




Logistic Regression
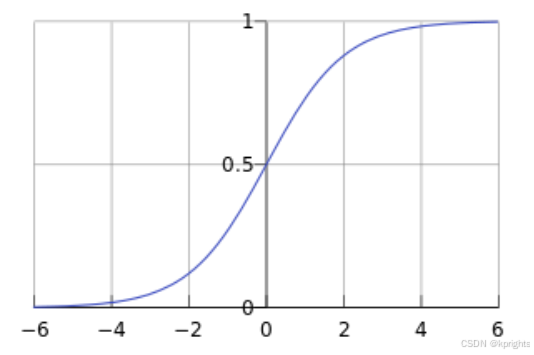
逻辑回归(Logistic Regression,简称 LR)虽然名为 “回归”,但实际上是一个分类问题。它主要用于二分类,通过逻辑函数 ——Sigmoid 函数来实现。显然,Sigmoid 函数的值域在 (0, 1) 之间。通常,以 0.5 作为阈值,当函数值低于 0.5 时,将观察到的输入集分类为 “0” 类,反之则为 “1” 类。Sigmoid 函数呈现出典型的 S 形曲线。
逻辑回归分类器旨在从输入训练数据的特征中学习一个二分类模型。该模型将输入特征的线性组合作为变量,即θ0+θ1x1+,…,+θnxn=∑i=1nθixi\theta_0+\theta_1x_1+,\ldots,+\theta_nx_n=
\sum_{i=1}^n \theta_ix_iθ0+θ1x1+,…,+θnxn=∑i=1nθixi,其中 x0x_0x0 始终为 1。我们也可以将其表示为 θTx\theta^TxθTx。将其代入 Sigmoid 函数,得到如下预测模型:
hθ(x)=g(θTx)=11+e−θTx
h_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=g(θTx)=1+e−θTx1
逻辑回归最终将组合变量映射到 (0, 1) 区间,以确定输入特征所属的类别。
为了训练这样一个逻辑模型,我们需要构建一个合理的损失函数。但在此之前,我们首先定义类别(0 或 1)的概率如下:
P(y=1∣x;θ)=hθ(x)P(y=1∣0;θ)=1−hθ(x)
\begin{equation} \begin{aligned}&P(y=1\mid x;\theta)=h_\theta(x)\\&P(y=1\mid 0;\theta)=1-h_\theta(x)\end{aligned}\end{equation}
P(y=1∣x;θ)=hθ(x)P(y=1∣0;θ)=1−hθ(x)
这意味着对于一组表示为 xix_ixi 的输入特征及其相应的标签 ,在 xix_ixi 条件下 yi=1y_i = 1yi=1 的概率为 pip_ipi ,因此 yi=0y_i = 0yi=0 的概率为 1−pi1-p_i1−pi。 因此,我们可以将这两种情况结合起来,得到一个统一的概率函数:
P(y)∣x;θ)=(hθ(x))y(1−hθ(x))1−y
P(y)\mid x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y}
P(y)∣x;θ)=(hθ(x))y(1−hθ(x))1−y
此外,对于 m 个输入特征 x1,x2,......,xmx_1, x_2, ...... , x_mx1,x2,......,xm,联合概率就是在每个 xix_ixi 条件下 yiy_iyi 的概率的乘积,如下所示:
L(θ)=∏i=1mP=(yi∣xi;θ)=∏i=1m(hθ(xi))yi(1−hθ(xi))1−yi
L(\theta)=\prod_{i=1}^{m}{P=(y_i\mid x_i;\theta)}=\prod_{i=1}^{m}(h_\theta(x_i))^{y_i}(1-h_\theta(x_i))^{1-y_i}
L(θ)=i=1∏mP=(yi∣xi;θ)=i=1∏m(hθ(xi))yi(1−hθ(xi))1−yi
逻辑回归(LR)的目的是获得一组最优的参数集 θ\thetaθ ,使得 L(θ)L(\theta)L(θ)达到最大值。其取对数形式,得到 l(θ)l(\theta)l(θ) 如下:
l(θ)=logL(θ)=∑i=1m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))
l(\theta)=\log{L(\theta)}=\sum_{i=1}^m \Big(y_i\log h_\theta(x_i)+(1-y_i)\log \big(1-h_\theta(x_i)\big)\Big)
l(θ)=logL(θ)=i=1∑m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))
如果我们将 l(θ)l(\theta)l(θ) 视为损失函数,训练逻辑回归问题应该使用梯度上升的方式,因为 l(θ)l(\theta)l(θ) 越大越好。如果我们想要最小化损失函数(以符合主流的机器学习训练方法),可以简单地使用其负数,即 J(θ)=−1m∗l(θ)J(\theta)=-\frac{1}{m}*l(\theta)J(θ)=−m1∗l(θ),并且可以使用梯度下降来进行参数优化:θj:=θj−αδδθjJ(θ)\theta_j:=\theta_j-\alpha\frac{\delta}{\delta_{\theta_j}}J(\theta)θj:=θj−αδθjδJ(θ)
其中:
δδθjJ(θ)=−1m∑i=1m(yi1hθ(xi)δδθjhθ(xi)−(1−yi)11−hθ(xi)δδθjhθ(xi))=−1m∑i=1m(yi1g(θTxi))−(1−yi)11−g(θTxi))δδθjg(θTxi)=−1m∑i=1m(yi1g(θTxi))−(1−yi)11−g(θTxi))g(θTxi)(1−g(θTxi))δδθjθTxi=−1m∑i=1m(yi(1−g(θTxi))−(1−yi)g(θTxi))xij=−1m∑i=1m(yi−g(θTxi))xij=−1m∑i=1m(hθ(xi)−yi))xij
\begin{aligned}&\frac{\delta}{\delta_{\theta_j}}J(\theta)=-\frac{1}{m}\sum_{i=1}^m \Big(y_i\frac{1}{h_\theta(x_i)}\frac{\delta} {\delta_{\theta_j}}h_\theta(x_i)-(1-y_i)\frac{1}{1-h_\theta(x_i)}\frac{\delta}{\delta_{\theta_j}}h_\theta(x_i)\Big)\\&=-\frac{1}{m}\sum_{i=1}^m \Big(y_i\frac{1}{g(\theta^Tx_i)})-(1-y_i)\frac{1}{1-g(\theta^Tx_i)}\Big) \frac{\delta}{\delta_{\theta_j}}g(\theta^Tx_i)\\&=-\frac{1}{m}\sum_{i=1}^m \Big(y_i\frac{1}{g(\theta^Tx_i)})-(1-y_i)\frac{1}{1-g(\theta^Tx_i)}\Big) g(\theta^Tx_i)\big(1-g(\theta^Tx_i)\big)\frac{\delta}{\delta_{\theta_j}}\theta^Tx_i\\ &=-\frac{1}{m}\sum_{i=1}^m \Big(y_i\big(1-g(\theta^Tx_i)\big)-(1-y_i)g(\theta^Tx_i)\Big)x_i^j\\&=-\frac{1}{m}\sum_{i=1}^m\Big(y_i-g(\theta^Tx_i)\Big)x_i^j\\&=-\frac{1}{m}\sum_{i=1}^m\Big(h_\theta(x_i)-y_i)\Big)x_i^j \end{aligned}
δθjδJ(θ)=−m1i=1∑m(yihθ(xi)1δθjδhθ(xi)−(1−yi)1−hθ(xi)1δθjδhθ(xi))=−m1i=1∑m(yig(θTxi)1)−(1−yi)1−g(θTxi)1)δθjδg(θTxi)=−m1i=1∑m(yig(θTxi)1)−(1−yi)1−g(θTxi)1)g(θTxi)(1−g(θTxi))δθjδθTxi=−m1i=1∑m(yi(1−g(θTxi))−(1−yi)g(θTxi))xij=−m1i=1∑m(yi−g(θTxi))xij=−m1i=1∑m(hθ(xi)−yi))xij
Vectorization
参数优化过程可以进行向量化,这在全同态加密(FHE)中非常重要。我们可以使用以下过程进行向量化:
首先,我们将 m 个输入向量 重新构造成针对每个观测特征的更细粒度的特征矩阵,输出类别 yyy 和参数集 θ\thetaθ 也类似处理:
 每个特征 xix_ixi 和参数集 θ\thetaθ 的线性组合可以表示为矩阵 - 向量乘法。得到的矩阵 AAA 作为 Sigmoid 函数 ggg 的输入:
每个特征 xix_ixi 和参数集 θ\thetaθ 的线性组合可以表示为矩阵 - 向量乘法。得到的矩阵 AAA 作为 Sigmoid 函数 ggg 的输入:
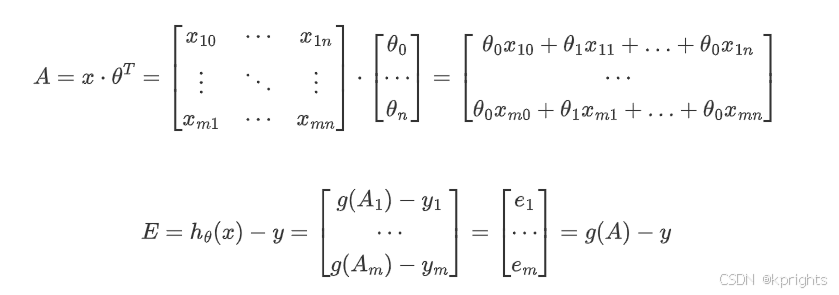
EEE 是观测标签 yyy (0 或 1)与通过 Sigmoid 函数根据 xxx 得到的预测概率之间的误差(或损失)。因此,最终的优化过程如下所示:
θj:=θj−α1m∑i=1m(hθ(xi)−yi))xij=θj−α1m∑i=1meixij=θj−α1mxjTE
\theta_j:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^m\big(h_\theta(x_i)-y_i)\big)x_i^j=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^me_ix_i^j=\theta_j-\alpha\frac{1}{m}x^{jT}E
θj:=θj−αm1i=1∑m(hθ(xi)−yi))xij=θj−αm1i=1∑meixij=θj−αm1xjTE
Implementation
后续会介绍,使用Poseidon同态加密库实现 Logistic Regression。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









