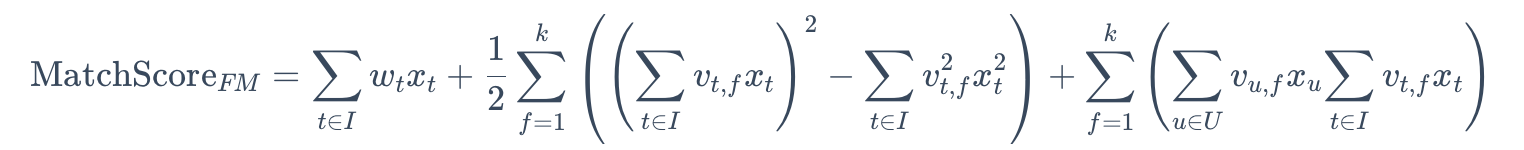
也可以分解为用户向量和物品向量的内积

优点:
- 泛化性更好:例如对是否降价和品牌两个特征。某个样本的这两个特征的组合为(耐克,是),那么只有这两个特征值出现在同一个样本中,POLY2才能学到这个特征组合对应的权重。但是FM因为分别学习到耐克和是对应的隐向量,及时样本中缺少特征组合,也可以很好的建模。
- 同样适用梯度下降法训练
缺点:
- 只能挖掘特征之间的二阶关系,对于更高阶的特征交叉无能为力。
FFM
2015年,Field-aware Factorization Machines。其中field-aware 特征域感知。
其中FFM的二阶项为:
F
F
M
(
w
,
x
)
=
∑
j
1
=
1
n
−
1
∑
j
2
=
j
1
+
1
n
<
w
j
1
,
f
2
,
w
j
2
,
f
1
>
x
j
1
x
j
2
FFM(w,x) = \sum_{j_1=1}^{n-1}\sum_{j_2=j_1+1}^{n} <w_{j_1,f_2},w_{j_2,f_1}> x_{j_1}x_{j_2}
FFM(w,x)=j1=1∑n−1j2=j1+1∑n<wj1,f2,wj2,f1>xj1xj2
这里每个特征
x
j
x_j
xj不止对应一个特征向量,而是对应一组特征向量。当
x
j
1
x
j
2
x_{j_1}x_{j_2}
xj1xj2特征交叉时,
x
j
1
x_{j_1}
xj1对应的特征向量为
w
j
1
,
f
2
w_{j_1,f_2}
wj1,f2,表示
x
j
1
x_{j_1}
xj1的一组隐向量中与
x
j
2
x_{j_2}
xj2的域
f
2
f_2
f2对应的隐向量。
这里的“域”指的是特征域。例如性别特征域,其有三个具体的特征,男、女、未知。
| Publisher(P) | Advertiser(A) | Gender(G) |
|---|---|---|
| ESPN | NIKE | Male |
这里的Publisher、Advertiser、Gender就是特征域。
对于FM模型来说,每个具体的特征都有对应的隐向量,例如
w
E
S
P
N
,
w
N
I
K
E
,
w
M
a
l
e
w_{ESPN},w_{NIKE},w_{Male}
wESPN,wNIKE,wMale。对于ESPN和NIKE、Male交叉,
w
E
S
P
N
.
w
N
I
K
E
w_{ESPN}.w_{NIKE}
wESPN.wNIKE,
w
E
S
P
N
.
w
M
a
l
e
w_{ESPN}.w_{Male}
wESPN.wMale,这里ESPN的隐向量是不变的。
FFM中,其权重为
w
E
S
P
N
,
A
.
w
N
I
K
E
,
P
w_{ESPN,A}.w_{NIKE,P}
wESPN,A.wNIKE,P,
w
E
S
P
N
,
G
.
w
M
a
l
e
,
P
w_{ESPN,G}.w_{Male,P}
wESPN,G.wMale,P。这是因为NIKE和Male分属不同的特征域 Advertiser(A),Gender(G)。所以FFM的权重参数的数量级为
n
.
f
.
k
n.f.k
n.f.k。表示每个特征在f个域上,均有k维的隐向量。其计算复杂度
O
(
k
n
2
)
O(kn^2)
O(kn2)。
理论上,FM模型族可以扩展到三阶特征交叉,但实际上会发生组合爆炸问题。工程上难以实现。深度学习推荐模型通过神经网络可以轻松完成特征组合,下面继续介绍。
WideAndDeep系列
WideAndDeep
DeepFM
参考资料
Datawhale Fun-rec组队学习
https://datawhalechina.github.io/fun-rec/#/ch02/ch2.1/ch2.1.2/FM?id=%e6%80%9d%e8%80%83%e9%a2%98


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









