




Python实战--多线程编程
一、Python多线程编程基础
1.线程和进程
线程:是在进程里启动的,能调动进程的任何资源,一个进程里多个线程资源共享
进程:是正在运行的程序实体,包括它所占据的系统资源,进程独立存在,不共享资源
Linux只支持多进程,windows支持多线程(开发时注意最终使用场景)
2.并发和并行
并行是真正的同时进行,并发只是用户看上去像同时进行(速度快)
3.Python中全局锁GIL
保证同一时间只有一个线程使用CPU,防止资源错乱,所以Python中都是并发,没有并行
使用多进程可以避免全局锁,(测试一般用多线程)Python多线程适用异步IO密集型(服务器响应,非CPU)
探索异步编程(如asyncio库),处理I/O密集型任务
二、Python实现多线程编程的两种方式
1._thread,threading(常用模块)基础使用
_thread使用手册
重点关注:start_new_thread()
threading使用手册
重点关注:current_thread(),Thread Objects
注意:主线程结束子线程也结束,所以需延迟主线程结束时间
案例一:用_thread完成搬砖
- 基础设置,导入模块,搬砖函数
import _thread
import threading --- 导入2种多线程模块和时间模块
import time
global brick_list --- 把 brick_list 定义为全局变量
brick_list = ['砖头1','砖头2','砖头3','砖头4','砖头5','砖头6','砖头7','砖头8','砖头9','砖头10',
'砖头11','砖头12','砖头13','砖头14','砖头15','砖头16','砖头17','砖头18','砖头19','砖头20',
'砖头21','砖头22','砖头23','砖头24','砖头25','砖头26','砖头27','砖头28','砖头29','砖头30',
'砖头31','砖头32','砖头33','砖头34','砖头35','砖头36','砖头37','砖头38','砖头39','砖头40',
'砖头41','砖头42','砖头43','砖头44','砖头45','砖头46','砖头47','砖头48','砖头49','砖头50',
'砖头51','砖头52','砖头53','砖头54','砖头55','砖头56','砖头57','砖头58','砖头59','砖头60',
'砖头61','砖头62','砖头63','砖头64','砖头65','砖头66','砖头67','砖头68','砖头69','砖头70',
'砖头71','砖头72','砖头73','砖头74','砖头75','砖头76','砖头77','砖头78','砖头79','砖头80',
'砖头81','砖头82','砖头83','砖头84','砖头85','砖头86','砖头87','砖头88','砖头89','砖头90',
'砖头91','砖头92','砖头93','砖头94','砖头95','砖头96','砖头97','砖头98','砖头99','砖头100']
def action(): --- 创建一个action函数
while True: --- 死循环
if len(brick_list) == 0: --- 当砖头数为0的时候可以停下来
break --- break打断死循环
brick_list.pop() --- 搬砖 默认从后往前删除,删除后返回删掉的元素,循环一次删除一个
print(threading.current_thread().name + "还剩%s" , brick_list )
--- 打印线程名,和该线程搬完之后剩多少砖
time.sleep(0.2) --- 限制搬砖的速度,0.2s搬一次,不限制的话搬砖会迅速完成
def main(): --- 定义main函数,我们要运行的代码
***********************
***********************
*****************(待填写)
if __name__ == '__main__': --- 仅执行当前文件
main()
- 主线程搬砖,及运行结果
def main(): --- 定义main函数,我们要运行的代码
action() --- 直接调用action,一个人搬,不使用多线程

- 单一子线程搬砖,及运行结果
def main(): --- 定义main函数,我们要运行的代码
_thread.start_new_thread(action,()) --- 开启一个子线程(调用函数action,不给action传参) 请一个人搬
time.sleep(20) --- 主进程延迟20s结束 = 砖头数100 * 搬砖速度0.2

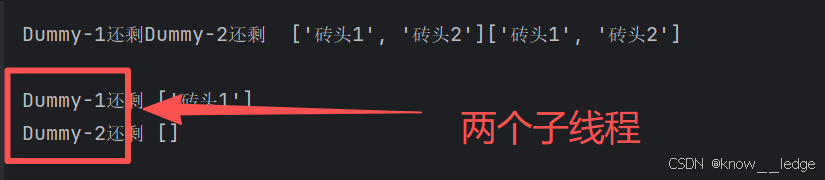
- 两个子线程搬砖,及运行结果
def main(): --- 定义main函数,我们要运行的代码
_thread.start_new_thread(action,()) --- 开启一个子线程(调用函数action,不给action传参) 请一个人搬
_thread.start_new_thread(action, ()) --- 开启一个子线程,请两个人搬
time.sleep(10) --- 主进程延迟10s = 砖头数100 * 搬砖速度0.2 / 子线程数2
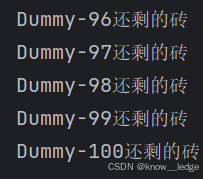
- 100个子线程搬砖,及运行结果
def main(): --- 定义main函数,我们要运行的代码
for i in range(100): --- 请100人搬砖(调用函数action,不传参)
_thread.start_new_thread(action,())
time.sleep(10) # 主进程延迟10s
案例二:用threading完成搬砖
- 基础设置,导入模块,搬砖函数
import _thread
import threading --- 导入2种多线程模块和时间模块
import time
global brick_list --- 把 brick_list 定义为全局变量
brick_list = ['砖头1','砖头2','砖头3','砖头4','砖头5','砖头6','砖头7','砖头8','砖头9','砖头10',
'砖头11','砖头12','砖头13','砖头14','砖头15','砖头16','砖头17','砖头18','砖头19','砖头20',
'砖头21','砖头22','砖头23','砖头24','砖头25','砖头26','砖头27','砖头28','砖头29','砖头30',
'砖头31','砖头32','砖头33','砖头34','砖头35','砖头36','砖头37','砖头38','砖头39','砖头40',
'砖头41','砖头42','砖头43','砖头44','砖头45','砖头46','砖头47','砖头48','砖头49','砖头50',
'砖头51','砖头52','砖头53','砖头54','砖头55','砖头56','砖头57','砖头58','砖头59','砖头60',
'砖头61','砖头62','砖头63','砖头64','砖头65','砖头66','砖头67','砖头68','砖头69','砖头70',
'砖头71','砖头72','砖头73','砖头74','砖头75','砖头76','砖头77','砖头78','砖头79','砖头80',
'砖头81','砖头82','砖头83','砖头84','砖头85','砖头86','砖头87','砖头88','砖头89','砖头90',
'砖头91','砖头92','砖头93','砖头94','砖头95','砖头96','砖头97','砖头98','砖头99','砖头100']
def action(): --- 创建一个action函数
while True: --- 死循环
if len(brick_list) == 0: --- 当砖头数为0的时候可以停下来
break --- break打断死循环
brick_list.pop() --- 搬砖 默认从后往前删除,删除后返回删掉的元素,循环一次删除一个
print(threading.current_thread().name + "还剩%s" , brick_list )
--- 打印线程名,和该线程搬完之后剩多少砖
time.sleep(0.2) --- 限制搬砖的速度,0.2s搬一次,不限制的话搬砖会迅速完成
def main(): --- 定义main函数,我们要运行的代码
***********************
***********************
*****************(待填写)
if __name__ == '__main__': --- 仅执行当前文件
main()
- 两个子线程搬砖,及运行结果
- threading 本身不会随主线程结束自动退出
- threading 的 daemon=True 时为守护线程,主线程运行完毕,守护线程也会自动退出。 daemon=False 时不为守护线程,不会随主线程结束自动退出
def main():
t1 = threading.Thread(target=action,args=(),name="1号工作者",daemon=False)
--- daemon=True时是守护线程
t2 = threading.Thread(target=action,args=(),name="2号工作者",daemon=False)
t1.start() --- threading 本身不会随主线程结束自动退出,无需对时间进行限制
t2.start()
if __name__ == '__main__':
main()

2.使用threading模块进行多线程编程具体介绍
| Threading对象 | 描述 |
|---|---|
| Thread | Thread对象 |
| Lock | 锁原语对象 (原语:指不可分割的多个操作) |
锁原语对象:就是把线程执行任务过程中的多个指令变成不可以被分割的(人造),从而锁定任务,让其他线程无法访问。
| Thread对象 | 描述 |
|---|---|
| name | 线程名 |
| ident | 线程标志 |
| daemon | 表示是否是守护线程 |
| _ _ init_ _(group=None, tatget=None,args=(), kwargs ={},verbose=None,daemon=None | 实例化一个线程对象,需要有一个可调用的target |
| join (timeout=None) | 阻塞,直到达到timeout或者其他线程执行完毕 |
| ident | 线程标志 |
| getName() | 返回线程名 |
| setName (name) | 设置线程名 |
| isAlivel /is_alive () | 线程是否存活 |
| isDaemon() | 判断是否是守护线程 |
| setDaemon(daemonic) | 把线程的守护标志设定为True或者False(必须在线程 start()之前调用) |
1)线程阻塞
线程阻塞概念:把当前运行的线程阻塞,让其停止运行,直至所有其他线程运行完毕后,再继续执行。
语法:Thread( ).join( )
- 用途:当所有子线程都是守护线程,而主线程很快就会结束时,那么我们可以使用.join( )方法,阻塞主线程的运行,让子线程运行完毕之后,再继续运行主线程。
- 举例:用 join 代替 time
def main():
t1 = threading.Thread(target=action,args=(),name="1号工作者",daemon=True)
--- daemon=True时是守护线程
t1.start() --- threading 本身不会随主线程结束自动退出,无需对时间进行限制
t1.join()
2)守护线程和非守护线程
| 守护线程 | 其他线程都运行结束后,守护线程立即结束 |
| 非守护线程 | 无论其他线程有没有运行结束,本线程都必须正常运行结束后才会结束 |
- 守护线程举例:
import threading
from time import sleep
def action(max):
for i in range(max):
print(threading.current_thread().name + "%s次循环" % i)
sleep(1)
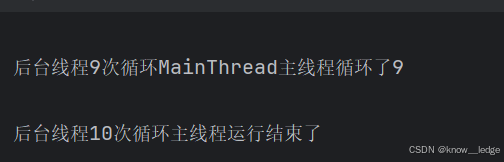
def main():
t1 = threading.Thread(target=action, args=(1000,),name="后台线程") --- 启动后台线程,设置循环1000次
t1.daemon = True --- 在start之前,需要设置守护线程的开关
t1.start() --- 启动后台线程
for i in range(10): --- 让主线程继续运行一会儿,打印循环输出的次数
print(threading.current_thread().name + "主线程循环了%s" % i) --- 打印主线程循环的次数,设置为10次
print("主线程运行结束了")
if __name__ == '__main__':
main()
- 结果:主线程和守护线程一起执行10次结束
3)线程锁(Lock)和信号量
| 线程锁(Lock) | 为了防止线程与线程之间资源共享导致的线程安仝问题,对访问的资源加上线程锁,控制线程先后顺序 |
| 信号量 | 控制访问同一资源的线程数量 |
① 线程锁
- 不加线程锁,子线程运行结果混乱
import threading
import time
result = 0 ----- 全局参数为0
def add(max): ---- 等待传参,参数为循环运行次数
global result
for i in range(max):
result = result + 1 ----- 累加运算
print(threading.current_thread().name,result)
def main():
t1_list = [] --- 创建3个子线程放入列表,调用add函数,传入参数10
for i in range(3):
t1_list.append(threading.Thread(target=add, args=(10,)))
--- 启动列表里的3个子线程
for i in range(3):
t1_list[i].start()
if __name__ == '__main__':
main()
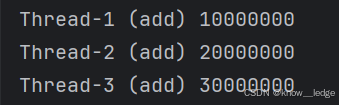
实际结果应为10000000,20000000,30000000

- 加线程锁,相同子线程运行结果与预期相同
| threading,Lock( )对象方法 | 描述 |
|---|---|
| lock.acquire() | 获取锁 |
| lock.release() | 释放锁 |
import threading
import time
result = 0 ---- 全局参数为0
lock = threading.Lock() ---- 获取Lock对象
def add(max): ---- 等待传参,参数为循环运行次数
global result
lock.acquire() ---- 加锁,锁住全局变量,控制线程顺序,第一个线程结束再运行第二个
for i in range(max):
result = result + 1 ----- 累加运算
lock.release() ---- 解锁
print(threading.current_thread().name,result)
def main():
t1_list = [] --- 创建3个子线程放入列表,调用add函数,传入参数10
for i in range(3):
t1_list.append(threading.Thread(target=add, args=(10000000,)))
--- 启动列表里的3个子线程
for i in range(3):
t1_list[i].start()
if __name__ == '__main__':
main()
② 信号量
| threading,Semaphore (3) | 同一时间只能有3个线程处于运行状态 |
|---|---|
| semaphore .acquire() | 获取信号量,信号量减一 |
| semaphore .release() | 释放信号量,信号量加一 |
- 举例:控制进入地铁人的数量
import threading,time
semaphore = threading.Semaphore(500) --- 获取信号量对象,只准许500人进入地铁站,执行运输任务
def action(counts):
print("进入地铁的人数为%s" % counts) ---- 打印未做控制的进入人数
semaphore.acquire() --- 获取信号量,信号量减一
print("%s号乘客进入地铁站台" % counts) ---- 打印控制后进入的人数
time.sleep(10) ---- 设置控制时间
semaphore.release() --- 释放信号量,信号量加一
print("%s号乘客离开地铁站台" % counts)
def main():
for i in range(10000): --- 启动10000个线程人进入地铁
threading.Thread(target=action,args=(i,)).start()
if __name__ == '__main__':
main()
结果 :使用信号量后,人数被加以限制

4)重写Threading方法的run函数,实现自定义Threading
自定义方法可以帮助我们使用更多需要的功能,如:自定义线程名字
①导入threading模块
import threading
②继承threading.Thread类的类
class MyThread(threading.Thread): --- MyThread类能访问到所有threading.Thread类中的属性、方法等
def __init__(self,func,args,name=None): --- 继承后要初始化 __init__方法
threading.Thread.__init__(self) --- 两种初始化写法
-------- super().__init__() --- 两种初始化写法
self.func = func
self.args = args
self.name = name --- 把自定义的内容保存为类属性,使其可以在MyThread里使用
③重写run方法
def run(self):
return self.func(*self.args) --- 写* 代表可以传入多个参数
④定义要执行的任务方法
def add(x,y):
result = x + y
print(threading.current_thread().name +" " + str(result))
⑤在main方法中启动多线程执行任务
def main():
t1 = MyThread(add,(1,2),"t")
t2 = MyThread(add, (11, 22),"T")
t1.start() --- 启动线程
t2.start()
⑥启动main方法
if __name__ == '__main__':
main()
3. 队列
| 队列 | 一种数据结构 |
|---|---|
| 队列的类型 | 双向队列(deque)、先进先出队列、后进先出队列、优先级队列等等 |
| 队列的特点 | 在python中,一切皆对象,所以任何乐西都可以放入队列中,使用队列进行管理。如类、方法、变量等等 |
| 队列的应用 | 亿级吞吐量消息队列Kafka;标准消息队列RabbitMq等等;线程池是基于队列技术实现; |
点击这里 --> 队列用法介绍
用法:
from queue import Queue
q = Queue(maxsize = 10) ~ ~ ~ ~ ~ ~ 创建队列
应用场景:
q.put() 向队伍插入一条数据,并将其标记为“未完成任务”
q.task_done() 减少一条“未完成任务”标记
q.join() 所有任务完成后,停止阻塞,让队列继续工作
- 入门案例
from queue import Queue
q = Queue(maxsize=10) --- 创建队列,maxsize=10是指队列的长度等于10
q.put(1) --- 插入数据
q.put("a") --- 再次插入数据
print(q.get()) --- 提取数据并打印,不设置队列类型时,默认为先进先出
print(q.get())
- 案例,生产者消费者模型:厨师做10个菜通知10个食客吃饭
from idlelib.mainmenu import menudefs
--- 案例:做10个菜通知10个食客吃饭 生产者消费者模型
from queue import Queue
import threading
import time
import random
q = Queue() --- 创建队列
food_menu = ["佛跳墙","红烧肉","烤鸭","清炒时蔬","狮子头","松鼠桂鱼","水煮鱼","地三鲜","凉拌秋葵","凉皮"]
def make_lunch(): --- 创建生产者厨师
print("已经开始做菜了")
while True:
if q.full(): --- 判断队列是否已满
print("菜已经全部上齐了")
q.join() --- 阻塞队列,停止做菜
food_number = random.randint(0,len(food_menu)-1) --- 随机0-9,列表下标
q.put(food_menu[food_number]) --- 按随机顺序做菜单里的10个菜
print("做好了%s" % food_menu[food_number])
time.sleep(0.1) --- 控制做菜的频率
def eat_lunch(): --- 创建消费者食客
time.sleep(10) --- 等菜上桌
if q.empty():
print("厨师快点上菜,饿死了")
else:
food = q.get()
print("吃了%s" % food)
time.sleep(0.5) --- 每吃一个菜都需要休息
q.task_done() --- 通知服务员这个菜吃完了
if __name__ == '__main__': --- 启动两个函数分别担当厨师和食客
cooker = threading.Thread(target=make_lunch,args=(),name="cooker")
eater = threading.Thread(target=eat_lunch,args=(),name="eater")
cooker.start()
eater.start()
运行结果

4.线程池
存放线程的池子,线程池可以控制线程的启动数量和属性状态,从而达到节省系统资源的目的
| 线程池与信号量Semaphore的区别 | |
|---|---|
| 区别1 | 线程池控制线程数量,而信号量控制的是并发数量 |
| 区别2 | 超过信号量规定数量的线程,已经启动了,状态是挂起; |
| 线程池中,超过了线程池规定数量的线程,没有启动,只能等待启动 |
| Python实现线程池的两种方式 | |
|---|---|
| 方式1 | concurrent.futures并发中的ThreadPoolExecutor |
| 方式2 | threadpool库(测试常用于多线程执行用例) |
举例:多线程搬100块砖
- 1)打开pycharm终端,安装threadpool库
pip install threadpool
- 2)导包
import threading
import time
from threadpool import ThreadPool,makeRequests
--- ThreadPool控制线程池大小,makeRequests控制执行的请求
global brick_list # 把 brick_list 定义为全局变量
brick_list = ['砖头1','砖头2','砖头3','砖头4','砖头5','砖头6','砖头7','砖头8','砖头9','砖头10',
'砖头11','砖头12','砖头13','砖头14','砖头15','砖头16','砖头17','砖头18','砖头19','砖头20',
'砖头21','砖头22','砖头23','砖头24','砖头25','砖头26','砖头27','砖头28','砖头29','砖头30',
'砖头31','砖头32','砖头33','砖头34','砖头35','砖头36','砖头37','砖头38','砖头39','砖头40',
'砖头41','砖头42','砖头43','砖头44','砖头45','砖头46','砖头47','砖头48','砖头49','砖头50',
'砖头51','砖头52','砖头53','砖头54','砖头55','砖头56','砖头57','砖头58','砖头59','砖头60',
'砖头61','砖头62','砖头63','砖头64','砖头65','砖头66','砖头67','砖头68','砖头69','砖头70',
'砖头71','砖头72','砖头73','砖头74','砖头75','砖头76','砖头77','砖头78','砖头79','砖头80',
'砖头81','砖头82','砖头83','砖头84','砖头85','砖头86','砖头87','砖头88','砖头89','砖头90',
'砖头91','砖头92','砖头93','砖头94','砖头95','砖头96','砖头97','砖头98','砖头99','砖头100']
lock = threading.Lock() # 加锁,一次只运行一个线程
# 定义搬砖的动作
def action(brick):
lock.acquire() # 加锁,锁住全局变量
print(threading.current_thread().name,brick) # 通过输出表示完成搬砖的动作
lock.release() # 解锁
time.sleep(0.2)
- 3)创建线程池
def main():
# 创建线程池
threadpool_brick = ThreadPool(5) # 最多运行5个线程
- 4)添加任务
# 创建执行的任务
requests = makeRequests(action,brick_list)
- 5)执行任务
# 将任务添加到线程池中,并执行
# for i in requests:
# threadpool_brick.putRequest(i) # 简化成列表推导式
[threadpool_brick.putRequest(i) for i in requests] # 列表推导式,把requests请求放到线程池里
- 6)等待执行
threadpool_brick.wait() # 等待执行完成
if __name__ == '__main__':
main()
结果:线程池控制同一时间最多5个线程启动进行搬砖,结束后线程会不断重新从1开始计数到5。与之不同,信号量会直接计数到100
5. 标准库 concurrent.futures:创建多线程用来并发测试,简化代码
- 导入
from concurrent.futures import ThreadPoolExecutor
- 用法 with ThreadPoolExecutor(max_workers=最大线程数量) as executor:
-
executor.submit(运行函数, 传入参数)
from concurrent.futures import ThreadPoolExecutor
import time
import threading
global thread_my_list
thread_my_list = ["听歌","吃饭","看戏","聊天"]
def doing(doing_name):
print(threading.current_thread().name + "执行的责任为%s" % doing_name)
def main():
for i in range(len(thread_my_list)):
with ThreadPoolExecutor(max_workers=len(thread_my_list)) as executor: # 固定写法
executor.submit(doing, thread_my_list[i]) # 固定写法
if __name__ == '__main__':
main()

















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









