



智能家居个人助手的隐私规范
摘要
智能家居个人助手(SPA)拥有一个复杂的生态系统,使其能够仅通过语音命令就代表用户执行各种任务。SPA的功能持续扩展,在亚马逊Alexa平台上已有超过十万种第三方技能,涵盖多个类别,从家庭内部的任务(例如管理智能设备)到家庭范围之外的任务(例如在线购物、预订出行)。在SPA生态系统中,信息在多个实体之间流动,包括SPA服务提供商、第三方技能提供商、智能设备提供商、其他用户以及外部方。
以往的研究尚未探讨SPA生态系统中的隐私规范,即这些信息流的可接受性。本文基于情境完整性理论,通过一项包含1738名参与者的大型研究,探讨了语音助手应用中的隐私规范。我们还研究了情境完整性参数和个人因素对隐私规范的影响。此外,我们识别了所研究的隐私规范在情境完整性参数方面的相似性,以提炼出更具普遍性的隐私规范,这可能有助于为SPA建立合适的隐私默认设置。最后,我们根据所研究的隐私规范,为SPA服务提供商和第三方技能提供商提供了建议。
CCS概念
- 安全和隐私 → 隐私保护; 安全与隐私中的可用性;
- 以人为中心的计算 → 人机交互中的实证研究。
关键词
智能家居个人助手,人工智能助手,语音助手,隐私,规范,情境完整性,亚马逊Alexa,谷歌助手
1 引言
智能家居个人助手(SPA)可以代表其用户执行许多任务,包括购买商品和食品、管理待办事项列表、回答知识性问题、播放音乐、规划假期、控制其他智能家居设备、发送消息、拨打电话以及更多 [8, 25, 62]。SPA 正变得越来越普及,在 2019[65], 售出了 1.47 亿台设备,其中 26.2% 为亚马逊Echo/Alexa 设备,20% 为谷歌Home/Assistant 设备,这两者在市场上占据着远超其他产品的主导地位。尽管如此,研究表明 SPA 存在隐私风险,已有系统性研究探讨了 SPA 特定部分的隐私风险,例如因已证实的误激活而加剧的“持续监听”风险,以及在整个复杂的 SPA 生态系统中的风险 [20, 25, 37, 63]。先前的研究表明,尽管一些用户对 SPA 及其生态系统的心智模型不完整,但他们仍存在隐私担忧,并在缺乏更好方式来管理 SPA 隐私的情况下采用应对策略 [1, 36, 41, 45, 67]。
最近,先前的研究主要从智能音箱的角度出发,致力于解决或缓解语音助手应用的隐私问题。例如,提出了利用视线[49, 51]和音量[51]来检测智能音箱是否正被对话,从而判断其是否应进入监听模式。其他更为激进的方法包括使用可穿戴设备[17], 干扰音频信号,使用户能够控制智能音箱何时接收可用音频,或通过使用过滤器[16]阻止敏感对话的接收。
尽管这些研究为控制到达智能音箱的数据量水平奠定了基础,但它们通常只关注SPA生态系统的很小一部分。语音助手应用远不止是智能音箱:其架构复杂,涉及多个不同的利益相关方[20, 25, 62]。这一复杂架构包含智能音箱部分(例如亚马逊Echo),但它连接到基于云的语音助手(例如亚马逊Alexa),语音和意图识别在云端进行。在这里,系统决定如何最佳执行用户的语音指令。事实上,智能音箱本身能力有限,仅能识别唤醒词[74], ;一旦识别成功,它便充当转发器,将所有录制的数据发送至云端进行分析。
一旦基于云的SPA后端识别出用户命令背后的意图,就会将该命令与能够更好满足需求的技能进行匹配[39] ,然后将命令转发给相应的技能。SPA技能在谷歌助手中称为操作,在亚马逊Alexa中称为技能,这些技能可由第三方开发并托管在互联网的任何位置。亚马逊Alexa中的第三方技能数量已经超过了100,000[71]。这意味着在复杂的SPA生态系统中存在大量的信息流,该生态系统涉及多个参与方:SPA服务提供商(例如亚马逊/谷歌)、多个第三方技能或操作服务提供者,这些提供者可在用户发出语音命令时被SPA调用(例如通过Spotify 播放音乐、通过优步叫车、通过Myemail读取电子邮件等)。
尽管近期关于语音助手应用(SPAs)的研究开始关注用户在智能音箱之外的隐私感知和心智模型,但此前尚无研究真正考察信息流在整个SPA生态系统中的可接受性,该生态系统包括用户、SPA服务提供商、第三方技能提供者以及其他第三方。另一类研究探讨了智能家居中的隐私规范,但未考虑上述 SPA特有的复杂生态系统(例如,未涉及SPA典型的第三方技能)。我们的工作是首次对整个SPA生态系统的隐私规范进行挖掘与研究。这一点至关重要,因为挖掘和研究SPA生态系统的隐私规范有助于:i) 帮助SPA服务提供商和监管机构识别和理解使用模式,明确隐私侵犯可能发生的时间和场景;ii) 检查现有的SPA隐私控制机制是否与隐私规范有效契合;iii) 使 SPA及技能的提供者和设计者能够基于用户在隐私方面的期望和需求进行开发;iv) 根据隐私规范为SPA的隐私控制设定合适的默认值。
我们特别研究以下研究问题: 研究问题1 应当由哪些隐私规范来管理SPA生态系统中的信息流?研究问题2 哪些情境和个人因素对这些隐私规范影响最大?研究问题3 在SPA生态系统中,最具普遍性和代表性的隐私规范子集是什么?
为了回答这些问题,我们开展了一项大规模实证研究,共有1738名参与者。本研究以情境完整性(CI)理论为基础,该理论为研究隐私规范和期望提供了成熟的研究框架,用于揭示 SPA生态系统中的隐私规范。我们还使用了数据挖掘技术(关联规则挖掘)来提取具有高度代表性的通用隐私规范。我们的主要贡献如下:
- 我们基于CI,结合影响可接受性的不同参数(包括发送者、主体、接收者、数据类型和传输原则),推导出 SPA生态系统中数据流的隐私规范。在接收者方面,我们考虑了整个SPA生态系统、其他用户、SPA服务提供商、第三方技能提供者以及外部方。•我们研究了CI参数和个人因素对隐私规范的影响。我们表明隐私规范主要受CI参数影响,只有少数个人因素起到(较不重要)的作用。•我们基于CI参数和数据流可接受性,识别所提取的隐私规范之间的相似性,以提炼出更通用的隐私规范。重要的是,这些更通用的隐私规范有助于为单页应用建立隐私默认设置。我们根据所研究的隐私规范,为单页应用和第三方技能提供 商提供建议。
2 背景与相关工作
本节介绍了语音助手应用的隐私问题 . 我们提供了情境完整性理论所需的背景知识,以及如何利用该理论来提取隐私规范。随后,我们讨论了关于智能家居隐私的相关研究,并更详细地阐述了针对单页应用(SPA)特有的不同特征,以理解、研究和缓解单页应用中隐私问题的相关工作。
2.1 情境完整性与其在引出隐私规范中的应用
情境完整性(CI)理论为研究隐私规范和期望提供了一个成熟 的框架[14, 53, 54]。它将隐私定义为在特定背景下,基于社会和文化规范的信息流的适当性。CI使用五个参数来描述信息流: (1)信息发送者,(2)属性或信息类型,(3)被传输信息的信息主体,(4)信息接收者,以及(5)对信息从发送者向接收者传输所施加的传输原则或条件。
情境完整性一直被视为一种适当的框架,用于引出预期的隐私规范[10, 11, 47, 64]。这通常通过因子情景调查来实现,即在情境完整性中改变各种情境参数,针对情景描述中的信息流(使用这些情境参数描述)询问其可接受性。也就是说,某个特定发送者将特定类型的信息和特定主体的信息,在使用(或不使用)一组传输原则(例如,出于特定目的)的情况下,传输给特定接收者,这种信息传输的可接受性如何。
该方法论已被用于在在线环境[47]中或特定领域(如教育场景中的数据共享[64])内提取预期的隐私规范。如下文将进一步讨论的,该方法论还被应用于表明,有可能为某些智能家居设备[10], 提取有意义的隐私规范,并为特定类型的智能物联网设备(如物联网玩具[11])提取隐私规范。
我们在研究中基于这种知名的基于情景的调查方法,结合情境完整性框架在SPA生态系统中的实例化,来获取整个 SPA生态系统中的隐私规范。此外,我们还增加了一种新颖的方法,用于分析相对于先前使用该情境完整性框架的研究所获取的信息。最后,本文首次提出使用数据挖掘技术(关联规则挖掘)来发现隐私规范之间的相似性,从而能够推导出具有高度代表性的通用隐私规范,这些规范可作为合适的默认值使用。
2.2 隐私在智能家居中
Extensive research has been conducted to d 从人机交互(HCI)的角度来看,先前的研究探讨了用户对智能家居设备的心智模型。例如,[76, 79]通过对智能家居用户进行半结构化访谈,以了解他们的心智模型和隐私担忧。
他们发现,智能家居所有者更重视便利性而非隐私;而 [26, 55]则探究了智能家居的安全认知,即识别影响安全决策的因素,如感知到的能力和信任度,以及用户在购买物联网设备前后所关注的问题。此外,塔巴苏姆等人 [68] 探讨了用户偏好,例如是否允许不住在一起的人访问智能设备,结果显示用户确实希望让不住在一起的人(如家人)出于特定目的访问这些设备。
其他学者研究了支持物联网的智能家居设备的访问控制方法 [21, 35, 46]。例如,何等人[35]探讨了在物联网智能家居中,访问控制策略如何因用户之间的关系和不同设备功能等情境因素而有所不同。科爾納戈等人[21]研究了物联网个性化隐私助手( PPAs),以帮助用户发现并控制附近智能设备的数据收集行为,而曾等人[77]构建了一个原型并评估了访问控制应用的可用性。
马南达尔等人[46]提出了Hϵlion,该系统能够分析用户的日常行为,并协助他们基于这些行为设计策略以保护其智能家居的安全。
在与我们论文最相近的研究中,阿普索普等人[10, 11]应用情境完整性框架来检验物联网设备中信息共享的可接受性,既从广义的智能家居设备中采样示例[10] ,也专门研究了物联网玩具的隐私规范[11]。类似地,巴博萨等人[12]采用一种情境化方法来捕捉智能家居中的隐私偏好,例如考虑不同属性(如信息接收者)和隐私态度,并提出了用于预测用户个性化隐私偏好的机器学习模型。尽管我们采用了类似的基于情境完整性的方法论,并具有一些关键创新点(如前一节(第2.1节)提到的数据挖掘),但我们的重点是提取智能语音助手(SPA)的隐私规范,这是一种具有开放语音通道特性以及特定且复杂生态系统的独特智能家居技术,带来了其特有的隐私挑战 [1, 20, 25, 37, 63]。例如,此前的研究未考虑智能语音助手中不断增长的第三方技能所带来的挑战,该数量在亚马逊Alexa中已超过10万[71], ,并对SPA功能至关重要。然而,这些技能由第三方(而非智能语音助手开发者:亚马逊、谷歌等)开发,因此涉及成千上万个不同实体的信息流变得更为复杂。用户只能通过语音间接与这些技能交互,因为它们运行在第三方服务提供商的服务器上,而非安装在本地智能音箱中,需通过 SPA服务提供商云端进行访问。
2.3 隐私在单页应用S
everal works studied th 用户对单页应用[1, 18, 19, 29, 36, 41, 45, 50, 67]的隐私感知和关注。马尔金等人[45]探讨了用户对其语音录音处理情况的感知,并表明其大多数参与者是不了解语音录音的存储模式和管理选项。赵 [18] 集中研究了使用 SPA 检索健康相关信息的情况,表明用户对此类使用确实存在担忧,而与 SPA 交互的实际模式(语音/文本)并不会影响这些感知。其他研究 [41, 67] 强调了用户尽管存在隐私担忧仍采用 SPA 的原因,并发现消费者会以隐私换取便利和好处。一些研究还显示了用户对 SPA 存在不准确的心智模型,以及他们在考虑 SPA 生态系统 [1, 36] 中不同相关方时所采用的应对策略。例如,他们指出用户可能会避免使用 SPA 的某些功能以保护自己;同时表明大多数用户实际上并不清楚如何保护自己,导致隐私风险管理无效。最后,赵等人 [19] 研究了在 Alexa 上启用隐私设置对信任的影响,发现如果隐私设置的自定义能够同时伴随用户通过助手访问内容(如信息来源)的自定义选项,则信任度会提升。尽管这些研究揭示了用户的感知、担忧、心智模型和应对策略,但尚未系统地探讨信息流可接受性以及应在 SPA 生态系统中规范信息流的隐私规范。
先前的研究也试图解决或缓解单页应用(SPA)中的隐私问题。其中一项研究特别关注提供机制,使用户能够控制智能音箱何时监听自己,因为尽管理论上智能音箱只应对唤醒词做出反应,但误激活现象确实会发生[24]。陈等人[17]开发了一种可穿戴的麦克风干扰装置,能够从各个方向禁用麦克风。冠军等人[16]提出一种中间设备,可智能地过滤敏感对话,防止其被智能音箱记录。其他研究提出了让智能音箱检测是否正在对其说话的方法[49, 51],为此他们使用了视线[49, 51]和/或音量[51]来判断用户是否在面向智能音箱说话。然而如上所述,这些研究通常集中在SPA生态系统中的智能音箱部分,而未考虑智能音箱一旦录下用户所说内容后可能引发的进一步信息流。
已有研究提出过替代性的SPA架构(例如Snips[22]),使所有计算都在本地离线进行,但这需要在部署前预先定义所有功能,这对于主流的单页应用而言并不现实。
3 方法论
我们进行了一项基于情境完整性的在线调查[70] ,以了解用户在SPA生态系统中关于信息流的使用安全与隐私偏好。该研究已通过我们的机构审查委员会(IRB)审核和批准。所有参与者均通过Prolifc [2]招募并获得报酬,具体细节如下。
3.1 单页应用生态系统中的情境完整性
Contextual integrity considers five main parameters:sender 例如,接收者、信息类型(主题、属性)、信息主体以及传输原则。先前研究(见第2.3节)已探讨了用户如何更好地控制SPA何时处于监听状态,但尚未涉及SPA在接收到数据后如何处理这些数据。这一点至关重要,因为SPA生态系统复杂,且SPA所提供的功能涉及多个服务提供商和实体。如果数据保留在智能音箱内部并在此处进行处理,则不会出现问题。
然而,问题在于数据流经复杂的SPA生态系统。因此,我们的关注重点是源自SPA的信息流。我们将SPA视为发送者,因为它会在唤醒词[24]触发后或任何误激活[24], 发生后自动收集用户所说的一切内容,并将其发送至SPA生态系统的其他部分,例如发送给SPA服务提供商以进行语音/意图识别。因此,我们将信息的主体视为与SPA对话的用户1。这意味着,在本研究中,为了在SPA生态系统中提取隐私规范,我们主要改变三个情境完整性参数:接收者、数据属性和传输原则,具体如下所述。
表1总结了所有情境完整性参数在SPA生态系统案例中的具体化。
数据属性(信息类型)
我们旨在尽可能覆盖SPA生态系统中的信息流类型,考虑了亚马逊和谷歌分别为Alexa和谷歌助手提供的技能[5]与操作[31]类别、涉及SPA生态系统不同元素的各类最终用途(例如,查询、服务、智能设备、购物) [1], ,以及相关数据的敏感性。我们从11个技能/操作类别中选取了15个数据属性,涵盖生态系统的不同方面,并以作者的初步判断为指导,以最大化所选数据属性在敏感性水平上的多样性。随后,我们对来自不同背景的23名参与者进行了预调查,采用便利样本方式,请他们对所选数据属性的敏感性进行评分(使用五点李克特量表,1表示最不敏感,5表示高度敏感)。
需要注意的是,我们并未直接使用预调查所得的敏感性评分结果;这些值仅用于进一步确保所选数据属性的敏感性范围超出作者自身的判断。表2总结了各类别、数据类型、收集的具体数据,以及短问卷调查中敏感性评分的均值和标准差。最后需说明的是,在力求覆盖不同类型的数据、使用场景和敏感性的同时,所有类别均包含大量技能。例如,撰写本文时,商业与金融类别在亚马逊Alexa平台上就包含了数千项技能。
接收者
我们考虑了SPA生态系统[20, 25, 36], 中信息的不同接收者,包括用户和非用户:SPA服务提供商、技能提供者以及外部实体。关于用户,我们考虑了用户本身,以及其他可能从 SPA获取信息的主体(例如,通过向其询问)。在此,我们涵盖了不同类型的关联关系,其中一些关系更倾向于与信息主体同住(如伴侣、儿童、同住者),或仅为拜访(如邻居、亲密朋友),但也包括那些与信息主体是否同住并不明确的关系。这是因为已有研究表明,即使对于某些不一定与信息主体共同居住的关系(如兄弟姐妹、父母、家政人员等),也可能存在主体可能愿意为特定目的 [68] 共享对智能设备的访问权限。
关于non-user接收者,我们考虑了SPA服务提供商(例如亚马逊、谷歌等),他们提供基于云的SPA后端;技能提供者,他们为SPA提供额外功能,其中一些可在表2的“类别”栏中看到(例如听音乐、购物、管理其他智能设备等);以及外部实体,他们可能会被授予访问SPA生态系统的权限,例如广告机构 [28] 和执法机构 [72]。
传输原则
在情境完整性中,传输原则制约着信息从一方到另一方的流动 [14, 54]。我们考虑的第一个条件是数据共享后将被使用的 目的 ,该条件可适用于 用户接收者 和 非用户接收者 。此外,我们还考虑了与信息处理和存储相关的条件,这些条件更多地与 非用户接收者 (例如 SPA服务提供商 )相关,因为他们通常具备数据处理能力。具体而言,我们考虑了六个与 告知 和 保密性 [14, 54], 、 匿名性 和 保留期限 [10, 11], 、以及 查阅 和 删除 [66]相关的条件:1)是否已 通知 您;2)数据是否为 匿名 ;3)数据是否被保持 保密 ,即不与他人共享;4)数据是否仅在实现目的所必需的时间内被存储;5)您是否可以 查看或删除数据 。
3.2 调查工具
The study工具是一份分为三个部分的问卷。问卷的第一部分介绍了研究内容,请求参与者的同意,并收集参与者关于语音助手应用(SPAs)的信息。问卷的第二部分包含代表SPA生态系统中信息流的情景,并询问了这些情景的可接受性(详见下文)。第三部分重点关注参与者的隐私和安全态度,通过10项的 IUIPC量表[44]来测量,该量表涵盖三个维度:收集、意识和控制。为了测量安全态度,使用了SA‐6,这是一个由六个项目组成的量表[27] ,用于评估用户自我报告的安全态度。
3.2.1 情景
基于情境完整性理论的基于情景描述的调查 [10, 11, 47, 64]已被证明是引出其他领域隐私规范的有效方法,如第2.1节所述。采用类似的方法,我们创建了以情景描述形式呈现的情景,探讨了第3.1节中介绍的SPA生态系统中数据属性、接收者和传输原则的所有组合。这共产生了120种不同的情景。
具体而言,针对15种不同的数据类型中的每一种,我们创建了八个情景。每个数据类型的八个情景包括两个涉及用户接收者的情景(一个有目的,一个无目的(关于数据的条件仅涉及数据处理者));以及六个涉及非用户接收者(数据处理者)的情景。这六个涉及非用户接收者的情景包括五个具有目的且针对不同接收者设定不同条件的情景:SPA服务提供商、相关技能、不相关技能、广告和执法;以及一个涵盖所有非用户接收者但无任何传输原则(无目的/条件)的情景。需要注意的是,相关技能与不相关技能的区别在于,相关技能属于所指定的15种数据类型类别中的技能,而不相关技能则是指与访问此类数据无关的技能类型。这一点对于研究可接受性是否也取决于该因素至关重要。
表 1:情境完整性框架在单页应用生态系统中的实例化。
| CI参数 | 值 | #描述 |
|---|---|---|
| 发送者 | SPA | 正在使用的 SPA ,例如亚马逊 Echo/Alexa 、谷歌 Home/Assistant。 |
| 主体 | SPA用户 | 正在与 SPA对话的用户 。 |
| 属性 | 表2中的15个属性 | 表示在单页应用生态系统中流动的各种信息类型。 |
| 接收者 |
用户
SPA服务提供商 ‐ 技能提供者 ‐ 外部方 | 伴侣, 儿童, 同住者, 邻居, 房屋管理员, 访客, 等。. 提供单页应用服务的公司,例如:亚马逊,谷歌,等等。. 第三方技能的提供者。技能类别请参见表 2 。 广告机构,执法机构。 |
| 传输原则 | 否目的,否条件 目的,无条件 目的,条件 | 目的:收集数据的目的已说明。 条件: 1) 如果您被通知; 2) 如果数据是匿名的; 3) 如果该数据是保密的,不与他人共享; 4) 如果数据被存储为 long as必要 for该目的; 5) 如果您可以查阅或删除该数据。 |
表 2:数据属性的敏感性
| 技能类别 | 数据类型 | 数据收集情况 | 均值 标准差 敏感性 |
|---|---|---|---|
| 智能家居 | 智能门锁 | 智能温控器 og 2.8 | 监控 4.4 |
| 门锁状态 4.0 1.2 | 历史 l 1.1 | ||
| 智能摄像头 | 家庭su 1.0 | ||
| 商业&金融 | 银行 | 银行账户详情 3.8 1.2 | |
| 社交&通信 | 电子邮件 | 电子邮件内容 4.0 1.0 | |
| 呼叫助手 | 联系人 3.5 1.0 | ||
| 视频通话 | 视频通话数据 3.7 1.0 | ||
| 健康&健身 | 医疗保健 | 诊断结果 4.1 1.0 | |
| 睡眠辅助 | 睡眠小时 2.6 1.0 | ||
| 音乐&音频 | 播放列表 | 最近播放的音乐 2.3 1.3 | |
| 购物 | 在线购物 | 购物历史 2.8 1.2 | |
| 效率 | 待办事项列表 | 提醒 3.0 1.4 | |
| 天气 | 天气预报 | 天气更新 1.8 1.1 | |
| 旅行&交通 | 乘车服务例如优步 | 用户位置 3.0 1.0 | |
| 非技能单页应用数据 | 语音录音 | 命令历史记录 3.7 1.5 |
技能类型,正如先前研究指出的那样,功能可能是考虑单页应用隐私时的一个重要因素 [41, 67]。最后,我们使用五点李克特量表(1 到 5 分别表示完全不可接受和完全可接受)来测量每个情景的可接受性。为了获得更好的反馈并减少完成时间,我们将五点李克特量表按从负面到正面的顺序呈现 [32, 43, 61]。
所有使用的120个场景的完整细节见补充材料。为说明目的,我们展示了其中两个情景所使用的措辞。
首先,我们展示一个包含用户接收者和目的的示例情景:
“假设您通过语音助手 (例如亚马逊 Echo/Alexa,谷歌 Home/Assistant)播放音乐 。以下接收者为了播放您喜欢的音乐这一目的,使用您常播放的音乐,对您而言可接受程度如何:
• ]
• [ 5 您的伴侣-point likert…
• 一般访客 [5-point likert]”
其次,我们展示一个包含非用户接收者(相关技能)、使用目的以及不同条件作为传输原则的示例情景:
假设通过语音助手(例如亚马逊Echo/Alexa、谷歌 Home/Assistant)订购优步等乘车服务,您认为可接受的程度如何
为了使用此功能,您的家庭住址等数据将在以下条件下与 旅行与交通类别中的技能或操作的服务提供商(例如优步技能) 共享,以便他们知道派司机到何处接您:
• ]
•
[5 否条件-point likert如果您被通知 [5 ]
•
-point likert....
• 如果您可以查阅或删除这些数据[5-point likert]”
3.3 流程
我们的调查在Qualtrics2上创建和托管,并通过Prolifc3招募参与者。我们进行了两次预研究以完善调查工具。共有二十(20)名参与者完成了第一次预研究。我们利用此次预研究探讨情景的表述方式以及布局对参与者而言是否清晰合理。根据反馈,我们重新表述了部分情景,增加了“否”条件,并通过明确技能类别来修改技能情景。第二次预测试侧重于表述方式的优化
2 www. qualtrics.com 3 www. prolifc.co
表 3:调查的参与者人口统计信息。
| SPA | SPA | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |......
| 用户 | 非用户 | 性别 | Male | 474 | 416 |
| — | — | — | — | — | — |
| | | 女性 | 397 | 438 | |
| | | 不愿透露 | 8 | 5 | |
| Age | 18 – 24岁 | 340 | 339 | | |
| | 25 – 34岁 | 294 | 280 | | |
| | 35 – 44 | 134 | 93 | | |
| | 45 – 54 | 66 | 60 | | |
| | 55 – 64 | 37 | 60 | | |
| | 65+ | 8 | 27 | | |
| 教育 | PhD | 25 | 24 | | |
| | 硕士学位 | 163 | 173 | | |
| | 本科 | 315 | 250 | | |
| | 大学/A‐levels | 315 | 339 | | |
| | 中等教育 | 49 | 54 | | |
| | 无正规教育 | 5 | 8 | | |
| | 不愿透露 | 7 | 11 | | |
| 就业 | 全职 | 428 | 274 | | |
| | 兼职 | 153 | 165 | | |
| | 失业 | 140 | 200 | | |
| | 其他 | 74 | 127 | | |
| | 退休/家庭主妇 | 72 | 78 | | |
| | 不愿透露 | 12 | 15 | | |
| 学生 | Yes | 333 | 348 | | |
| | No | 541 | 511 | | |
| | 不愿透露 | 5 | - | | |
| 技术使用 | 完全不 | 166 | 254 | | |
| | 每天 | 533 | 421 | | |
| | 每周 | 180 | 184 | | |
| 单页应用品牌 | 亚马逊Echo/Alexa | 465 | | | |
| | 亚马逊Echo/Alexa +其他 | 132 | | | |
| | 谷歌Home | 261 | | | |
| | 谷歌Home +其他 | 11 | | | |
| | 微软Invoke/Cortana | 5 | | | |
| | 苹果HomePod/Siri | 3 | | | |
| | 其他 | 2 | | | |
| 总计 | 879 | 859 | | | |
再次呈现情景、所需时间以及参与者应回答的情景数量。第二次预测试调查共有50人参与。因此,我们减少了每位参与者需要回答的情景数量,并加入了“技能/操作”这一表述,以替代仅使用“技能”,帮助使用谷歌设备的参与者更好地理解情景。两次预测试收集的所有数据仅用于改进调查,未包含在最终分析中。
我们的研究最终版本发放给了超过2,017名Prolifc工作人员。每位参与者回答了24个情景问题,这些情景的选取方式如下:每位参与者被随机分配到六个数据属性,每个属性对应四个随机情景。我们通过在Prolifc平台进行预筛选,控制单页应用(SPA)用户与非用户的数量,以使样本中SPA用户和非用户的数量大致相当。我们研究SPA用户与非用户,旨在观察他们在隐私规范上的差异,以了解SPA用户的隐私规范是否也能对非用户有所帮助,因为部分非用户可能由于隐私顾虑而避免使用SPA [41]。此外,我们排除了所有参加过两次预测试研究的参与者,以防止偏差。参与者获得了2.00美元的报酬,调查平均耗时14分钟完成。并非所有参与者都回答了全部问题;参与者被随机分配到6种数据类型中的4个情景,以平衡样本量。最后,每个情景的选项列表(例如用户接收者的显示顺序)也进行了随机化处理。
3.3.1 数据质量
为了最大程度提高数据质量,我们采用了三种方法:注意力检查、随机化以及工人的先前绩效(完成任务和批准率)[34, 38, 48, 57, 60]。在研究开始时,我们告知参与者应尽最大努力回答调查问题,然后在每位参与者需要回答的24个情景中设置了两个注意力检查问题(每八个情景后各一个)。如上所述,我们还对问题进行了随机化处理,以确保每位参与者随机回答调查,且每个情景获得相同数量的参与者。除了随机化问题外,我们还对向参与者呈现情景和选项的方式进行了随机化,以防止顺序效应。此外,在招募参与者时,我们选择那些至少有50次提交记录且批准率达到95%或以上的参与者,正如以往文献所建议的那样[60]。
3.3.2 参与者
总计有2,017名参与者完成了我们的研究,其中 268人未通过一个或两个注意力检查问题。我们无法从Prolifc 获取12名参与者的人口统计信息。所有这些参与者以及未通过一个或两个注意力检查问题的参与者均被排除在分析之外。最终,我们分析了1,738份回复,其中包括879名单页应用用户和 859名非单页应用用户。表3总结了用于分析的参与者的人口统计信息和技术背景。每个情景的回复数量最少为378,最多为 559,每个场景平均411次回复。由于120个情景中的每一个情景都针对某一情境完整性参数的不同值具有可接受性(例如,对于每个具有数据类型和有目的/无目的的用户接收者情景,参与者报告了十种不同关系的可接受性),因此具有完整情境完整性参数说明的实例总数为292,478。
4 结果
4.1 隐私规范概述的隐私规范
我们首先通过报告用户对不同情景的可接受性,概述所提取的隐私规范(研究问题1)。为此,我们使用了基于所调整的情境完整性参数的可接受性热图,这是一种根据情境完整性参数可视化信息流可接受性的方式,此前在其他应用中提取隐私规范时也采用此方法进行可视化 [10, 11]。
在图1中,我们展示了所有数据类型、用户接收者以及说明/未说明目的的传输原则的平均可接受性评分。关于数据属性,我们观察到实际的数据类型似乎起到了一定作用,某些数据属性(如银行、电子邮件)从先验角度看可能非常敏感,导致涉及这些数据属性的大多数情景下的可接受性都非常低(即无论接收者是谁,以及是否说明了目的)。然而,并非在所有情况下,可接受性都仅依赖于数据类型。例如,对于门锁和智能摄像头这类也可能被视为较为敏感的数据类型(在我们最初的预调查研究中也被评为如此——见表2),其可接受性明显取决于接收者的类型;当接收者为伴侣或父母时,其可接受性远高于接收者为邻居或一般访客的情况。此外,关于传输原则也可观察到一些总体趋势,即在说明与接收者共享某种数据类型的目的时,可接受性有所提高。
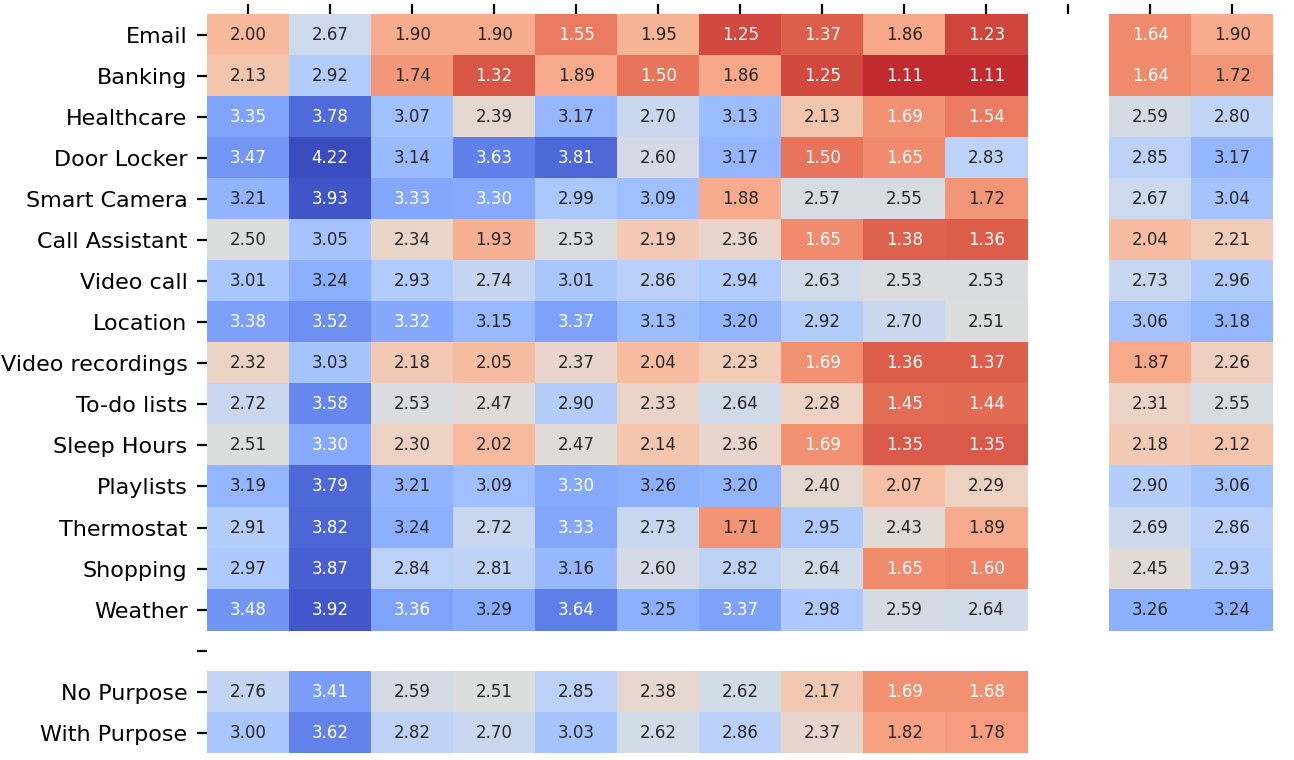
关于非用户接收者的情景,其均值可接受性如图2所示,天气的可接受性得分最高,而银行的得分最低,这与用户接收者的情况相似(如前一段所述)。在接收者方面,广告机构的可接受性最低。得分,尤其是当未声明条件时。在未提及条件的数据类型和传输原则方面也普遍存在这种情况;可接受性得分最低。向相关技能提供者的信息流在所有接收者中具有最高的可接受性得分,高于SPA

服务提供者,尤其是当目的已声明,且传输原则为“您可以查看或删除数据”时。然而,作为接收者,智能个人助理服务提供者与执法机构之间的差异较小。
4.2 回归分析
尽管上一节中的可接受性数据有助于从宏观角度了解各情景下的平均可接受性,我们还希望进一步理解不同情境完整性参数以及参与者个人特征对信息流可接受性的影响(研究问题2)。为此,我们进行了回归分析。具体而言,我们并不只是关注可接受性的程度,而是更感兴趣于理解实际的实践意义,即根据所涉及的因素判断某一信息流是否会被视为隐私侵犯或是否可接受。因此,我们将情景的可接受性进行二值化处理,区分为不可接受和可接受两类,并剔除了中性情况。随后,我们采用了向前逐步法进行模型选择[40], ,逐步将变量加入模型直至不再有改进为止,开展了Binary Logistic Regression。除了情境完整性参数外,模型中还纳入了关于人口统计、SPA 使用、隐私担忧和安全态度的问题,以便观察个人因素是否也在信息流可接受性中发挥作用。我们基于接收者类型建立了两个模型:一类是接收者为其他用户(如伴侣、邻居等),另一类是接收者为非用户(如智能个人助理服务提供者、技能提供者等)。
4.2.1 用户接收者模型
涉及用户接收者的场景的回归模型结果汇总于表4和表5中。关于模型的质量,我们可以从表5中看到,该模型正确分类了72.9%的案例(各类别之间几乎平均分配),相较于空模型(没有任何解释变量)有显著提升,这一点通过模型系数的综合检验结果高度显著得以证实( χ2= 25762.992,p = 0.000)。尽管该模型的目的并非用于预测,而是测量每个变量的影响,我们仍检查了潜在的过拟合问题。首先,我们的每变量事件数远超过以往文献建议的避免过拟合所需的最低标准十例[59] 。其次,我们还进行了随机 70/30划分以构建模型并进行预测,获得了相似的72%准确率。
关于每个变量的影响,我们可以在表5中看到模型在每一步纳入变量的顺序,其中学生身份和IUIPC_意识未被显示,因为模型在第12步之后拒绝了它们,认为它们不再带来任何改进。根据χ 2改进程度的量化结果,可以看出接收者是最具影响力的变量,其次是数据属性。接下来,提供相似改进的是两个个人变量(年龄和IUIPC_收集)以及传输原则(在此情况下,是否给出了目的)。其余变量虽然仍有一定改进作用,但贡献不如前述变量显著。因此,我们可以得出结论:情境变量起到了最重要的作用。也就是说,特定的上下文最有可能决定数据流被视为可接受还是不可接受。在两个起到更重要作用的个人变量中,我们发现 IUIPC的收集维度远比控制和意识重要(后者甚至未被纳入模型),这是合理的,因为我们关注的是明确的数据流,即谁将能够collect数据,以及这种行为的可接受性。
关于变量值所产生的影响,表4展示了所有变量(包括分类变量的类别)的β系数值及其显著性水平。注意:变量内各类别的系数解释及其显著性需相对于参考类别进行(参考类别列于表4的图注中)。例如,我们可以看到所有数据类型的系数均显著且为负值,这意味着与参考类别(在本例中为天气)相比,任何其他属性更常导致不可接受性。这是合理的,因为在我们为选择属性而进行的预调查中(见第2.1节),天气被报告为最不敏感的。此外,还可以看出,银行等数据类型的 (负)系数比播放列表等其他类型更大,这意味着包含银行数据的情景相较于包含天气数据的情景,比包含播放列表数据的情景更不可接受。
关于接收者,系数均为正值,例如相对于参考类别(一般访客)显示出更高的可接受性。但请注意,邻居与一般访客之间并无显著差异。总体趋势表明,关系类型越亲密,相对于参考类别,该接收者的可接受性越高。
最后,如前所述,非情境性个人变量的作用远小于情境变量。然而,隐私担忧(包括IUIPC的收集和控制两个维度)以及年龄也会影响可接受性,隐私担忧程度越高、年龄越大,可接受性越低。尽管其他个人变量具有显著性,但其系数要小得多。
4.2.2 非用户接收者模型
涉及用户接收者的场景的回归模型结果总结于表6和表7中。关于模型的质量,我们可以从表7中看到,该模型正确分类了73.2%的案例,相较于空模型(没有任何解释变量)有显著提升,并通过模型系数的综合检验得到确认,其值为χ2 = 38495.635,p = 0.000,具有高度显著性。与之前的模型一样,我们也进行了随机70/30划分以构建模型并进行预测,获得了相似的73%准确率。
关于各个变量的影响,我们可以在表7中看到模型在每一步纳入变量的顺序。在这种情况下,模型唯一未包含的变量是个人信息隐私关注量表意识。_根据χ 2改进程度的量化结果,可以看出接收者似乎与用户接收者的情况一样,是最具影响力的变量。然而,与用户接收者模型不同的是,接收者之后是传输原则。这可能是因为非用户接收者属于数据处理者,在信息流发生的条件下,相关条件变得更加重要,特别是如第4.1节所示,并通过观察无条件下的传输原则系数所证实的那样。
表4:用户接收者回归模型:参数估计。对于分类变量,参考类别(不在模型中)为数据类型=[天气];接收者=[一般访客];传输原则=[无目的];SPA使用=[是];就业=[无带薪工作];性别=[女性];科技使用=[每天]。
| B | S.E. | W | S. | B 2.214 . | S.E. 040 | W | S. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据类型 | [电子邮件] | [电子邮件] | -2.703 | .049 | 3001.795 | 1 | .000接收者 | [父母] | [父母] | 3003.790 | 1 | .000 | |||
| 数据类型 | [银行] | [银行] | -2.762 | .051 | 2938.022 | 1 | .000 | .000接收者 | [合作伙伴] | [合作伙伴] | 3.250 .042 1.924 . | 041 | 6051.599 | 1 | .000 |
| 数据类型 | [医疗保健] | [医疗保健] | ‐.962 | .042 | 518.533 | 1 | .000 | .000接收者 | [兄弟姐妹] | [兄弟姐妹] | 2252.274 | 1 | .000 | ||
| 数据类型 | [门锁] | [门锁] | ‐.440 | .043 | 106.415 | 1 | .000 | .000接收者 | [同住者] | [同住者] | 1.783 .040 2.330 . | 041 | 1939.825 1 | .000 | |
| 数据类型 | [智能摄像头] | [智能摄像头] | ‐.698 | .043 | 267.300 | 1 | .000 | .000接收者 | [儿童] | [儿童] | 3296.858 | 1 | .000 | ||
| 数据类型 | [通话助手] | [通话助手] | -1.946 | .046 | 1816.590 | 1 | .000 | .000接收者 | [Neighbours] | [Neighbours] | .056 1.541 . | .046 041 | 1.485 | 1 | .223 |
| 数据类型 | [Video Call] | [Video Call] | ‐.813 | .042 | 371.837 | 1 | .000 | .000接收者 | [亲密朋友] | [亲密朋友] | 2.007 . | 040 | 1430.666 | 1 | .000 |
| 数据类型 | [Location] | [Location] | ‐.396 | .043 | 86.744 | 1 | .000 | .000接收者 | [亲密家人] | [亲密家人] | 2465.254 | 1 | .000 | ||
| 数据类型 | [语音录音] | ‐2.086 | ‐2.086 | .046 | 2031.086 | 1 | .000 | .000接收者 | [Housekeeper] | [Housekeeper] | 1.177 . | 041 | 807.676 | 1 | .000 |
| 数据类型 | [待办事项列表] | [待办事项列表] | -1.408 | .041 | 1197.194 | 1 | .000 | 就业 [Full‐time] | ‐.158 | .034 | 21.765 | 1 | .000 | ||
| 数据类型 | [睡眠时间] | [睡眠时间] | -1.923 | .045 | 1815.239 | 1 | .000 | 就业 [Full‐time] | [兼职] | [兼职] | ‐.048 | .036 | 1.814 | 1 | .178 |
| 数据类型 | [播放列表] | [播放列表] | ‐.482 | .043 | 123.009 | 1 | .000 | 就业 [Full‐time] | [不愿透露] | .007 | .007 | .038 | .030 | 1 | .863 |
| 数据类型 | [恒温器] | [恒温器] | ‐.829 | .044 | 363.330 | 1 | .000 | 就业 [Full‐time] | [失业] | [失业] | ‐.024 .035 | .463 | 1 | .496 | |
| 数据类型 | [购物] | [购物] | ‐.963 | .042 | 516.248 | 1 | .000 | 连续的 变量 | IUIPC 收集 ‐.154 | IUIPC 收集 ‐.154 | .008 | 345.026 | 1 | .000 | |
| 转换原则 | [目的] | [目的] | .388 | .016 | 590.950 | 1 | .000 | 连续的 变量 | IUIPC 控制 | IUIPC 控制 | ‐.088 | .010 | 82.983 | 1 | .000 |
| SPA 使用 | [N] | [N] | .204 | .016 | 153.672 | 1 | .000 | 连续的 变量 | SA_6 | SA_6 | .101 ‐.015 .0 | .011 01 | 82.713 | 1 | .000 |
| 性别 | [男性] | [男性] | ‐.163 | .017 | 95.545 | 1 | .000 | 连续的 变量 | A e | A e | 394.845 | 1 | .000 | ||
| 技术 U | [完全不] | [完全不] | .050 | .022 | 5.481 | 1 | .019 | 连续的 变量 | 教育水平 | 教育水平 | ‐.048 | .006 | 56.664 | 1 | .000 |
| 技术 U | .105 | .022 | 22.578 | 1 | .000 | .101 | .095 | 1.123 | 1 | .289 | |||||
| [每周] | |||||||||||||||
| 常数 |
表 5:用户模型:步骤摘要
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 卡方 df 显著性 卡方 df | 卡方 df 显著性 卡方 df | 卡方 df 显著性 卡方 df | 显著性 | 显著性 | 显著性 | 类别百分比 | 变量 |
|---|---|---|---|---|---|---|---|---|
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 269.199 9 .0 | 00 1 | 2269.1 | 99 9 .000 66 | .3% | 类别百分比 | 变量 | |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 61.801 14 .0 | 00 2 | 2231.0 | 00 23 .000 71 | .6% | 输入:接收者 | ||
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 1 .0 | 00 | .000 7 | 2.2% | 输入:数据类型 | |||
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 921.541 | 1 .0 | 00 | 23152.541 24 | .000 7 | 2.3% | 输入:年龄 | |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 642.157 | 1 .0 | 00 243 |
23794.698 25
77.486 | 26 .0 | 00 7 | 2.6% | 输入:IUIPC_收集 |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 582.788 | .000 7 | 2.7% | IN: 传输原则 | ||||
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 140.271 | 1 1 .0 | .000 00 246 | 24517.757 65.851 | 27 28 .0 | 00 72 .00 72 | .8% .9% | IN: SPA使用 |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 148.094 | 输入:教育水平 | ||||||
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 104.442 | 1 .0 1 .0 | 00 247 00 248 | 70.294 37.282 | 29 .0 30 .0 | 00 72 00 72 | .9% .9% | IN: 性别 |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 66.989 | 1 .0 | 00 249 | 10.102 31 .00 | 0 72. | 9% 输入:SA_6 | IN: IUIPC控制 | |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 72.820 | 35 .0 | 00 72 | .9% | ||||
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 79.067 | 4 .0 2 .0 | 00 00 | 24989.169 | 37 .0 | 00 72 | .9% | IN: 就业 |
|
Step 1 12
2 99 3 4 5 6 7 8 9 10 11 12 | 23.417 | 25012.586 | ||||||
| 模型改进正确率 | ||||||||
| IN: 技术使用 |
表6表明,其可接受性远低于参考类别(能够查阅和删除数据)。接下来,数据属性和IUIPC_收集对模型的改进作用与用户接收者模型类似。其余变量也有贡献,但改进程度重要性低得多,某些情况下甚至微不足道(如SPA_使用、性别等)。因此,与用户接收者类似,情境完整性参数和IUIPC起着最关键的作用。此处的主要差异在于,传输原则似乎比实际的数据属性更为突出,而年龄对可接受性的影响则小于对用户接收者的影响。
关于变量中特定类别的影响,表6展示了它们的系数和显著性水平等。与用户接收者模型类似,所有数据类型似乎都比参考类别(天气)的可接受性更低。在接收者方面,智能个人助理服务提供者与参考类别(执法机构)之间没有显著差异,但不相关的技能和广告机构相较于参考类别显得更不可接受。截然不同的是,相关技能明显比参考类别更具可接受性。这进一步支持了在考虑相关技能时所显示的明显更高的平均可接受性。正如我们将在后面讨论的(第5节),这指出了相关技能与不相关的技能之间的一个关键区别,这对智能个人助理服务提供者具有重要意义
技能提供者。关于传输原则,除告知目的但匿名共享数据这一项与参考类别相比无显著差异外,其余各项均比告知目的以及允许查阅并删除所收集的数据(参考类别)更不可接受。最后,与用户接收者模型相同,IUIPC的收集维度在个人变量中表现最为显著。
4.3 通用隐私规范
The 回归 i在 mo 上 models in the prev i 上一节的内容有助于更好地理解情境完整性参数和个人特征在信息流可接受性中的作用。然而,它们的预测能力尚不足以准确判断在实际中是否应允许特定的信息流。因此,我们也非常感兴趣探索是否存在一个更小、更具通用性的隐私规范子集,能够在不同情景下普遍适用(研究问题3)。尼森鲍姆在其情境完整性理论 [53, 54] 中指出,人们可能无法基于隐私担忧或指标来泛化规范,因为隐私观点会因情境而异,并为此提供了实证证据 [47]。然而,这并不排除某些情境可能导致相似的隐私观点。我们的目标正是找出SPA生态系统中哪些情境是相似的(具有某些共同属性)且具有相同的可接受性。为此,我们采用了数据挖掘技术,特别是关联规则挖掘,以提取 SPA生态系统中一组更为抽象和通用的隐私规范。
关联规则挖掘是一种基于规则的方法,用于发现数据集中变量之间的有趣关系[69]。其目的是发现数据集中存在的频繁规则。换句话说,关联规则挖掘用于知识发现,因此它是一种无监督机器学习方法。我们感兴趣的规则类型是:
Co上下文完整性参数 → 可接受/不可接受 ptable
我们使用了著名的 Apriori算法[3]对用户和非用户接收者进行关联规则挖掘 。该算法通常使用两个输入参数来限制其要挖掘的规则 ,将会最小
表6:非用户接收者回归模型。对于分类变量,参考类别(未在表中列出)为数据类型=[天气];接收者=[执法机构];传输原则=[目的、查阅并删除数据];SPA使用=[是];就业=[无带薪工作];学生身份=[是];性别=[女性];技术使用=[每天]。
| B ‐1.040 .0 | S.E 33 | W | S. .000 | 传输 | 传输 | 传输 | B | S.E | W | S. | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据类型 | [电子邮件] | [电子邮件] | 988.614 | 1 |
原则
性别 | [无目的/条件] | ‐1.193 | ‐1.193 | .022 | 2881.772 | 1 | .000 | |||
| 数据类型 | [银行] | [银行] | ‐1.392 .034 | 1681.685 | 1 | .000 |
原则
性别 | [目的,无条件] | [目的,无条件] | -2.337 | .028 | 7201.837 | 1 | .000 | |
| 数据类型 | [医疗保健] | [医疗保健] | ‐.689 | .033 | 447.000 | 1 | .000 |
原则
性别 | [目的,已通知] | [目的,已通知] | ‐.232 | .021 | 123.821 | 1 | .000 |
| 数据类型 | [门锁] | [门锁] | ‐.956 | .033 | 844.029 | 1 | .000 |
原则
性别 | [目的,匿名] | [目的,匿名] | ‐.044 | .021 | 4.383 | 1 | .036 |
| 数据类型 | [Camera] | [Camera] | ‐.666 | .033 | 412.822 | 1 | .000 |
原则
性别 | [目的,机密] | [目的,机密] | ‐.153 | .021 | 54.894 | 1 | .000 |
| 数据类型 | [通话助手] | [通话助手] | ‐1.264 .034 ‐1.393 .0 | 34 | 1421.084 | 1 | .000 .000 |
原则
性别 | [目的,已存储] | [目的,已存储] | ‐.544 | .021 | 664.274 | 1 | .000 |
| 数据类型 | [视频通话] | [视频通话] | 1685.514 | 1 | .000 | 学生 | [男性] | [男性] | .113 | .012 | 81.776 | 1 | .000 | ||
| 数据类型 | [位置] | [位置] | ‐.798 | .033 | 580.696 | 1 | .000 | 技术 | [No] | [No] | .058 | .015 | 14.269 | 1 | .000 |
| 数据类型 | [语音录音] | [语音录音] | ‐1.058 .033 | 1015.699 | 1 | U 就业 | [完全不] | [完全不] | ‐.062 | .016 | 14.641 | 1 | .000 | ||
| 数据类型 | [待办事项列表] | [待办事项列表] | ‐.806 | .030 | 735.882 | 1 | .000 .000 | U 就业 | [每周] | [每周] | .026 | .017 | 2.445 | 1 | .118 |
| 数据类型 | [睡眠时间] | [睡眠时间] | ‐.819 | .033 | 620.210 | 1 | 连续的 | [全职] | [全职] | ‐.136 | .025 .026 . | 28.834 695 | 1 | .000 | |
| 数据类型 | [播放列表] | [播放列表] | ‐.326 | .032 | 100.432 | 1 | .000 | 连续的 | [兼职] | [兼职] | ‐.022 | 1 | .405 | ||
| 数据类型 | [恒温器] | [恒温器] | ‐.683 | .033 | 432.743 | 1 | .000 | 连续的 | [宁愿不说] | [宁愿不说] | ‐.065 | .028 | 5.356 | 1 | .021 |
| 数据类型 | [购物] | [购物] | ‐.732 | .033 .017 . | 501.188 044 | 1 | .000 .835 | 连续的 | [失业] | [失业] | .033 | .026 | 1.626 | 1 | .202 |
| 接收者 | [助理提供者] | [助理提供者] | .004 | 1 | 变量 | IUIPC 收集 | IUIPC 收集 | ‐.286 | .006 | 2088.526 | 1 | .000 | |||
| 接收者 | [相关技能] | [相关技能] | .304 ‐1.308 . | .017 019 | 302.671 | 1 | .000 | 变量 | IUIPC 控制 | IUIPC 控制 | ‐.067 | .007 | 86.212 | 1 | .000 |
| 接收者 | [不相关技能] | [不相关技能] | 4700.128 | 1 | .000 | 变量 | SA_6 | SA_6 | .172 | .008 | 432.944 | 1 | .000 | ||
| 接收者 | [广告机构] | ‐1.765 .020 | ‐1.765 .020 | 7546.064 | 1 | .000 | 变量 | A e | A e | ‐.008 | .001 | 161.405 | 1 | .000 | |
| SPA 使用 | [No] | [No] | .106 | .012 | 73.750 | 1 | .000 | 变量 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 | Education_level ‐.097 .005 404.073 1 .000 |
| 2.970 | .077 | 1504.052 1 | .000 | ||||||||||||
| 常数 |
表 7:非用户模型:步骤摘要
| Step 1 1 2
3


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









