






个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
一、问题背景
-
Training Stuck ≠ Critical Point:训练过程中 loss 停止下降,不一定是因为参数到了 critical point(梯度趋近于0),很多时候是由于梯度震荡或方向问题。
-
示例说明,即使梯度不小,loss 也可能停止下降,尤其是在“山谷”两侧震荡时。
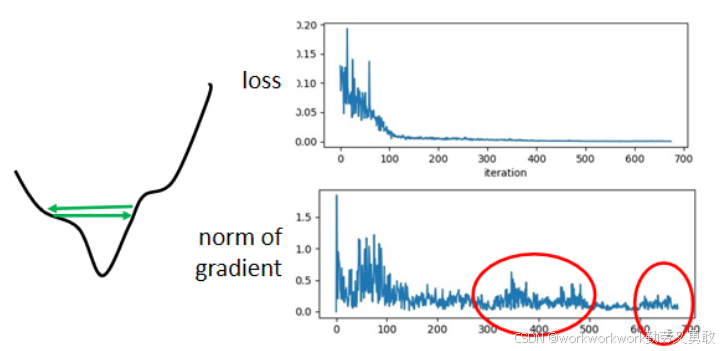
虽然loss不再下降,但是梯度的大小并没有真的变得很小
二、优化困难的原因
-
即便是在简单的 convex(凸)error surface 中,使用固定学习率的 gradient descent 也可能表现不佳:
-
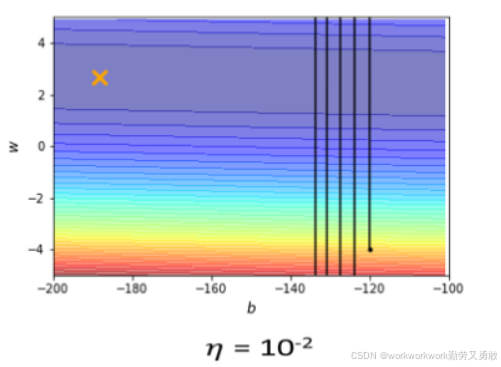
学习率太大 → 震荡不断
-
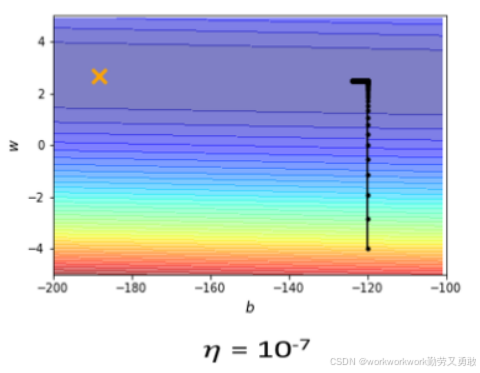
学习率太小 → 更新速度过慢甚至停止
-
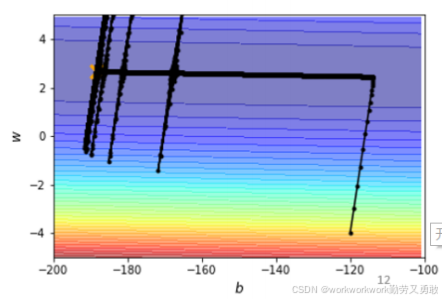
例如下图
-
-
原因在于不同方向上梯度变化率差异大,单一学习率无法兼顾所有参数。
-
假设打叉的地方是loss最小点,从黑色点出发学习率太大会导致震荡且很难往打叉的地方运动
如果学习率很小,在梯度大的地方没问题,到了梯度g本身很小的地方,乘以学习率后就更小,移动的就更慢了
三、自适应学习率方法
总体思路是这样的,原来的是这样的,学习率固定
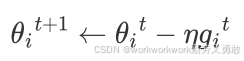
改成
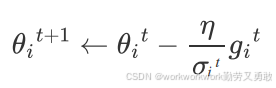
通过 σ 来调节η
1. Adagrad
-
根据过去所有的梯度平方求平均再开根号(RMS)作为每个参数的缩放因子。
-
梯度大 → 缩放因子σ大 → 实际学习率小。
-
梯度小 → 缩放因子σ小 → 实际学习率大。
-
缺点:长期累计,小的学习率可能变得太小,训练停滞。
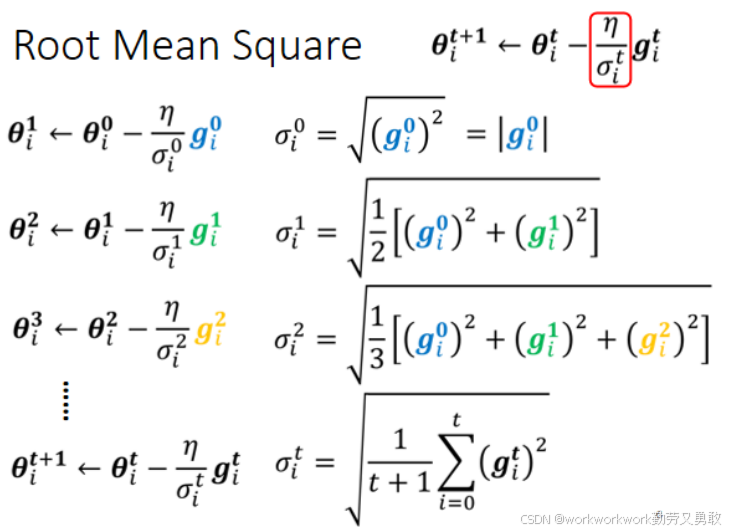
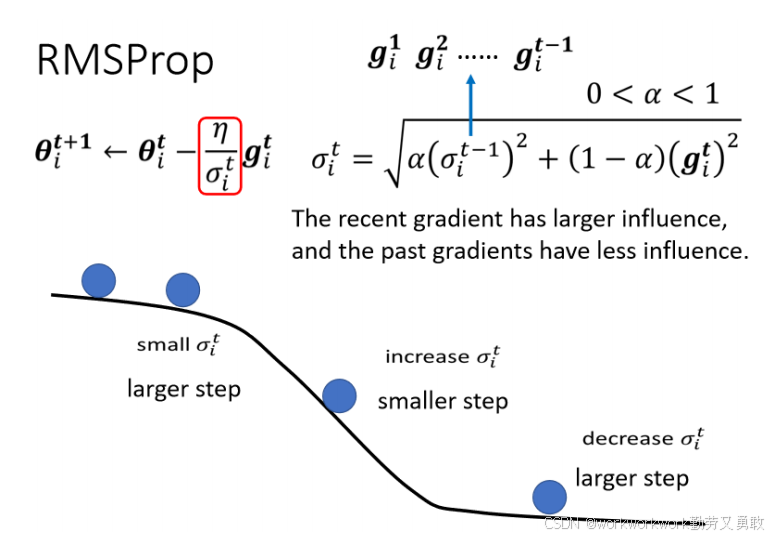
2. RMSProp
-
解决 Adagrad 的衰减问题。
-
使用指数加权移动平均的方式计算梯度的平方均值(引入超参数 α):
-
最新的梯度可以占更大比重,反应更快。
-
-
对突变的误差面能做快速响应,适应性更强。
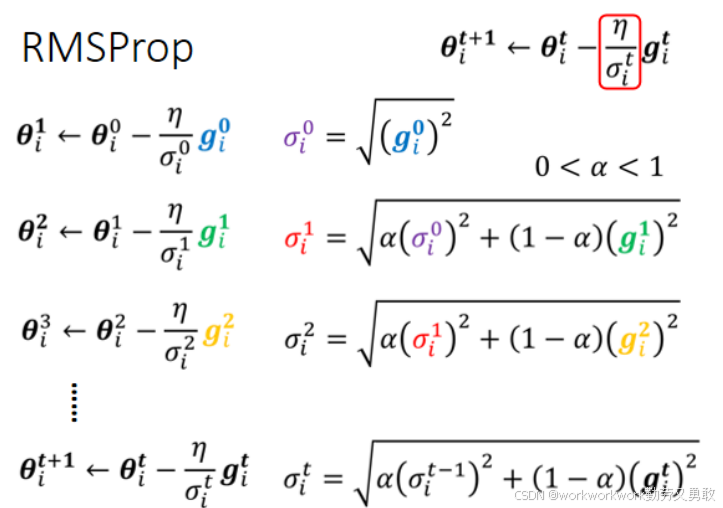
3. Adam
-
是 RMSProp + Momentum 的结合。
-
Momentum:保留过去梯度方向的“惯性”,用于平滑更新。
-
在 PyTorch 等框架中广泛使用,默认参数通常表现良好。
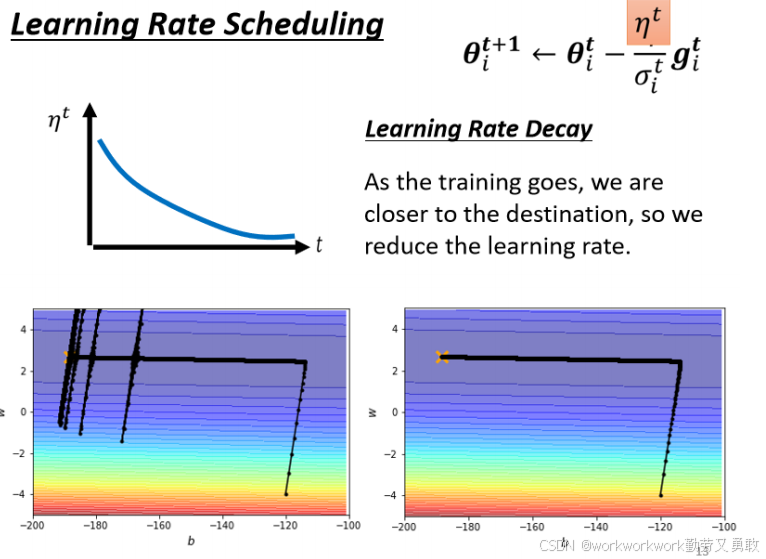
4. 学习率调度策略
李老师给出的例子是使用Adagrad跑,走到终点的时候突然爆炸,原因:在平坦的谷底积累太多小g,导致σ变小,学习率变大,虽然会修正回来但是浪费时间。
学习率调度策略简单来说就是学习率随着训练步数增加而减小
主要介绍了两种策略,一种是Learning Rate Decay,随着时间的不断地进行,随着参数不断的update,η让它越来越小,在靠近收敛点时起“刹车”作用,防止参数过度更新。
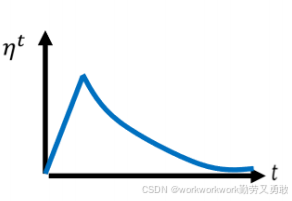
另外一种是Warm up
-
一开始用较小学习率,逐步增大,再慢慢减小。
-
用于让优化器前期收集“信息”,避免过早跳出合理区域。σ告诉我们,某一个方向它到底有多陡,或者是多平滑,那这个统计的结果,要看得够多笔数据以后,这个统计才精准,所以一开始我们的统计是不精准的。
-
常用于 BERT、ResNet、Transformer 等大型模型训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









