






个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
Transformer与Seq2Seq模型概述
-
Transformer 是一种 Seq2Seq 模型,最初用于机器翻译,但其应用远超翻译领域。
-
Seq2Seq模型的特点:输入输出均为序列,输出长度由模型自动决定,适合处理如语音识别、机器翻译等任务。应用场景包括语音识别、翻译、聊天机器人、问答系统、目标检测等
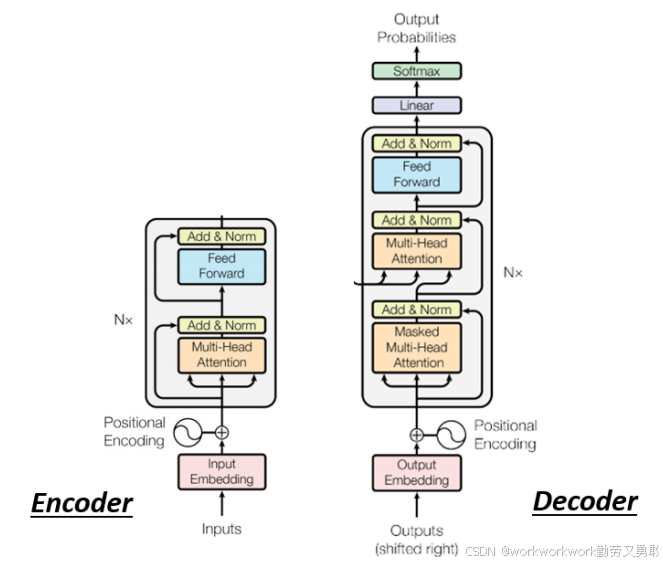
Transformer的编码器Encoder结构详解
-
Encoder作用:将输入的序列转换成另一组表示(vector sequence)。
-
主要结构包括:
-
Self-Attention(自注意力机制):捕捉序列中元素之间的关系。
-
Feed-Forward Network(前馈神经网络):处理每个位置的特征,这个结构是 两层全连接层 的组合,中间加一个激活函数
-
Residual Connection(残差连接):保留原始输入特征,缓解梯度消失。
-
Layer Normalization(层归一化):标准化每个样本的所有维度。
-
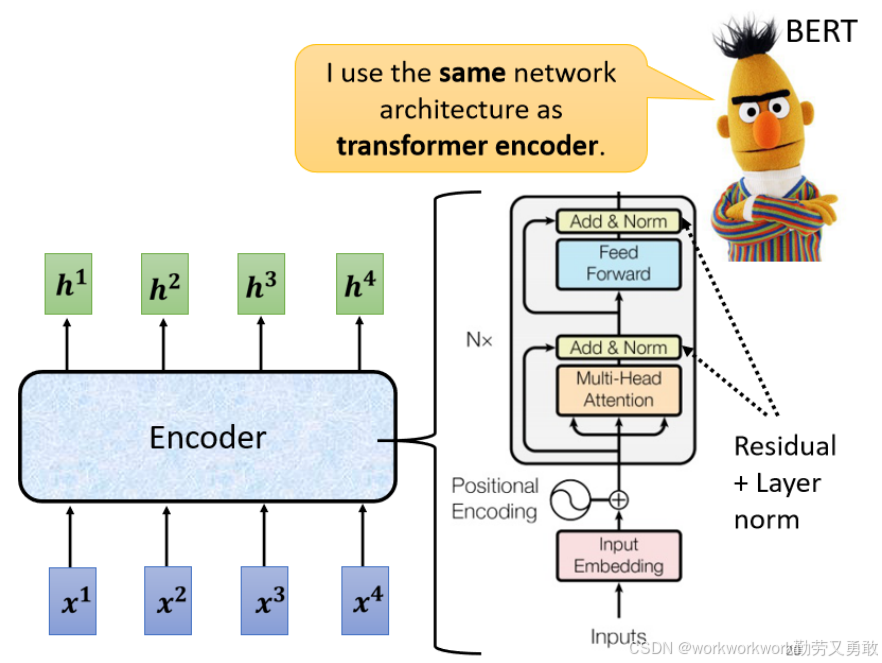
Encoder由多个相同结构的Block组成,每个Block包含Self-Attention、Feed-Forward、Residual和Layer Norm。
Block = 信息融合 (通过 Attention)+ 特征增强(通过 Feed-Forward) + 稳定训练(通过 Residual + LayerNorm)的打包结构,是 Transformer 的最小功能单元。
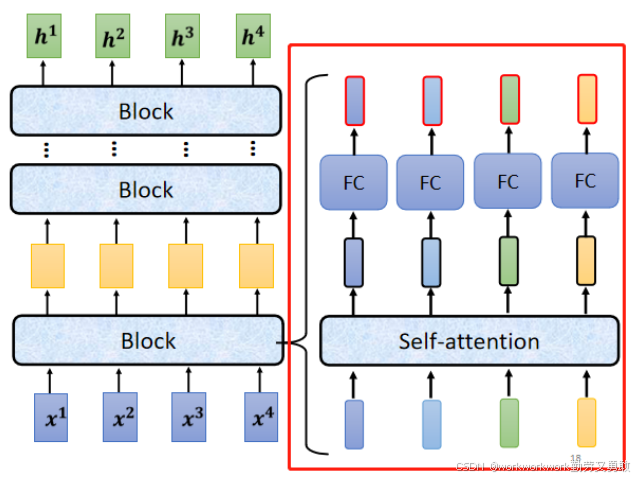
Residual Connection (残差连接)
Transformer 并不是仅使用 Self-Attention 的输出作为最终结果,还会将原始输入加回来。这种设计叫做 Residual Connection。假设有一个输入向量 b,经过一个变换函数,比如 Self-Attention 通常是:Output=a,残差连接会把输入 b 原样加回来:Output=a+b
作用:
-
保留了原始输入的信息;
-
在深度学习中能防止梯度消失,提升训练效果;
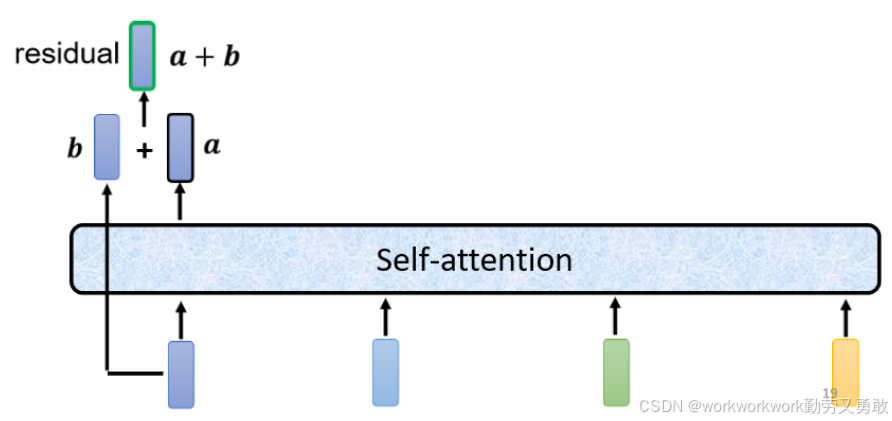
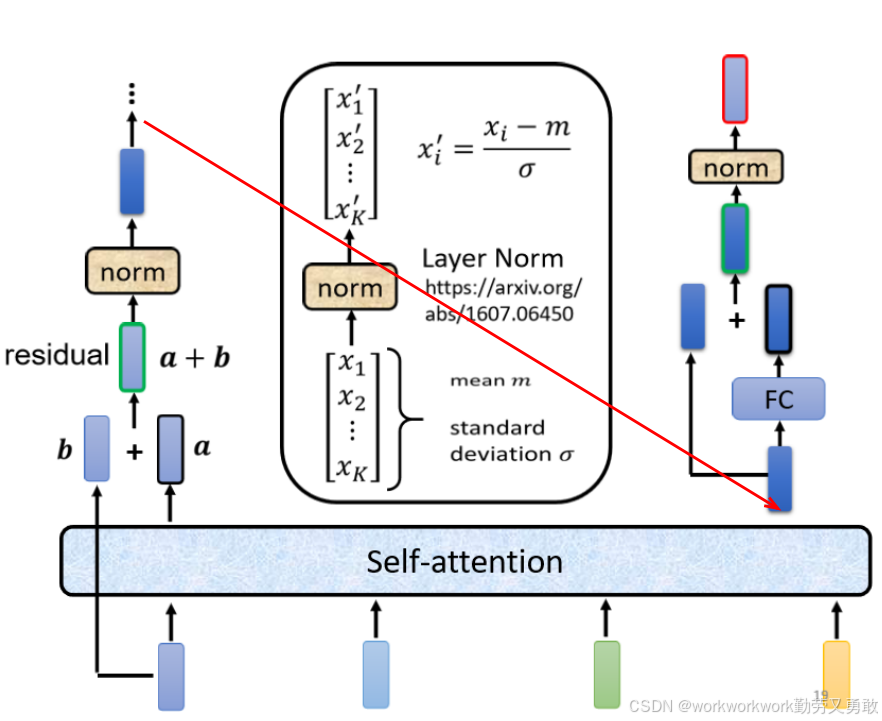
Layer normalization(层归一化)
LayerNorm 是对一个向量(比如一个 token 的表示)在维度上做归一化,和 BatchNorm 不同,batch是对不同样本向量的同一维度的值去进行归一化。
Transformer 中 解码器Decoder 的结构与运作原理
Decoder有两种,Autoregressive Decoder(AT)与Non-Autoregressive Transformer(NAT)。
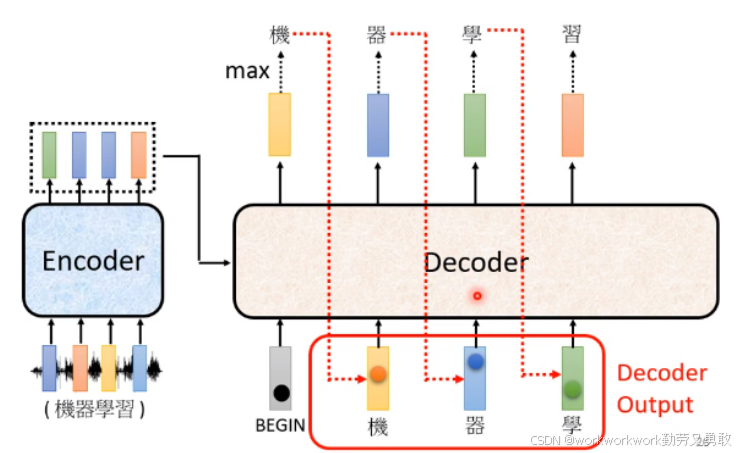
Encoder:负责理解输入;Decoder:负责生成输出,接下来以语音辨识为例
-
Encoder:把声音(连续的向量)转成语义向量(“你说了啥”)
-
Decoder:逐字生成“你说了机器学习”,直到输出 END
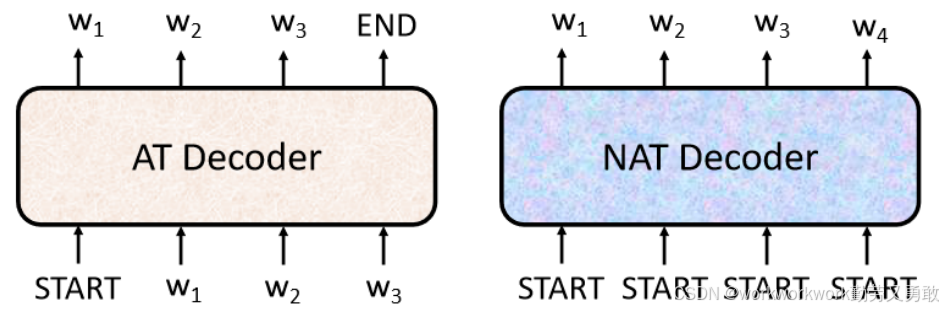
自回归解码器Autoregressive Decoder(AT)的基本机制
-
一次生成一个 标记token,当前输出作为下一步输入。生成的token都是用one-hot vectot表示,其长度(以输出中文为例)就是字典里字的数目
-
使用 BOS (Begin Of Sentence) 开始,END 表示结束。
-
每一步都会预测整个词表的概率分布(Softmax),取概率最大者作为输出。
-
输入来自 Encoder 的输出 + 当前历史 token 序列。
-
使用遮罩注意力Masked Self-Attention:只能看到当前位置左边的 token,防止“偷看未来”。
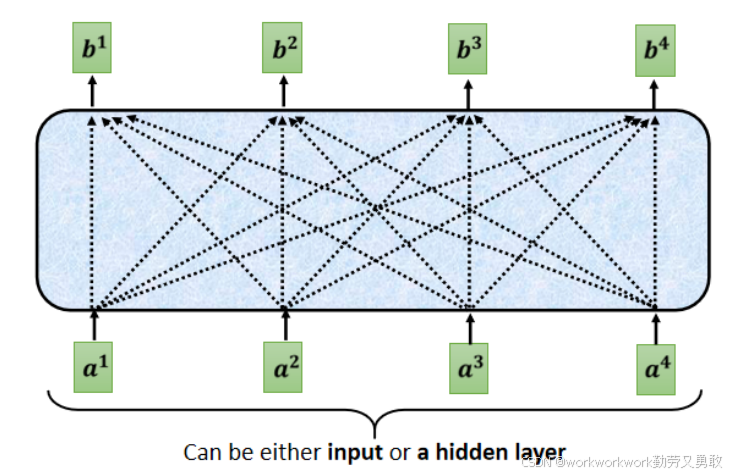
其中masked的意思是这样的,原来是self attention长这个样子,这样是为了理解句子,每个输出都要考虑整个输入
李老师说生成自己的句子的时候,比如生成b1,我们不应该考虑a2,a3,a4。同理,生成b2时我们不应该考虑a3,a4。所以masked self attention长这个样子
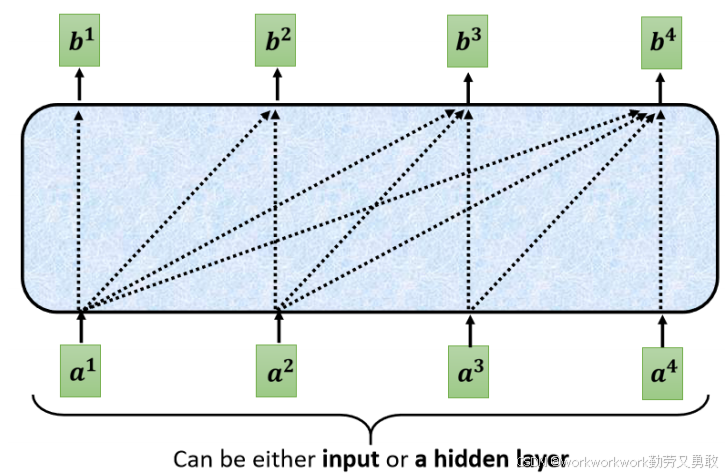
详细来说是这样,计算b2时q2只考虑k1,k2
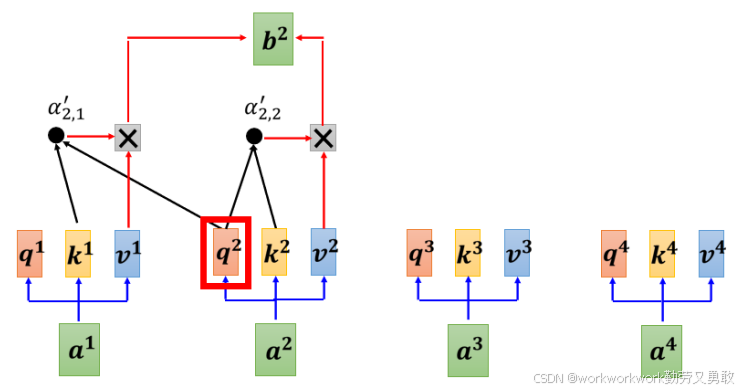
为啥会这样呢?其实很简单,因为"当前输出作为下一步输入"这条规则,在decorder中,a2来自上一步的输出b1,所以考虑b1时,根本不存在a2,a3,a4。
断END:在自回归(Autoregressive)生成任务中,比如文本生成、翻译、语音识别,模型一个一个地输出 token,但模型不知道输出该是多大,不知道什么时候该停下来。如果你不告诉它什么时候结束,它可能会一直生成下去,甚至陷入死循环。END 是告诉模型:“这句话生成完了,可以停了”的信号。
非自回归解码器Non-autoregressive Decoder(NAT)的基本机制
NAT和AT的主要区别在于:
-
一次性生成所有 token,而非逐步生成。
-
输入是多个 BEGIN token。
-
由于输出长度未知,输出长度可通过:
-
另一个预测器(Classifier)决定;
-
或者设一个固定最大长度,例如 300。
-
NAT的优点在于:高度并行化,速度快;更易控制输出长度,适合语音合成等任务。
NAT的缺点在于:生成质量普遍低于 AT。存在 Multi-Modality 问题(输出结果模糊不清,需要大量技巧修正)。
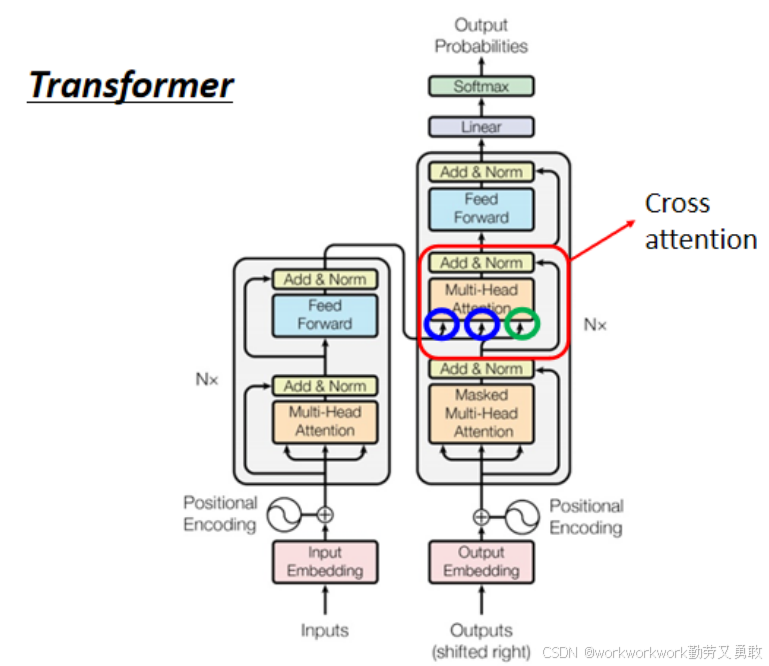
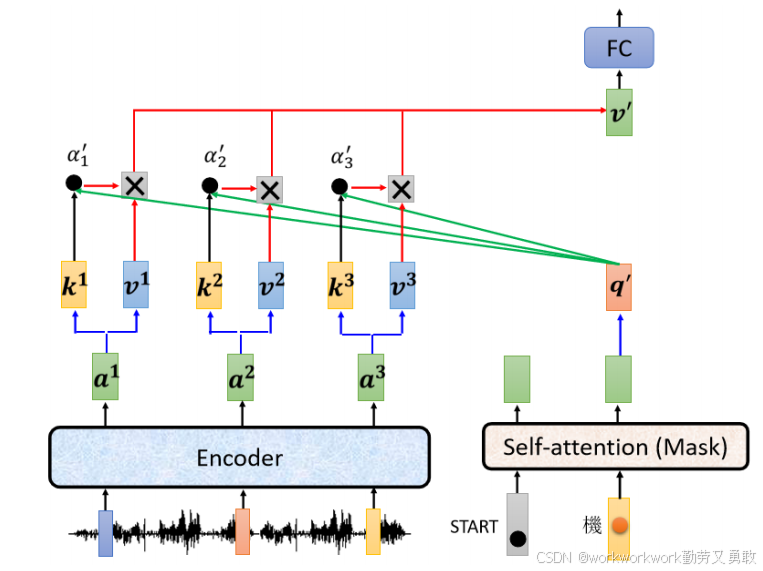
Encoder与Decodrer间的通信:Cross Attention
-
交叉注意力机制Cross Attention 是 Decoder 与 Encoder 之间的桥梁:
-
Decoder 中的 Query(来自自身产生);
-
Key 和 Value(来自 Encoder 的输出)。
-
-
每一层 Decoder 默认只看 Encoder 的最后一层输出,但也可以尝试更复杂的连接方式。
训练过程
-
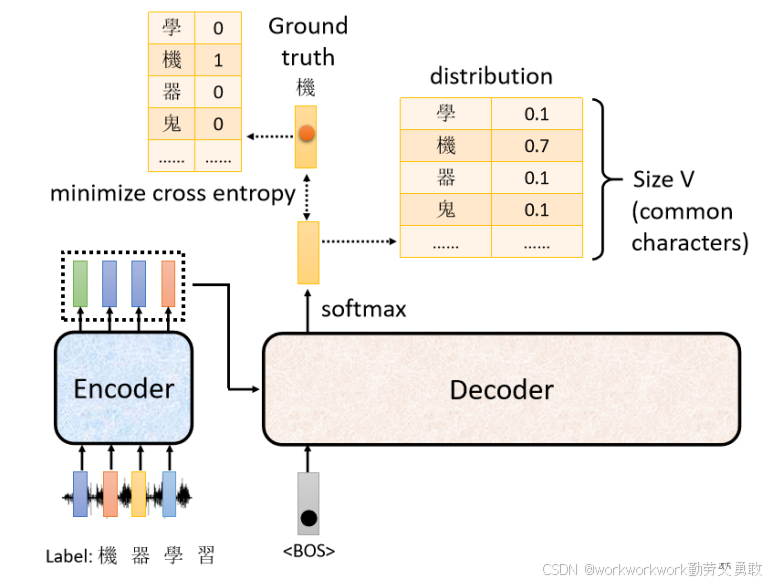
训练时会把每一步生成的(distribution)与真实输出(ground truth)对比,使用交叉熵Cross Entropy Loss(分类那一章提到的)的总和判断是否接近,我们希望我们的输出,跟这真实答案的 One-Hot Vector 越接近越好。
-
实际上是多分类任务(每步是词表大小的分类问题)。
-
为什么训练时需要喂真实答案?训练的时候,如果让它用自己的输出作为下一步输入,一旦输出错了,接下来就越错越离谱,难以学习。但这也会导致训练测试不一致的问题(Exposure Bias)。至于怎么解决在后文有提到
训练技巧与补充内容
1. 拷贝机制Copy Mechanism
-
适用于对话系统、摘要等任务,让模型能直接“复制”输入中的内容,有些东西没必要自己再去生成,比如人名之类的,其实不用生成直接复制就好。

2. 引导注意力Guided Attention
-
用于语音任务,约束 Attention 由左到右,避免忽略输入。
-
特别适合语音合成、语音识别等顺序性强的任务。
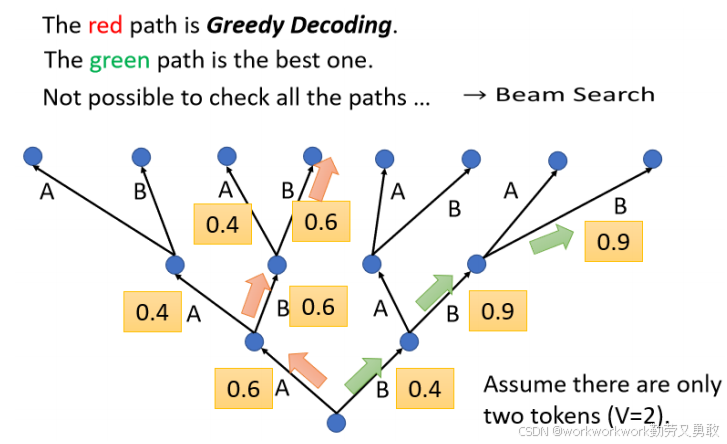
3. 束搜索Beam Search
-
寻找最优输出序列的启发式方法。
-
有时比 Greedy 更好,但不总是,特别是在创造性任务中可能导致文本重复。但对于答案很明确的,这种方法可能有用
-
如下假设只能生成两个字母,每一次在第一个 Time Step,它在 A B 裡面决定一个,然后决定了 A 以后,再把 A 当做输入,然后再决定 A B 要选哪一个,每次都选最高的就是Greedy Decording,相比红色的,绿色虽然一开始第一个步骤选了一个比较差的输出,但是接下来的结果是好的。找出这种绿色路径的方法就是Beam Search
4. 计划采样机制Scheduled Sampling
-
假设 Decoder 在训练的时候 , 永远只看过正确的东西 , 那在测试的时候 , 你只要有一个错 , 那就会 一步错步 步错,因为 对 Decoder 来说 , 它从来没有看过错的东西 , 它看到错的东西会非常的惊奇 , 然后导致结果错误。
-
可以通过有意给Decoder加入一些错误的东西(比如自己生成的结果),缓解训练测试不一致问题(Exposure Bias)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









