



IWA社交网络的结构分析
刘文鹏、曹亚南(✉)、李迪英、牛文佳、谭建龙、胡月和郭莉
中国科学院信息工程研究所,中国北京 {liuwenpeng,caoyanan,lidiying,niuwenjia,tanjianlong,huyue,guoli}@iie.ac.cn
1 引言
随着国内社交媒体(如论坛和微博)的兴起,越来越多的互联网用户加入社交网络平台。然而,社交平台的开放性和快速传播也催生了一个被称为隐性有偿发帖者的利益驱动群体,即中国所谓的网络水军(IWA)¹。由于网络水军通过发布不负责任的观点进行公众引导而产生负面影响,因此受到越来越多的关注。网络水军(IWA)指的是“大量有组织地在互联网上发布带有特定目的的评论和文章的人群。”[4]在经济利益或其他目的驱动下,企业和个人倾向于雇佣互联网用户发表评论,制造热门话题,以提升人气。这种方式使得这些有目的的用户发布的文章或言论形成片面态度,影响普通用户的认知或决策。许多由水军引发的轰动性事件反映了网络水军的恶劣影响,例如蒙牛陷害伊利事件、《鸿门宴》影评事件。总体而言,网络水军承担各种各样的发帖任务。
¹ http://en.wikipedia.org/wiki/Internet_水_军队。
正常状态,通常被称为网络大号。此外,他们极有可能成为广泛传播负面谣言的潜在群体。因此,建立网络水军黑名单库以积累相关数据并学习网络水军结构与行为规则具有重要意义。
以往关于网络水军的研究主要集中在水军检测问题上,而我们的研究则聚焦于水军网络结构的分析。从经验来看,网络水军拥有大量成员,每个成员控制着多个拥有大量粉丝的账号。此外,成员的主账号会与其他水军用户或普通用户进行互动,以隐藏网络水军的身份。基于这些现象,我们认为诊断网络水军与普通用户之间的关系具有重要意义。众所周知,社区结构被认为是现实世界和虚拟世界网络中的一个重要特性,因为它通常揭示了网络中节点之间的相互关系。针对社区结构检测这一普遍性问题,多年来已有众多学者进行了研究,并取得了良好成果,相关研究综述将在下一节中进行描述。为了更好地分析网络水军,我们提出了IWA社交网络的概念。
IWA社交网络是一种与自然社交网络完全不同的非自然社交网络。需要注意的是,我们提到的自然社交网络是指成员由于具有相同兴趣、在同一公司工作或其他共同的内在属性而通过关注、转发等方式相互连接的网络。而本文提出的IWA社交网络则是指基于网络水军扩展形成的特殊群体,换句话说,这些成员因承接带来经济利益的任务而聚集在一起。
我们通过爬取一个任务发布网站,获得了数千个经证实确为网络水军的新浪微博账号。在该网站上,雇主发布带有报酬的发帖任务,大号选择任务进行完成,并上传证明图片以获取报酬。随后,我们根据一些规则对这些账号的数据进行了筛选。基于这些筛选后的账号,我们在新浪微博上爬取了更多与之有关联的账号。接着,我们采用两种典型方法对所有这些节点进行社区检测。经过实验,我们发现所发现的IWA社交网络在社区结构上与以往研究中的自然网络相比具有特殊性。
2 相关工作
先前的研究关于网络水军主要集中在网络水军检测或类似的身份识别,如论坛和博客垃圾信息发送者。大多数研究通过建立分类器来检测网络水军。辛等人[2]基于垃圾信息发送者的IP、评论活动以及一些特征开发了轻量级特征,用于训练SVM分类器,并在识别论坛垃圾信息方面取得了良好效果。陈等人[4]设计了一种新的检测机制,结合了非语义分析和语义分析。他们使用新浪微博数据集训练分类器,并在测试搜狐数据集时表现出有希望的性能。最近,徐等人[5]提出了一种基于SVM主动学习的新型突发性话题分类算法,该方法基于发现由水军推动的话题在其延迟阶段表现出与一般话题不同的特征。仍有一些研究人员在不使用分类器的情况下探索这一问题。在论坛和博客垃圾信息发送者的识别问题上,李等人[1]利用文本情感分析来辨别网络骗子。他们分析信息发布者的情感倾向,然后通过计算正面和负面情绪的比例来确定作者身份。在工作[3]中,作者关注标签组,发现如果垃圾信息发送者在为产品撰写评论时具有相似的行为,则可以检测到这些垃圾信息发送者的标签组。
尽管如此,先前的研究在垃圾信息发送者方面已经取得了不错的成果,幸运的是,大多数方法和技术仍然可以用于水军检测。然而,仍有一些问题需要注意并加以改进。即使结合了各种方法和分析技术的新方法在检测水军方面取得了更令人满意的效果,但所选择的特征和阈值过于主观。此外,由于水军身份无法被证实,他们所使用的数据集要么不确定(通过个人经验标注),要么规模太小,更不用说经过验证了。
为了解决上述两个问题,我们尝试对水军的结构与行为进行深入分析。此外,还可进一步开展网络水军的影响分析和传播预测研究。众所周知,只有当水军以集体形式行动时,才能按照其意愿引导和影响公众舆论。因此,我们对水军内部的互动情况十分关注,并试图在他们之间发现类似自然社交网络的社区。社区结构被认为是现实世界和虚拟世界网络的重要特性,因为它通常揭示了构成网络的节点之间的相互关系。因此,我们将应用一些社区检测算法于水军网络中。
随着Facebook、Twitter和新浪微博等大规模社交网络的迅速兴起,社交网络分析已成为一个热门课题。各类社区检测算法被不断提出并日趋完善和成熟。总体而言,网络中的相关算法可分为两类:非重叠社区检测(也称传统社区检测)和重叠社区检测。对于传统社区检测,各种算法已经发展得较为成熟。
其中最具代表性的分裂算法是由吉尔瓦恩和纽曼提出的[10]。同时,模块度这一重要新概念也被提出,随之涌现了许多属于基于模块度的方法的模块度优化算法。例如,本文中我们用于分析网络水军社交网络结构的纽曼提出的FN算法[9],就是模块度优化方法中的一种贪婪技术。至于重叠社区检测,由于更贴近现实,近年来成为研究热点。其中最流行且最具原创性的技术之一是派系渗透方法(CPM)[7]。“该方法基于这样一个概念:由于社区内部具有高密度特性,其内部边很可能形成派系。”[12]显然,CPM无法很好地划分稀疏网络。
3 我们的方法
3.1 IWA社交网络的基本概念
在以往的社交网络研究中,大多数研究人员关注的是成员因其内在特征而自发聚集的社区或组织。我们称之为自然社交网络。例如,人们可以根据相同的爱好(如足球、某位电影明星或某部电视剧)或所参与的相同组织(如同一所学校或公司)被划分为一个社区。
为了深入研究网络水军的分布和行为特征,我们提出了一种新型社交网络,称为IWA社交网络。该特殊网络包含两类节点:以网络水军作为核心节点,以及与网络水军互动的普通用户作为扩展节点。也就是说,这种非自然社交网络中的核心节点由于经济利益或有目的的互动而与其他节点建立联系。此外,这些经济利益是通过完成发布虚假言论的推广任务而获得的。
就IWA社交网络的特征而言,目前可以总结出以下几点。我们认为,网络水军包含一组成员,每个成员控制着多个拥有大量粉丝的账号。为了维持信息传播并伪装成普通用户,在这些账号中存在水军成员的主账号,它们与包括网络水军和普通用户在内的其他用户进行联系。通过这种方式,网络水军能够与普通用户建立关系。然而,上述陈述是基于我们对网络水军调查得出的假设。
后续的一系列实验将验证我们的假设。
目前,我们给出将在整篇文章中使用的基本定义。
定义1 给定一个IWA社交网络 WAG = {E, V}
- V = {v₁, v₂, …, vₙ} 是一个包含 n 个节点的集合,表示网络水军及其相关的普通用户;
- E = {e₁, e₂, …, eₘ} 是一个包含 m 条边的集合,表示节点之间的关系。
WAG 是一个无向无权稀疏图。该网络结构由邻接矩阵 A 定义。邻接矩阵 A 中的每个元素 Aᵢⱼ 等于 1,表示节点 i 和 j 之间存在边。在非自然社交网络中,V 是由水军账号及其关联账号组成的节点集合,Aᵢⱼ 等于 1 表示账号 i 和 j 之间存在连接(关注与被关注)。
3.2 IWA社交网络构建
IWA社交网络是一种不同于自然社交网络的非自然社交网络。UNSN的构建通常经历三个阶段,本小节将对此进行介绍。
数据爬虫
首先,我们需要获取大量包含已被证实为水军的账号的数据。经过一段时间的调查,我们发现了一些网站被雇主用来发布任务。随后,大号(水军成员的简称)会在该网站上完成并提交任务以获取报酬。从任务列表中,我们可以浏览每页按时间从新到旧排序的50个任务标题。点击进入每个任务主题后,可以获取该任务的所有详细信息,例如任务要求、每个大号响应的完成状态等。令人欣慰的是,所有大号都会在新浪微博上公开他们的账号和发帖地址,以便进行任务核查。
基于这一发现,我们可以随意爬取数据。在爬取阶段,采用多线程和分布式技术来提升爬虫程序的性能和响应速度。此外,为了避免被封禁,我们通过切换代理IP来爬取数据。所使用的代理IP是从之前为其他项目构建的IP代理池中依次选取的。
数据清洗
我们计划在此阶段对数据进行筛选,以防第一阶段抓取的账号是孤立的。
目前,我们已经获得了大量参与网络水军推广任务的账号。我们预测,所爬取的大部分账号在网络中是孤立的。换句话说,许多大号在社交网络中与其他用户的互动行为较少。显然,划分这些孤立节点及其相关节点是没有意义的。
鉴于这种情况,我们制定了一条规则来过滤原始数据。
为此,我们构建了活动评估的结构模型和判断矩阵来评估节点的活跃度。设定阈值V₀作为过滤基准,然后移除那些Vᵢ低于V₀的节点。在对原始数据进行过滤后,保留下来的节点作为源节点,以备后续扩展。
数据扩展
目前,我们已掌握了一些参与水军任务且具有正常活跃度的账号。下一步计划是基于这些特殊节点来扩大我们的IWA社交网络。
与3.1节中的工作类似,本阶段的工作通过爬虫完成。不同之处在于,我们在此处爬取的主要信息是节点之间的边,而不是节点本身的信息。此外,如何判断两个节点之间是否存在边也至关重要。例如,扩展节点可以沿着源节点的评论、转发、关注和粉丝进行爬取,这些分别属于深度和广度方向。
完成此阶段后,IWA社交网络的构建已经完成。
3.3 社区检测算法
非重叠社区检测和重叠社区检测均用于对我们的网络进行完整分析的测试。FN算法作为一种基于模块度优化的经典方法,具有较高的准确性和效率。此外,无论网络是稠密或稀疏图,FN算法都能对其进行划分。因此,我们更倾向于选择严格的社区检测要求作为对比实验。因此,我们选择分别属于非重叠和重叠社区检测的FN算法和CPM算法作为实验算法。然后将对这两种方法进行回顾,以准备实验。
FN算法
FN算法基于模块度优化的思想。其详细说明见[9]。我们将算法简化为以下步骤。
从每个顶点各自属于一个包含 n 个社区的状态开始,k 初始化为 n。
- 步骤1 :根据质量函数或“模块度”计算所有社区的Q值。是网络中连接第i组顶点与第j组顶点的边所占的比例,然后Q定义为
- 步骤2 :选择社区i和j,使得Q值增加最大,我们将其定义为
- 步骤3 :将组i和j合并为一个新组。同时,k加1。
- 终止条件 是k等于1,否则跳转到步骤1。
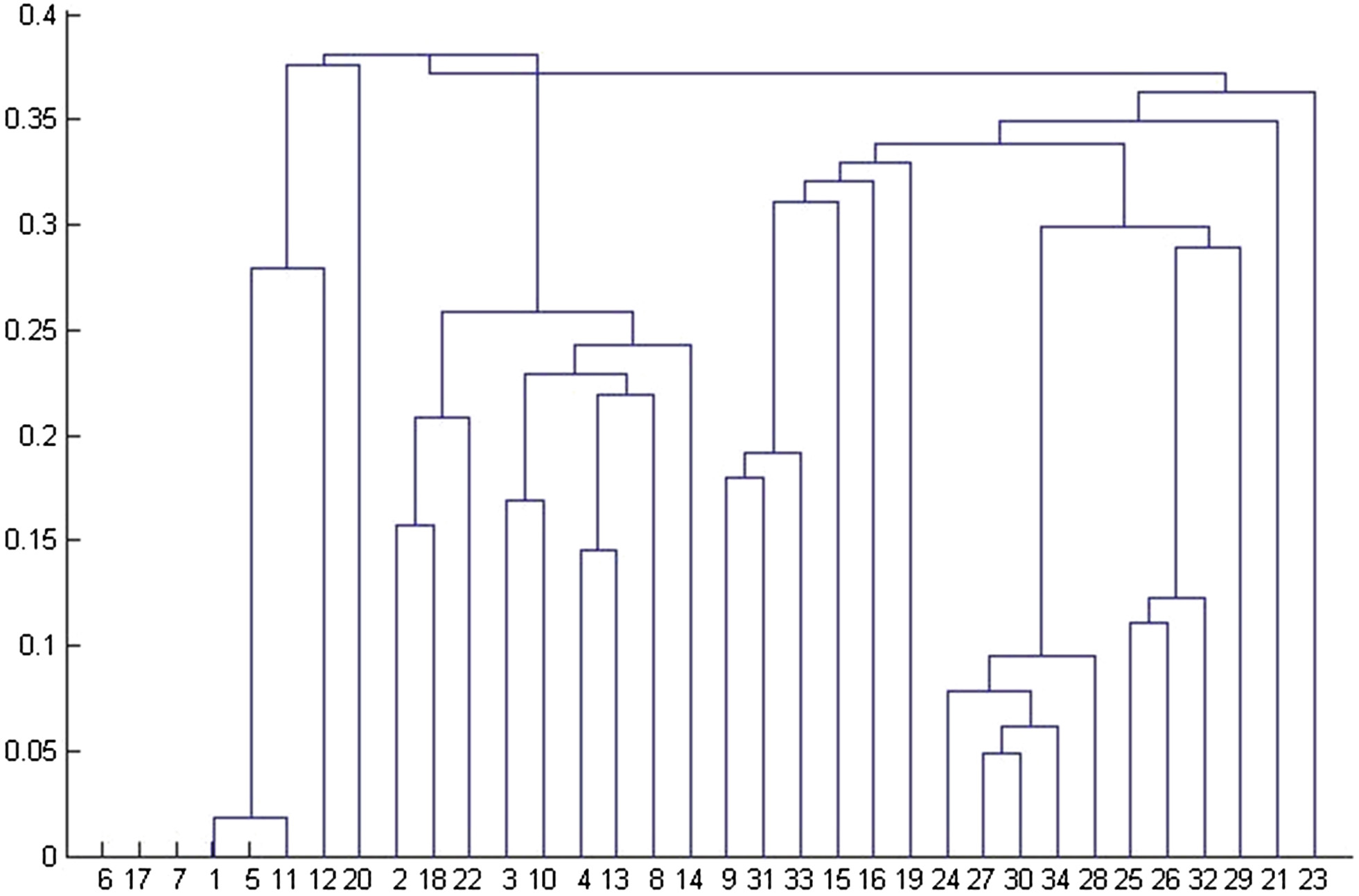
在图1中,我们展示了将“空手道俱乐部”网络输入FN算法后得到的树状图。峰值模块度为 Q = 0.381,对应划分为两个组。
CPM算法
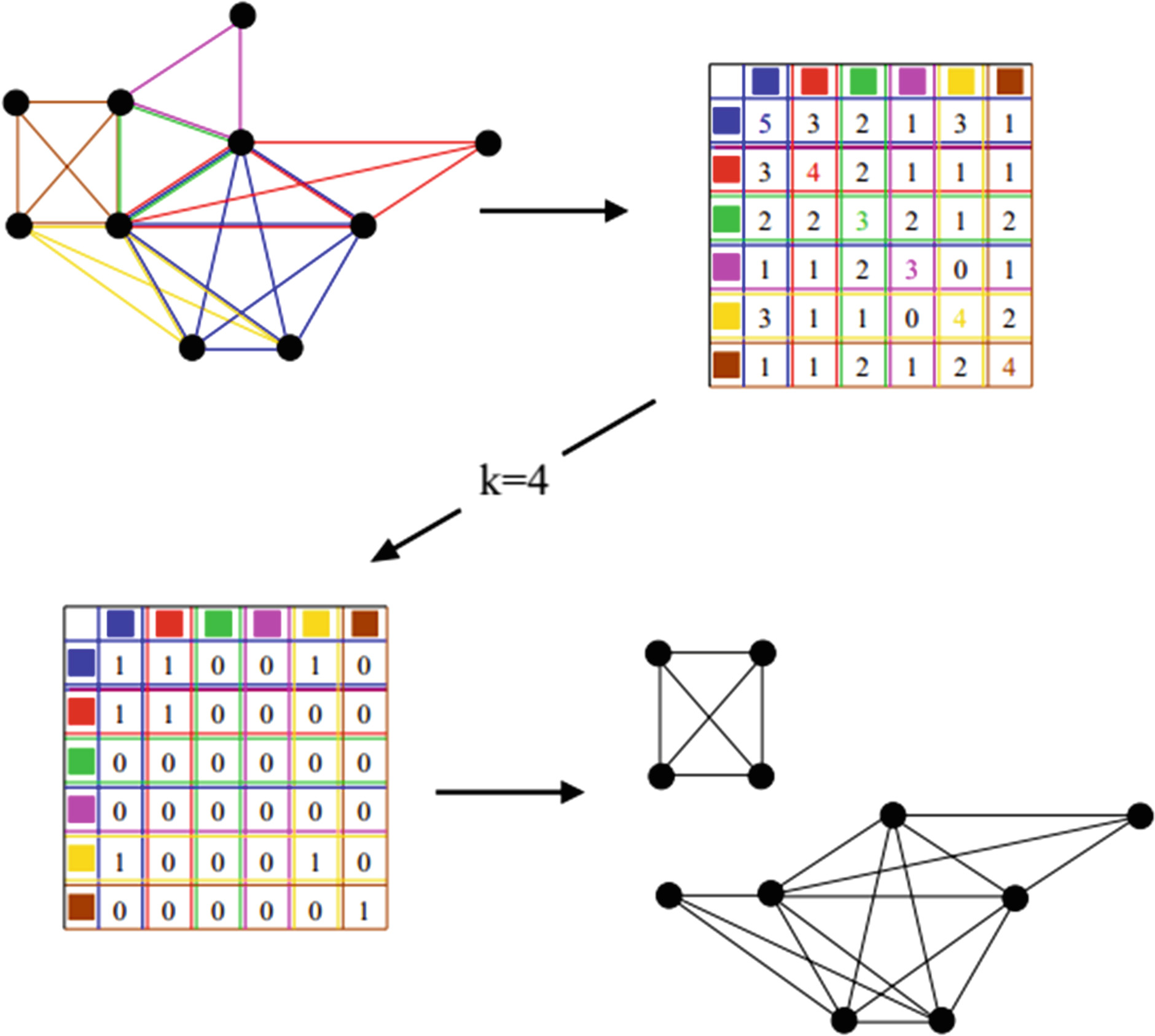
派系渗透方法(CPM)基于社区由重叠的完全连接子图构成这一假设,并通过搜索相邻的派系来检测社区。完整描述见[7],简单的示意图见图2。
为简洁起见,我们还简化了该过程并在下方进行说明:
- 首先提取网络的所有完全子图,这些子图简称为派系。
- 构建团簇‐团簇重叠矩阵,其中矩阵元素等于相应两个派系之间共有节点的数量。
- 将每个小于k的非对角线元素−1以及每个小于k的对角线元素替换为0,其余元素替换为1。
4 实验
4.1 数据设置
作为最受欢迎的在线社交网络之一,新浪微博已有超过5亿活跃用户。它积累了大量的数据可供挖掘和分析,包括水军。因此,我们将重点关注新浪微博,进行数据爬取和实验。
在该任务发布网站中,我们重点关注新浪微博的任务板块并开始数据爬取。
经过十天的爬取,数据库中已获得近2.3万个账号和120万条任务记录。部分样本见 http://202.43.148.168:18080/washow/servlet/Show。这些丰富的IWA数据为识别水军账号提供了确凿的证据。
我们获得了参与网络水军推广任务的2.3万个账号。然而,我们爬取的大多数账号在网络中是孤立的,因此我们制定了一条规则来过滤原始数据。明确我们的目标是找出那些社交行为较少的账号并将其剔除。为此,我们构建了一个活动评估的结构模型。
以及判断矩阵来识别目标节点。结合该结构模型和判断矩阵,我们使用层次分析软件yaahp得到结构模型中8个属性的各自权重。所有属性及其权重如表1所示。其中C8表示互动率,等于N₁/N₂,N₁指用户i评论或回复其他用户的帖子数量,N₂指用户i被评论或被回复的帖子数量。为每个属性设置阈值并进行归一化处理。计算原始数据中每个账号的活跃度值等于,其中表示节点i在特征Cₙ上可获得的比率值。
| Type | 特征 | 描述 | 权重 |
|---|---|---|---|
| 个体 | C1 | 个人资料 | 0.008 |
| 个体 | C2 | 注册时间 | 0.063 |
| 个体 | C3 | 用户等级 | 0.401 |
| 个体 | C4 | 角色标签 | 0.203 |
| 互动 | C5 | 粉丝数量 | 0.032 |
| 互动 | C6 | 关注数量 | 0.012 |
| 互动 | C7 | R‐好友数量 | 0.113 |
| 互动 | C8 | 互动率 | 0.168 |
然后,我们可以移除那些Vᵢ低于阈值V₀的节点。在过滤原始数据后,大约保留了50个账号作为源节点,准备进行扩展。
目前,我们已获取了50个参与水军任务且具有正常活跃度的账号。随后,基于这些特殊节点扩展我们的IWA社交网络。我们在此爬取的主要信息是节点之间的边,而非节点本身的信息。扩展节点是沿着源节点的评论、转发以及关注和粉丝关系进行爬取的,分别对应深度和广度方向。通过基于这50个水军账号的几天数据爬取,共获得9000个节点和15000条边。
4.2 实验结果与分析
我们得到了一个包含9000个节点和15000条边的网络,其中特别地,有50个账号已被证实具有水军身份。在本节中,我们将使用第2.2节回顾的两种经典算法对IWA社交网络进行划分。同时,我们将描述我们的发现,并尝试解释相关现象。
首先,如图3(a)所示,FN方法与CPM方法在社区划分结果上存在显著差异。使用FN算法得到了26个社区,而使用CPM算法仅得到11个社区。此外,FN划分出的每个社区所包含的成员数量远多于CPM划分出的社区。由于两种方法的社区检测原理不同,特别是对于本研究所构建的这种稀疏网络类型的IWA社交网络,FN相比CPM更容易划分出大规模社区,这一点不难理解。另一方面,我们可以观察到,在应用CPM方法时,网络中的大多数节点并未被划分到任何社区中。此外,在实验结果中,只有当k = 3时才能发现社区,如图4(a)所示。
因此,我们充分认识到,大多数水军并未融入社交圈,只有一小部分水军与其他成员保持密切联系,从而形成了社区。
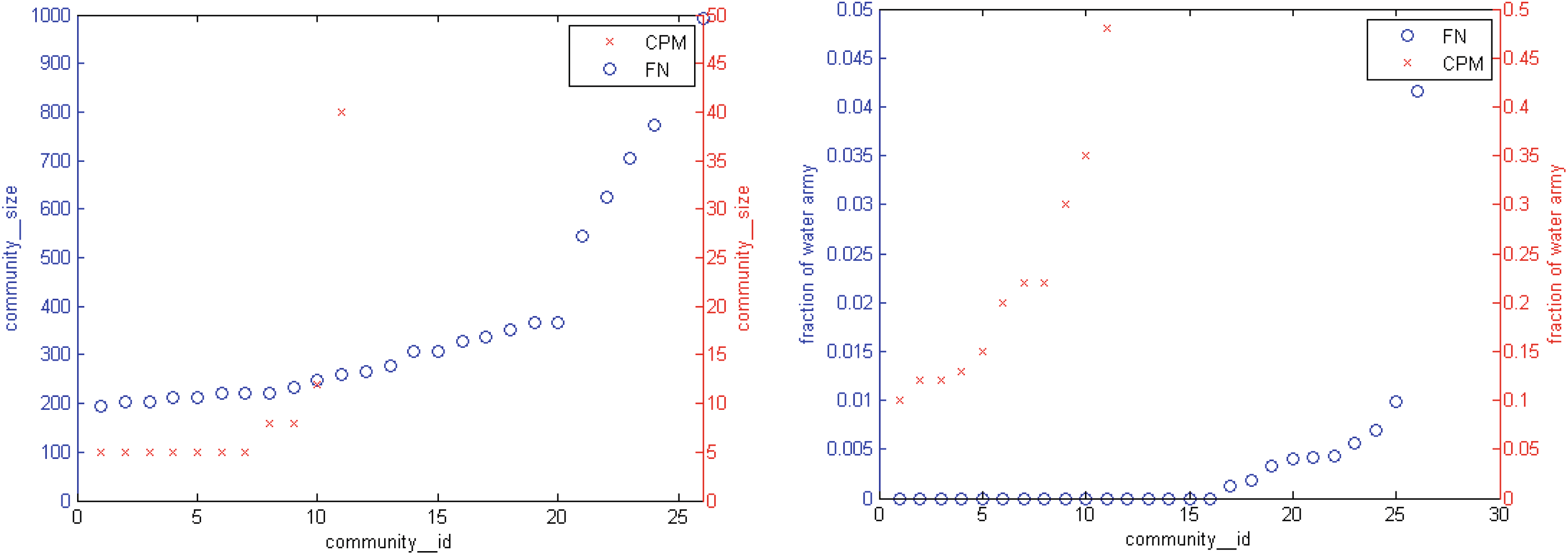
其次,从图3(b)所示的统计结果中,我们可以观察到在FN和CPM划分结果中每个社区的水军账号比例。通过追踪最高比例中的所有水军账号,我们发现一种惊人的现象。这些账号的主页内容彼此非常相似,在它们的微博中,存在大量在相近时间发布的相似甚至相同的内容或转发。我们可以设想两种情况:一种是它们属于同一个网络水军群体,另一种是这些相似的账号由同一个人持有。为了确认这一现象的普遍性还是偶然性,我们监测了其他高比例非法网络活动账号,结果相同。
根据我们的经验,这并不难解释。一旦同一个网络水军群体中的账号被抓取,由于它们之间的关联,这些账号应被划分到同一个社区中,因此该社区会具有较高比例的非正常账号。另一方面,低比例社区中的发帖者通常是个体独立完成任务的。
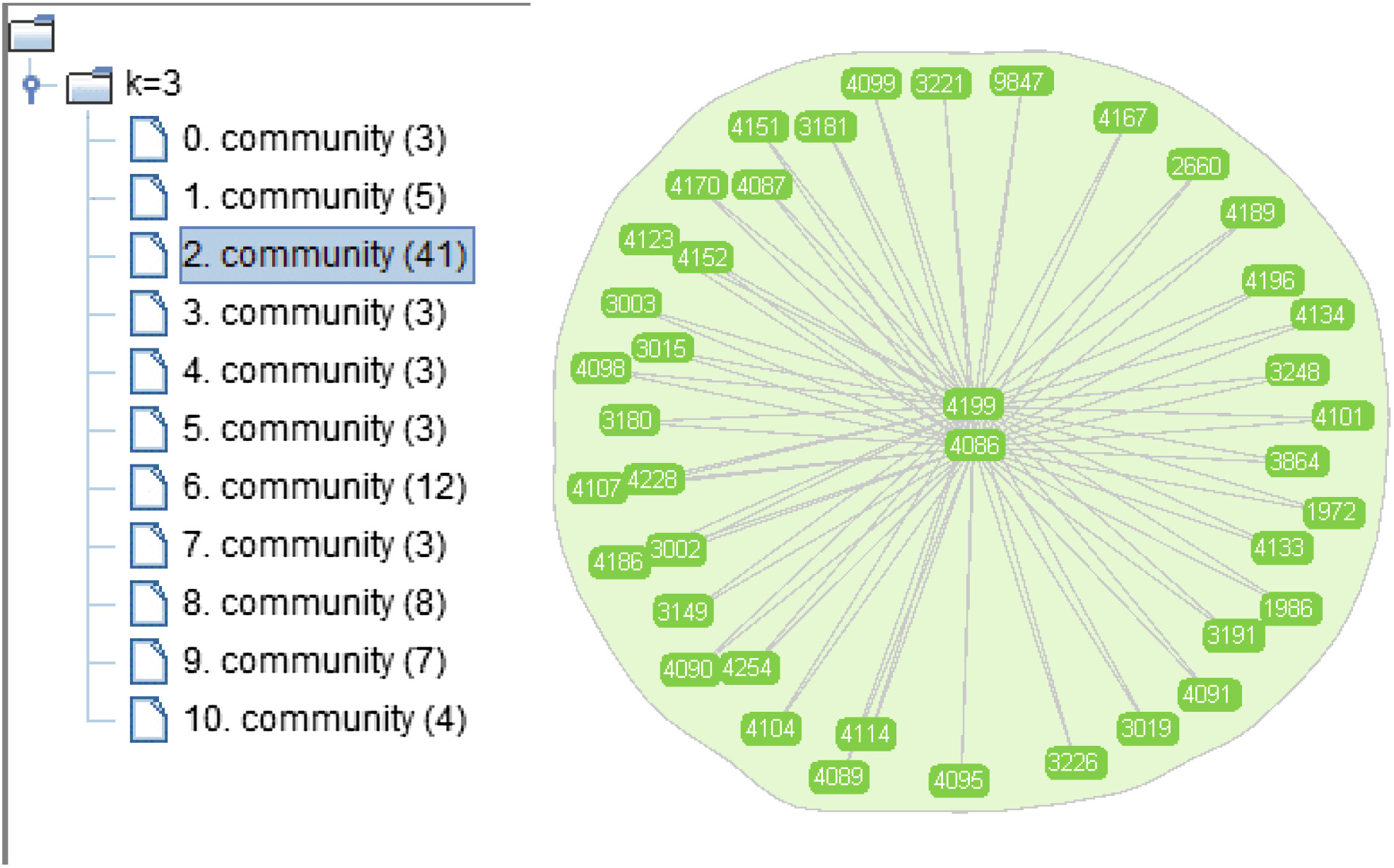
最后,使用CPM算法仔细查看社区检测结果。我们更关注CPM结果中的重叠节点,因为该算法可以将一个节点划分到多个社区中。令我们惊讶的是,所有11个社区都有一个共同的节点,即编号为9847的节点。图5是部分示意图。
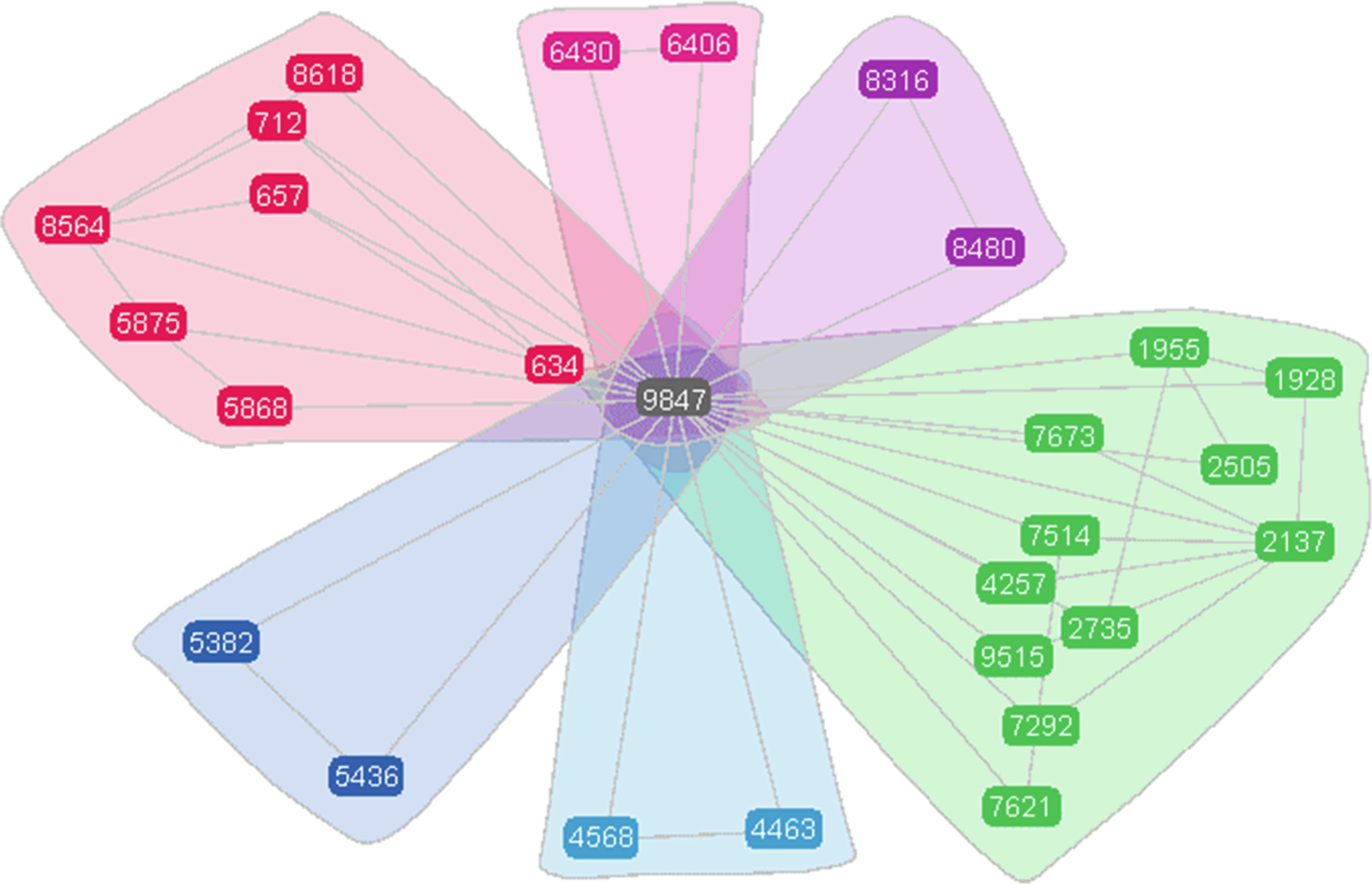
类似地,我们浏览了该账号的主页,发现它属于“灰色账号”。对于这类特殊的节点,我们将参与任务的所有账号分为两类:一类称为“黑色账号”,指那些被检测到始终参与推广任务的专业网络水军成员;另一类称为“灰色账号”,这些账号在正常情况下发布自然内容,偶尔承接任务。本文提到的节点就是一个典型的“灰色账号”,他平时发布有关国学欣赏的内容,有时也作为发帖人执行一些推广任务。为了证明“灰色账号”并非个例,我们在原始数据中尝试寻找更多类似的账号,并成功找到。
需要注意的是,这是一个特殊的群体,其中的节点拥有大量粉丝,并在网络中具有较高的影响力。这意味着,一旦这些“灰色账号”为了经济利益进行转发或发布帖子,就更有可能影响其粉丝并进一步传播谣言。综上所述,这些不起眼的兼职网络水军账号比全职的具有更大的影响力和更强的传播力。更令人担忧的是,由于其行为的模糊性,这些账号更难以被识别和监管。
5 结论
随着Web 2.0时代的到来,网络舆论在引导社会讨论方面发挥着特殊作用。因此,对IWA社交网络结构及其传播路径进行充分分析具有重要意义。本文提出了一种IWA社交网络的概念,这是一种非自然的社交网络,并主要分析了该网络的结构特征。随后,我们展示了一些有意义的现象,并尝试从人类思维角度对其进行解释。最后,我们将其总结如下:
- IWA社交网络是一个稀疏网络,只有少数水军形成了社交圈。
- FN算法和CPM算法均有助于发现水军比例较高的社区,且这些社区的内容具有惊人的相似性。
- “灰色账号”在正常情况下发布普通内容,但会偶尔接取任务,这类账号被发现是一个特殊群体,相较于其他水军具有更大的影响力和传播能力。
本次实验表明,网络水军的网络值得深入分析,经过一系列分析后可以挖掘出一些有意义的现象。接下来,我们计划研究这些账号(尤其是“灰色账号”)的影响以及传播预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









