



优化失败 ≠ Overfitting
Loss 不下降可能是卡在Critical Point(临界点)
-
指梯度为零的点,即 ∇L(θ) = 0
-
这类点训练停滞,无法继续更新参数。
-
三类 Critical Point:
-
Local Minima:局部最小值(四周都比它大)
-
Local Maxima:局部最大值(四周都比它小)
-
Saddle Point(鞍点):部分方向是最小,部分方向是最大 —— 最常见的情况!
-
判断临界点的方法:泰勒展开

如果走到了临界点, 绿色框里的就为0,能否继续下降让L更小取决于后面一项,严格来说只取决于H,有如下三种状态:全大于0,全小于0,有的大于有的小于0
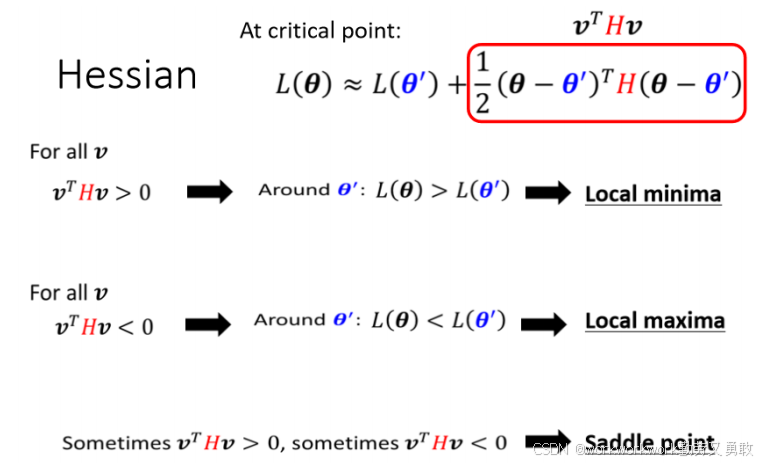
更直观的判断方式是用特征值,什么是特征值我差点忘了哈哈哈哈哈,考研线代白学


PS:实际情境中,鞍点更常见一点;计算特征值的方法看有没有优化路线的方法基本也不会用,此处只是介绍一下
防止优化失败的措施
1、选择合适的Batch大小
知识点:

由于并行计算的原因,大Batch不一定算的慢,由于update次数少,跑完一个Epoch可能还快点
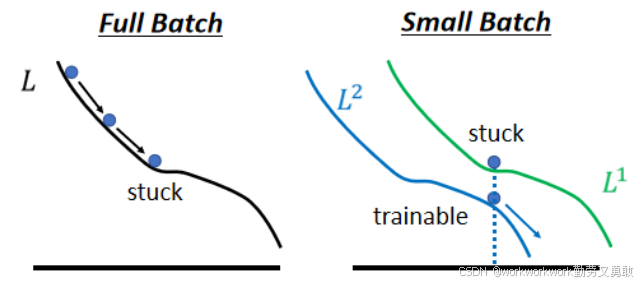
2、小Batch对优化的帮助
如下图大Batch遇到临界点,不去看H的特征值可能就卡住了,小Batch每次都是新Batch,可能就逃出临界点了
3、小Batch对泛化的帮助
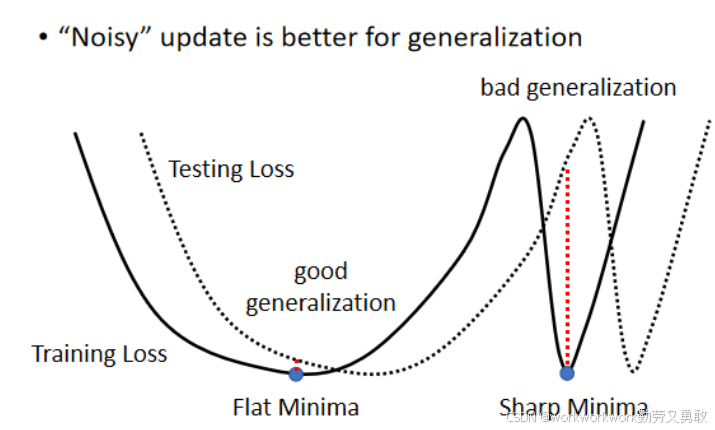
大量实验显示,在相同训练精度下:小 Batch 的测试集准确率往往更高。
原因可能是:
-
小 Batch 更容易停留在“平坦的盆地”中,这类解对 testing 的扰动更不敏感。
-
大 Batch 更容易进入“狭窄的峡谷”,泛化性差。
-
例如下图,虚线代表测试集的loss,实线是训练集的loss,他们之间的差距就导致同一个θ在训练集中算出的是极小值,在测试集里就不是,而停留在“平坦的盆地”中的局部极小值,即使有一些差距导致偏离,也不会差太多,而“狭窄的峡谷”中的极小值,偏离一点点可能就导致偏差特别大
-
 4、动量法Momentum
4、动量法Momentum -
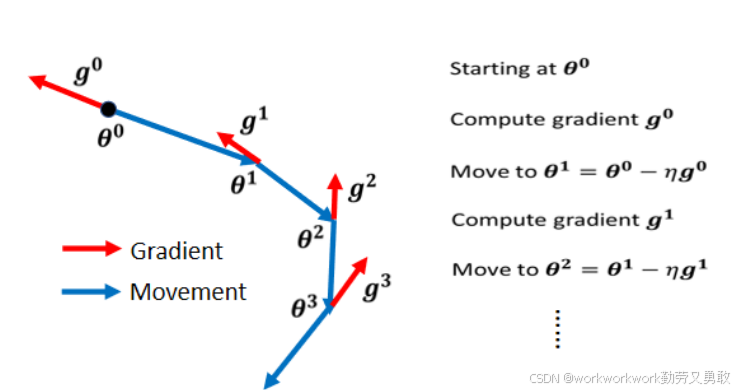
普通梯度下降遇到 gradient 为 0 的点(如 saddle point、local minima)会停止;
-
Momentum 模仿物理上的惯性:让参数带着“惯性”继续前进。
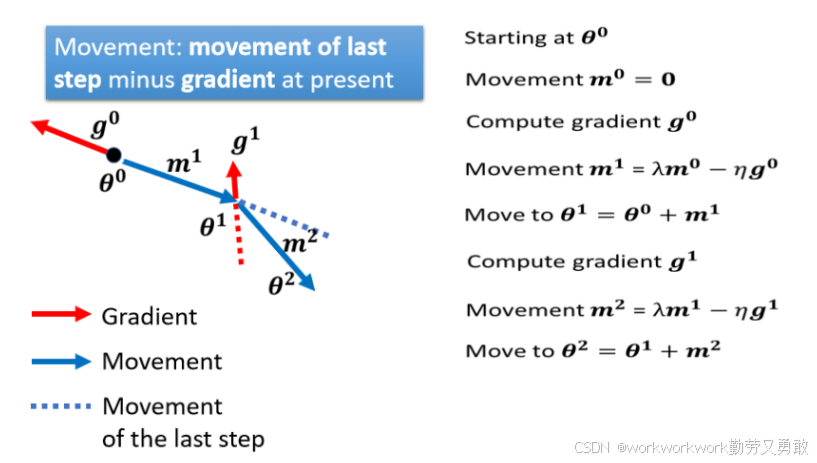
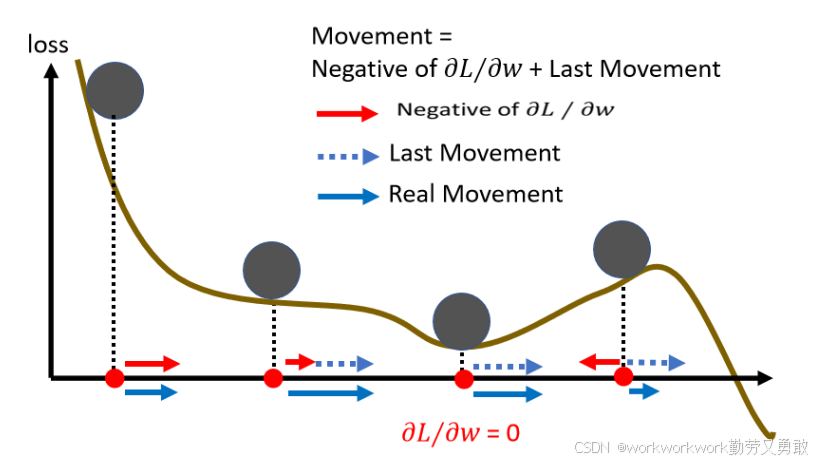
如下图所示,带有动量会让loss跨过小山丘


















 4102
4102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









