



 本文详细介绍了PyTorch中实现多GPU并行计算的方法,利用torch.nn.DataParallel接口可以有效地将模型分布到多个GPU上进行训练。文章解释了如何配置GPU设备,并说明了数据是如何被分配到各个GPU上的。
本文详细介绍了PyTorch中实现多GPU并行计算的方法,利用torch.nn.DataParallel接口可以有效地将模型分布到多个GPU上进行训练。文章解释了如何配置GPU设备,并说明了数据是如何被分配到各个GPU上的。
Pytorch 的多 GPU 处理接口是 torch.nn.DataParallel(module, device_ids),其中 module 参数是所要执行的模型,而 device_ids 则是指定并行的 GPU id 列表。
而其并行处理机制是,首先将模型加载到主 GPU 上,然后再将模型复制到各个指定的从 GPU 中,然后将输入数据按 batch 维度进行划分,具体来说就是每个 GPU 分配到的数据 batch 数量是总输入数据的 batch 除以指定 GPU 个数。每个 GPU 将针对各自的输入数据独立进行 forward 计算,最后将各个 GPU 的 loss 进行求和,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,这样就完成了一次迭代计算。所以该接口还要求输入数据的 batch 数量要不小于所指定的 GPU 数量。
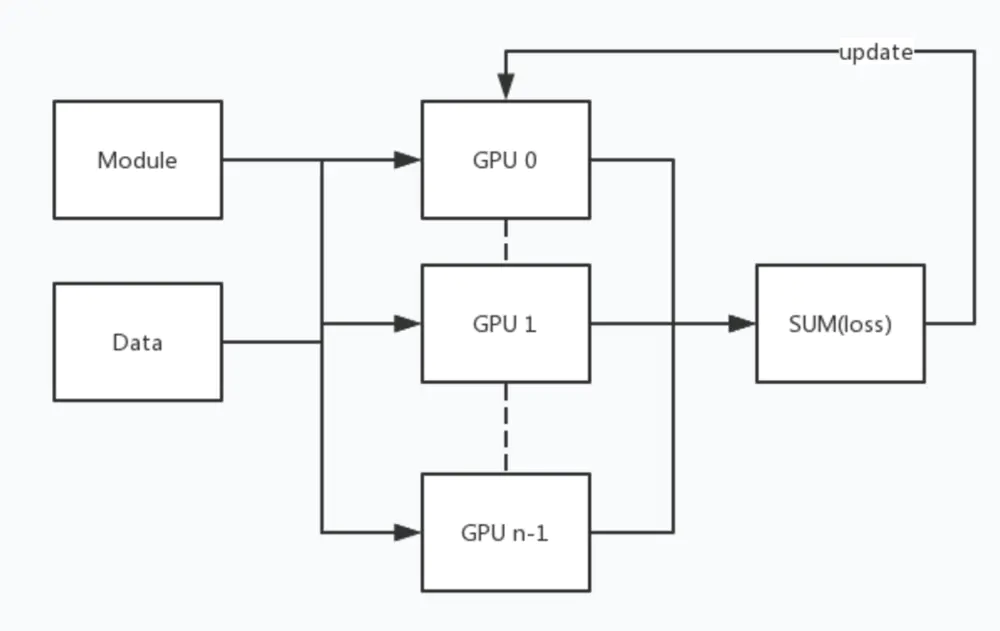
这里有两点需要注意:
- 主 GPU 默认情况下是 0 号 GPU,也可以通过
torch.cuda.set_device(id)来手动更改默认 GPU。 - 提供的多 GPU 并行列表中需要包含有主 GPU。
作者:叶俊贤
链接:https://www.jianshu.com/p/9e36e5e36638
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。



















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









