







 本文是调参笔记,介绍了竞赛中热门的XGBoost算法存在训练耗时、内存占用大的问题,而LightGBM算法在不降低准确率的前提下,速度更快、内存占用更小。主要讲述了LightGBM的两种调参方法,包括对应不同目的可调整的参数及GridSearchCV调参过程。
本文是调参笔记,介绍了竞赛中热门的XGBoost算法存在训练耗时、内存占用大的问题,而LightGBM算法在不降低准确率的前提下,速度更快、内存占用更小。主要讲述了LightGBM的两种调参方法,包括对应不同目的可调整的参数及GridSearchCV调参过程。
1 原生模式
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型保存
gbm.save_model('model.txt')
# 模型加载
gbm = lgb.Booster(model_file='model.txt')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
2 sklearn接口模式
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
# 模型训练
gbm = LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
# 模型存储
joblib.dump(gbm, 'loan_model.pkl')
# 模型加载
gbm = joblib.load('loan_model.pkl')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
调参笔记
在竞赛题中,我们清楚 X G B o o s t XGBoost XGBoost算法非常热门。是很多比赛的大杀器。但是在使用过程中,其训练耗时很长,内存占用比较大。在2017年年1月微软在GitHub的上开源了LightGBM。该算法在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升算法。可用于排序,分类,回归以及很多其他的机器学习任务中。其详细的原理及操作内容详见
本文主要将
L
i
g
h
t
G
B
M
LightGBM
LightGBM两种调参方法:
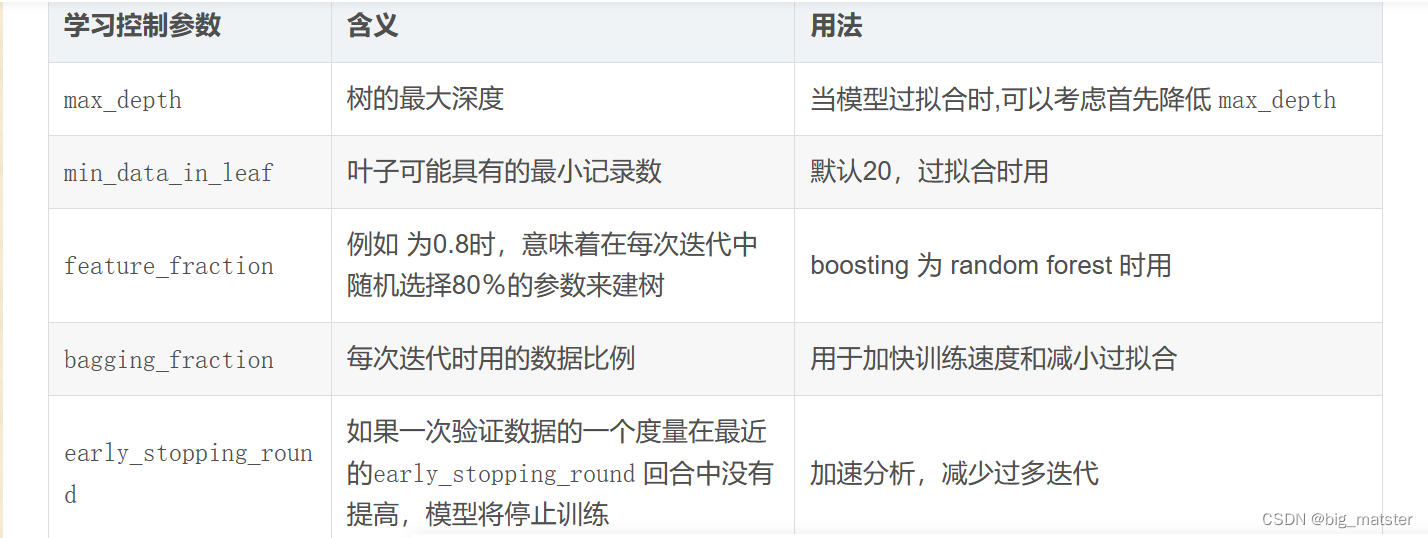

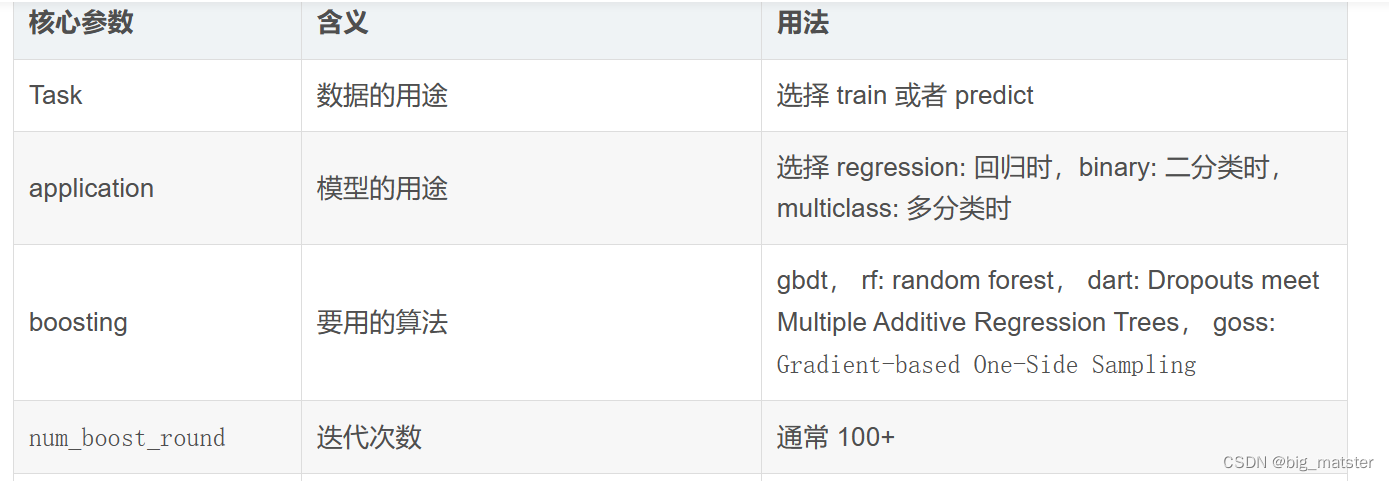
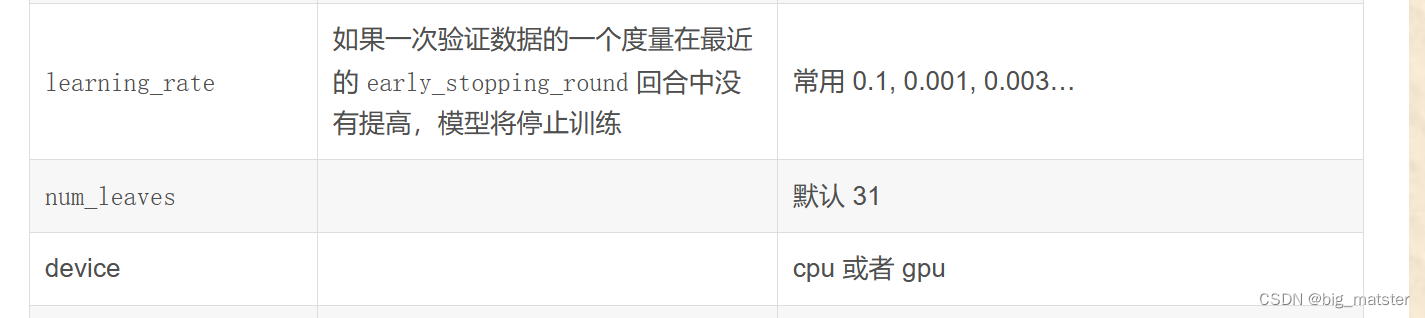

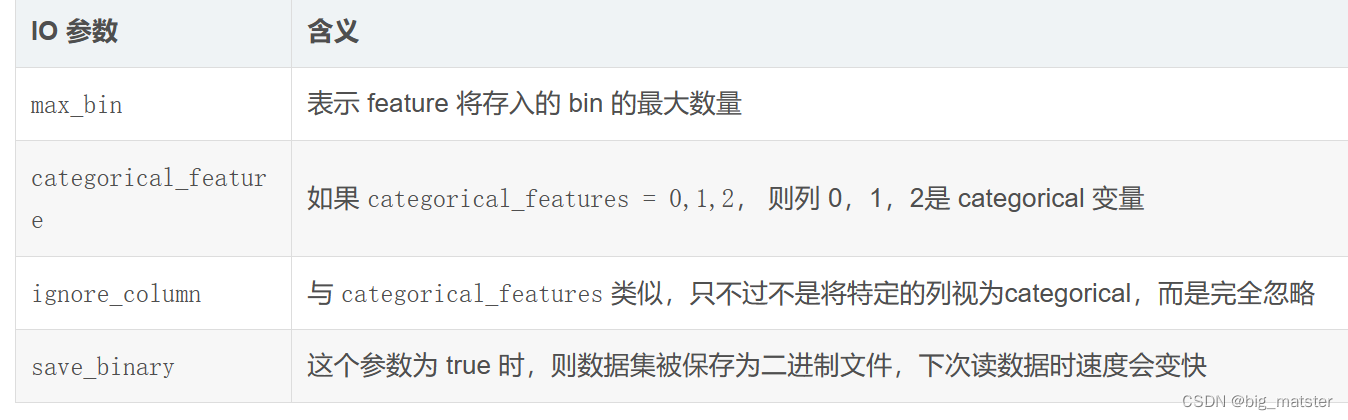
调参
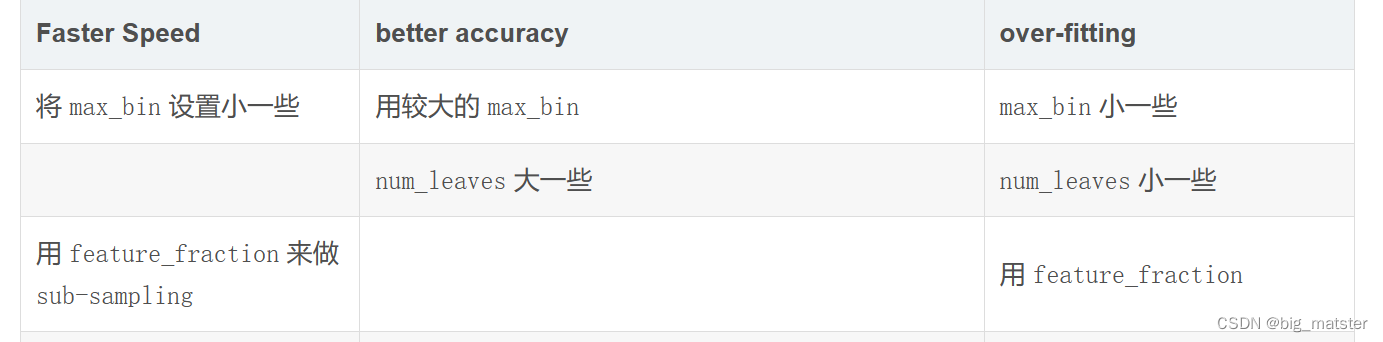
下表对应了 Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数


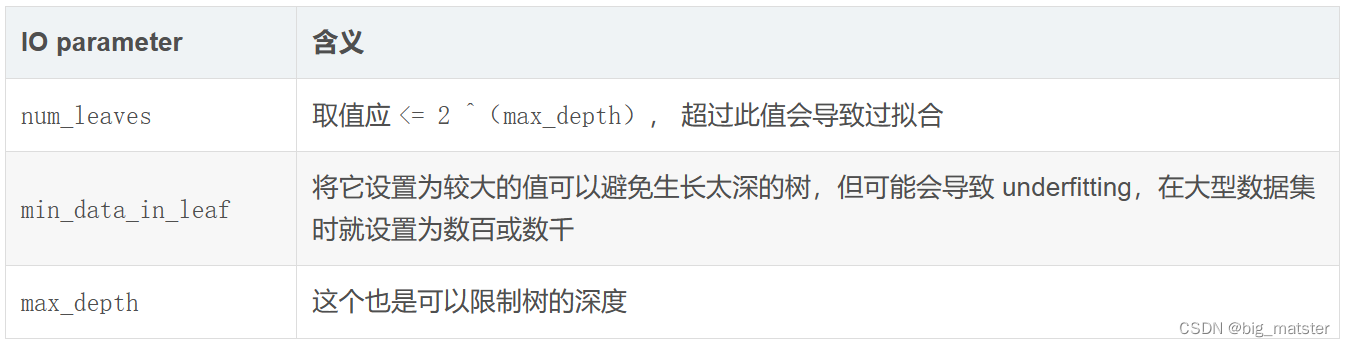
GridSearchCV调参

调参过程
总结
- 自己打比赛的时候,会自己调参,会自己建立模型以及各种的调参。


















 6092
6092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











