




 本文深入探讨了二叉树的中序遍历,包括递归和非递归两种方法。递归方法遵循左子树、根节点、右子树的顺序,而非递归方法利用栈处理左子树,然后处理根节点和右子树。二叉树作为一种重要的数据结构,在计算机科学中有广泛应用,如二叉搜索树、堆、表达式树和哈夫曼树等。二叉树遍历在数据库索引、文件系统、编程语言解析等方面扮演关键角色。
本文深入探讨了二叉树的中序遍历,包括递归和非递归两种方法。递归方法遵循左子树、根节点、右子树的顺序,而非递归方法利用栈处理左子树,然后处理根节点和右子树。二叉树作为一种重要的数据结构,在计算机科学中有广泛应用,如二叉搜索树、堆、表达式树和哈夫曼树等。二叉树遍历在数据库索引、文件系统、编程语言解析等方面扮演关键角色。
一看就会的二叉树的中序遍历解法(递归与非递归)
剑指offer 94. 二叉树的中序遍历
前序遍历传送门
后序遍历传送门
递归
递归思路无非就是左子树、根节点、右子树,代码也较好理解:
class Solution {
public:
void traversal(TreeNode* cur,vector<int>& vec){
if(cur==NULL){return ;}
traversal(cur->left,vec);
vec.push_back(cur->val);
traversal(cur->right,vec);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root,result);
return result;
}
};
重点在于非递归
以这样的树为例:
首先要定义出cur,表示当前节点,初始化为root
vector<int> v;
stack<TreeNode*> st;
TreeNode* cur = root;
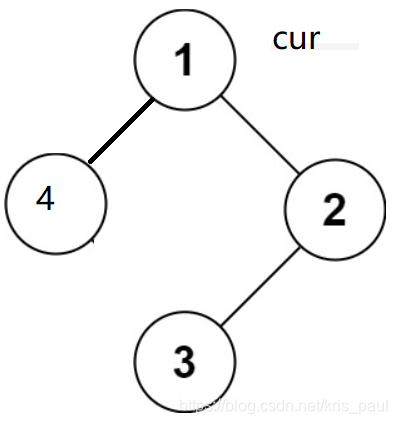
由于中序遍历,最左边的节点一定是第一个要放进去的,我们可以利用栈的特性对结点进行选取,利用vector容器存放结果。
1.从根节点开始,将左边的树全部放进栈,当左边全部放完之后,开始从栈顶一一取出。栈顶每取出一个结点,容器中存放一个:
while(cur||!st.empty()){
//1.左路全部进栈
while(cur){
st.push(cur);
cur = cur->left;
}
//2.取出栈内元素,对左路进行处理
TreeNode* top = st.top();
v.push_back(top->val);
st.pop();
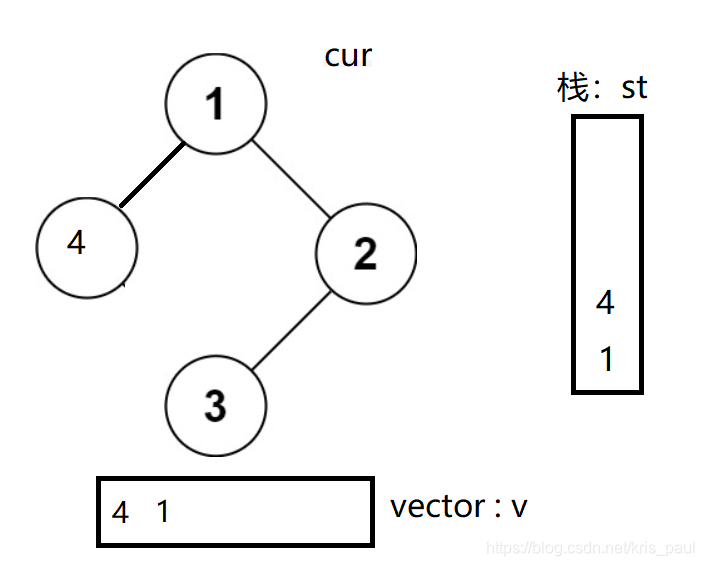
2.让子问题走向右子树
//3.右路->根节点的右子树
cur = top->right;
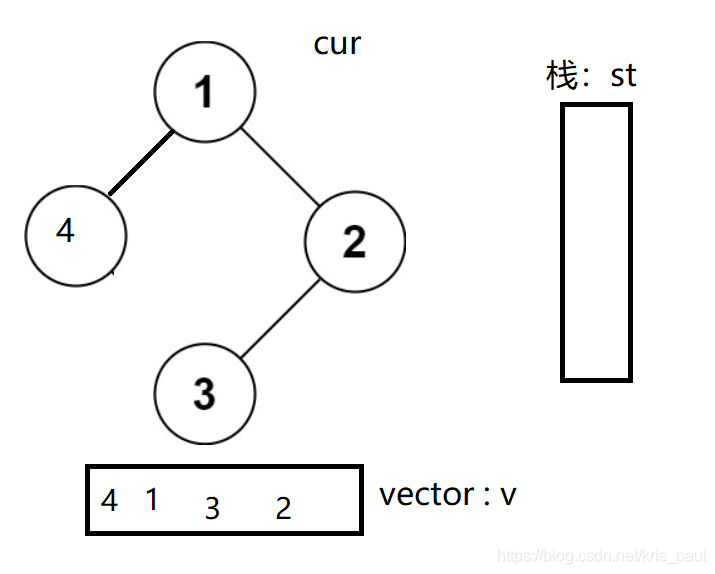
此时,由于st==nullptr,所以结束循环。
代码如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> v;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur||!st.empty()){
//1.左路全部进栈
while(cur){
st.push(cur);
cur = cur->left;
}
//2.取出栈内元素,对左路进行处理
TreeNode* top = st.top();
v.push_back(top->val);
st.pop();
//3.右路->根节点的右子树
cur = top->right;
}
return v;
}
};
二叉树
二叉树(Binary Tree)是一种特殊的树形数据结构,它的每个节点最多有两个子节点,通常被称为左子节点和右子节点。二叉树在计算机科学中非常常见,因为它们具有简单、高效和易于实现的特点。
二叉树的基本性质
- 递归定义:二叉树由根节点、左子树和右子树组成,而左子树和右子树本身也是二叉树。
- 空树:二叉树可以是空的,此时没有节点。
- 度:一个二叉树节点的度是指其拥有的子节点数,二叉树的度最大为2。
- 深度:二叉树的深度(或高度)是从根节点到最远叶子节点的最长路径上的节点数。
- 满二叉树:每一层的节点数都达到最大值的二叉树称为满二叉树。即对于深度为k的满二叉树,总共有2^k - 1个节点。
- 完全二叉树:对于深度为k的,有n个节点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树中编号从1至n的节点一一对应时称之为完全二叉树。
二叉树的表示
在计算机中,二叉树通常可以通过以下方式表示:
- 链式表示:每个节点都有一个指向其左子节点的指针,一个指向其右子节点的指针,以及一个数据域来存储节点的值。
- 数组表示:对于完全二叉树,可以使用数组来存储节点。对于非完全二叉树,也可以使用数组,但会浪费一些空间。
二叉树的遍历
遍历二叉树是指按照某种顺序访问树中的每个节点一次且仅一次。常见的遍历方式有:
- 前序遍历(Pre-order Traversal):先访问根节点,然后遍历左子树,最后遍历右子树。
- 中序遍历(In-order Traversal):先遍历左子树,然后访问根节点,最后遍历右子树。这种遍历方式常用于二叉搜索树。
- 后序遍历(Post-order Traversal):先遍历左子树,然后遍历右子树,最后访问根节点。
- 层次遍历(Level-order Traversal):从根节点开始,按层次从上到下、从左到右遍历节点。这通常需要使用队列来实现。
二叉树的应用
二叉树在计算机科学中有广泛的应用,包括但不限于:
- 二叉搜索树(Binary Search Tree, BST):一种特殊的二叉树,它或者为空,或者满足以下性质:若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;任意节点的左、右子树也分别为二叉搜索树。二叉搜索树常用于实现高效的搜索和排序算法。
- 堆(Heap):一种特殊的完全二叉树,通常用于实现优先队列。堆分为最大堆和最小堆,其中最大堆的父节点的值总是大于或等于其子节点的值,而最小堆的父节点的值总是小于或等于其子节点的值。
表达式树(Expression Tree):用于表示数学表达式的一种二叉树。表达式树的叶子节点表示操作数,非叶子节点表示运算符。通过遍历表达式树,可以计算表达式的值。 - 哈夫曼树(Huffman Tree):一种特殊的二叉树,常用于数据压缩中的霍夫曼编码。它根据字符的出现频率构建树,频率高的字符离根节点较远,频率低的字符离根节点较近。通过霍夫曼编码,可以用较短的编码表示频率高的字符,用较长的编码表示频率低的字符,从而实现数据压缩。
应用场景
二叉树在计算机科学和相关领域中有着广泛的应用。以下是一些主要的应用场景:
- 数据库系统:
- 二叉树被广泛应用于数据库系统中的索引结构,如二叉搜索树(Binary Search Tree, BST)和平衡二叉树(如AVL树、红黑树)。这些结构可以显著提高数据的检索效率。
- 常见的索引结构还包括B树和B+树,它们都是二叉树的变种,特别适用于磁盘文件组织和数据库索引。
- 文件系统:
- 在文件系统中,目录和文件可以组织成一棵树状结构,其中每个目录是一个节点,文件是叶子节点。通过二叉树的结构,可以方便地对文件和目录进行管理和查找。
- 特定的树结构如B树和B+树也被用于文件系统的目录结构,能够高效地组织和管理文件系统中的数据。
- 编程语言:
- 在编程语言中,二叉树被广泛应用于解析和生成语法树。语法树是一种表示程序语法结构的树状结构,其中二叉树是语法树的一种常见形式。
- 通过构建语法树,编译器可以将源代码转换为可执行代码。
- 图形学:
- 在计算机图形学中,二叉树可以用于构建几何图形的数据结构。例如,二叉树可以用于实现三角网格的分割和细分,其中每个节点表示一个三角形。
- 此外,二叉树也可以用于场景图(Scene Graph)的表示,用于管理和渲染三维场景中的对象。
- 人工智能:
- 决策树是一种特殊的二叉树,广泛应用于机器学习和数据挖掘中的分类和决策问题。
- 搜索树(如二叉搜索树)也是实现最优解搜索的关键数据结构。
- 操作系统:
- 在操作系统中,进程调度和资源管理可能使用树结构来组织和管理进程。尽管不一定是二叉树,但树形结构在此类应用中非常常见。
- 游戏开发:
- 在游戏中,空间分区树(如四叉树和八叉树)常用于加速空间查询和碰撞检测。这些树形结构通过将空间划分为更小的区域来优化性能。
- 密码学:
- Merkle树是一种二叉树结构,被广泛用于区块链中的交易验证和Merkle证明。它提供了一种高效的方式来验证大量数据的完整性和一致性。
- 网络和通信:
- Huffman编码树用于数据压缩,而霍夫曼解码树用于解压缩。这种编码方式通过构建二叉树来优化数据的编码长度,从而实现高效的数据压缩。
- 系统设计:
- 二叉搜索树和其他类型的二叉树也常被用于系统设计中的各种算法和数据结构中,以实现快速查找、插入和删除等操作。
总结来说,二叉树因其结构特性和效率优势,在计算机科学的多个领域都有着广泛的应用。无论是在数据检索、编译优化、图形渲染,还是在人工智能、操作系统、游戏开发和密码学等领域,二叉树都发挥着关键的作用。



















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











