



训练效果不佳的判断流程
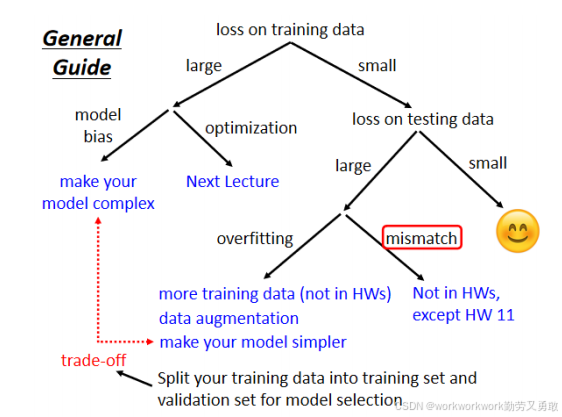
Step 1:先检查训练集 loss 是否够小
若不小,可能是以下两个问题:
1. Model Bias(模型偏差)
-
模型太简单,函数集合太小,无法表达理想函数。
-
解决方案:增加模型容量,如:
-
增加输入特征维度
-
使用更深层的神经网络
-
使用更复杂的模型架构(如 Deep Learning)
-
2. Optimization 问题(优化失败)
-
模型容量足够,但 Gradient Descent 卡在局部最优。
-
判断方法:
-
用浅层模型(如 SVM、线性模型)先试,获得 baseline。
-
若更深模型反而 loss 更高,则可能是优化问题。
-
-
经验总结:看到一个你从来没有做过的问题,也许你可以先跑一些比较小的,比较浅的network,或甚至用一些,不是 deep learning的方法
Step 2:若训练 loss 小但测试大,则可能是 Overfitting
原因:
-
模型“记住”训练数据,泛化能力弱。
-
常见于模型自由度太高、数据太少。
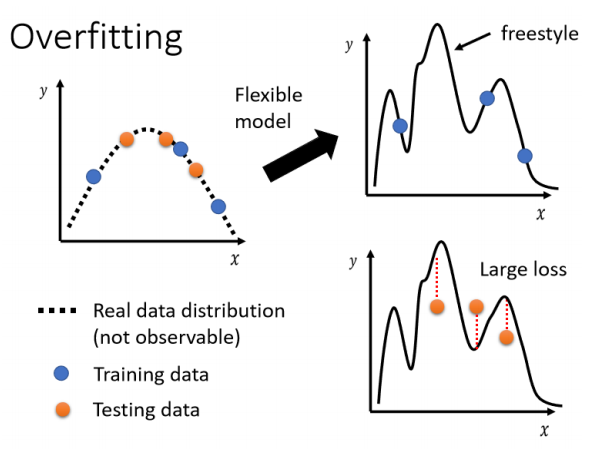
例如如下的图,实际的模型是虚线(未知),蓝色的点代表训练集,数量比较少,如果模型自由度很高,它训练的结果可能如图右所示随便长长,虽然在训练集上loss很小 ,输入x与理想的y完全匹配,但是换成测试集后就不一样了(橙色点):
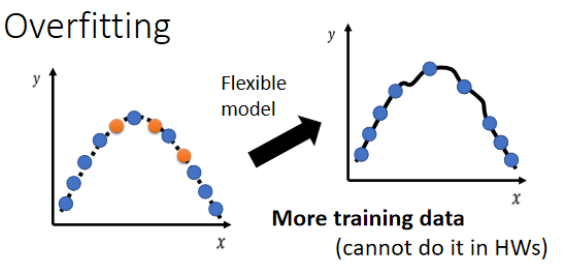
解决方法:
-
增加训练数据
-
Data Augmentation:如图像左右翻转、缩放等。
-
注意:Augment 要有“道理”,不能乱做。
-

-
限制模型复杂度,不要让它弹性太大
-
减少参数数量、神经元数量
-
使用共享参数(如 CNN)
-
使用 Regularization、Dropout、Early Stopping 等方法
-
模型复杂度的取舍
-
模型太简单 → model bias;
-
模型太复杂 → overfitting;
-
最佳模型:能在 training 和 testing 都取得低 loss。
-
不建议频繁依赖 Kaggle公开排行榜选模型:
-
每次提交后都能看到 public score,容易不自觉地围着它“调参”,但这会让你的模型越来越贴合 public test 的分布,却对 unseen 的 private test 表现不佳。可能 overfit 到 public set,导致 private set 成绩惨烈。
-
如何选择合适的模型:交叉验证
方法:
-
把训练集划分为训练集 和 验证集。验证集就是在训练过程中,模型从来没有见过验证集里的数据,所以它能帮助你判断模型是否具有“泛化能力”(即在没见过的数据上表现得好不好)。
-
在 验证集 上评估模型,挑选最优模型。
-
举个例子:训练集:你平时刷的练习题,用来学习和掌握知识;验证集:你做的模拟题,用来检查你是不是真的学会了,而不是死记硬背;测试集(test set):就是正式考试卷子(比如 Kaggle 给你的测试数据),你不能提前看到答案。
-
N-fold CV:划分为 N 份,轮流验证并取平均评估,选择最稳定的模型。如下图,先把你的训练集切成N等份,在这个例子裡面我们切成三等份,切完以后, 你拿其中一份当作Validation Set,另外两份当Training Set,然后这件事情你要重复三次 。

然后接下来 你有三个模型,你不知道哪一个是好的,你就把这三个模型,在这三种设置下,在这三个 Training集跟Validation集上面,通通跑过一次,然后把这三个模型,在这三种状况的结果都平均起来, 把每一个模型在这三种状况的结果,都平均起来,再看看谁的结果最好


















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









