



 本文深入探讨了神经网络中概率输出的计算与解读方法,包括使用指数函数转换概率,通过lambda函数累积概率乘积,以及从输出中识别最高概率的预测结果。
本文深入探讨了神经网络中概率输出的计算与解读方法,包括使用指数函数转换概率,通过lambda函数累积概率乘积,以及从输出中识别最高概率的预测结果。
字段名翻译取出概率
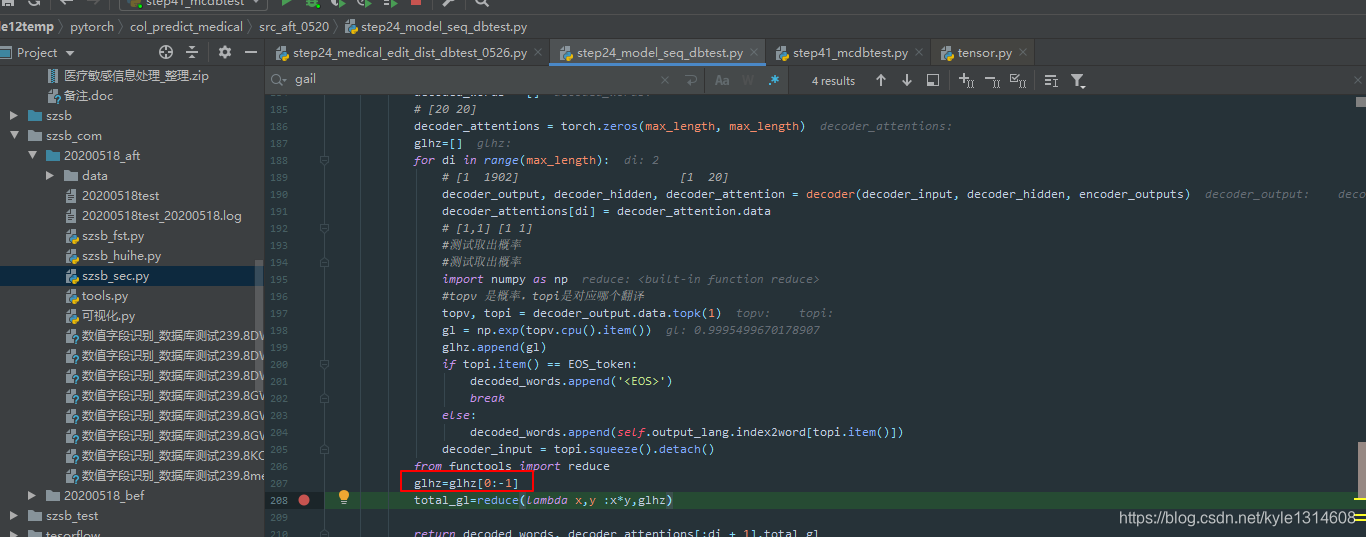
import numpy as np
#topv 是概率,topi是对应哪个翻译
topv, topi = decoder_output.data.topk(1)
gl = np.exp(topv.cpu().item())
glhz.append(gl)
if topi.item() == EOS_token:
decoded_words.append(’’)
break
else:
decoded_words.append(self.output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
from functools import reduce
glhz=glhz[0:-1]
total_gl=reduce(lambda x,y :x*y,glhz)
把结束字段去掉
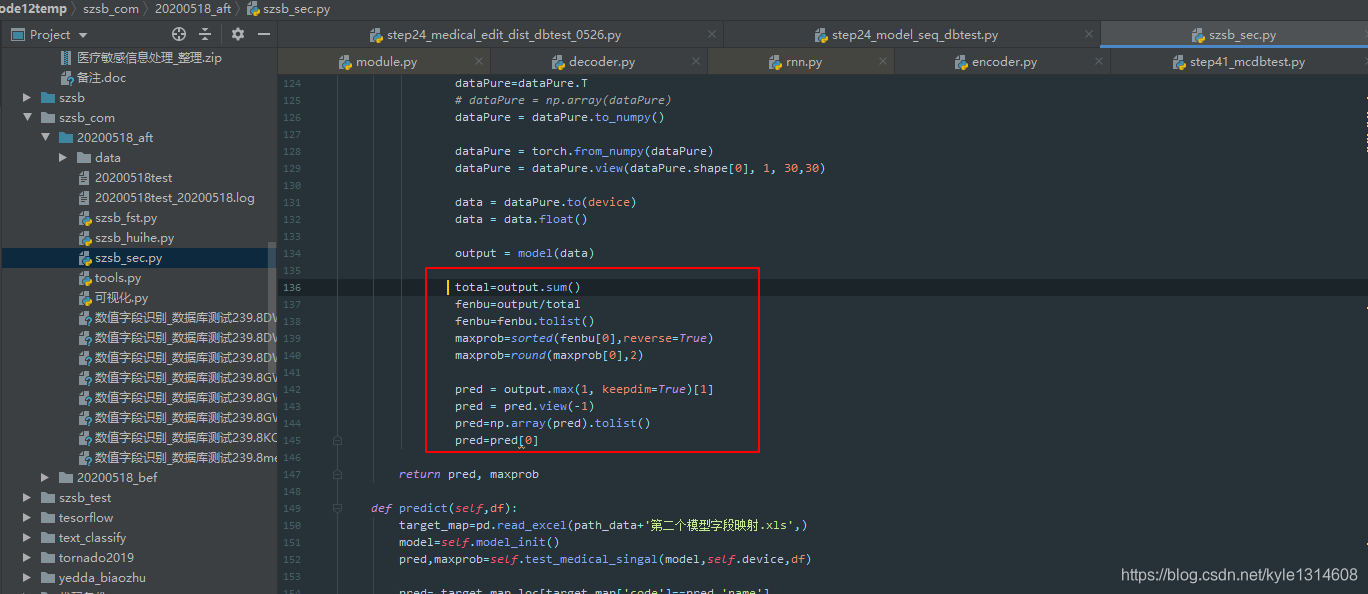
数字识别,简单网络取出概率
output = model(data)
total=output.sum()
fenbu=output/total
fenbu=fenbu.tolist()
maxprob=sorted(fenbu[0],reverse=True)
maxprob=round(maxprob[0],2)
pred = output.max(1, keepdim=True)[1]
pred = pred.view(-1)
pred=np.array(pred).tolist()
pred=pred[0]


















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









