




pandas读取Excel、csv文件中的数据时,得到的大多是表格型的二维数据,在pandas中对应的即为DataFrame数据结构。在处理这类数据时,往往要根据据需求先获取数据中的子集,如某些列、某些行、行列交叉的部分等。可以说子集选取是一个非常基础、频繁使用的操作,而DataFrame的子集选取看似简单却有一定复杂性。本文聚焦DataFrame的子集选取操作逻辑,力求在实战中遇到子集选取操作的需求时"不迷路"。
一、图解DataFrame
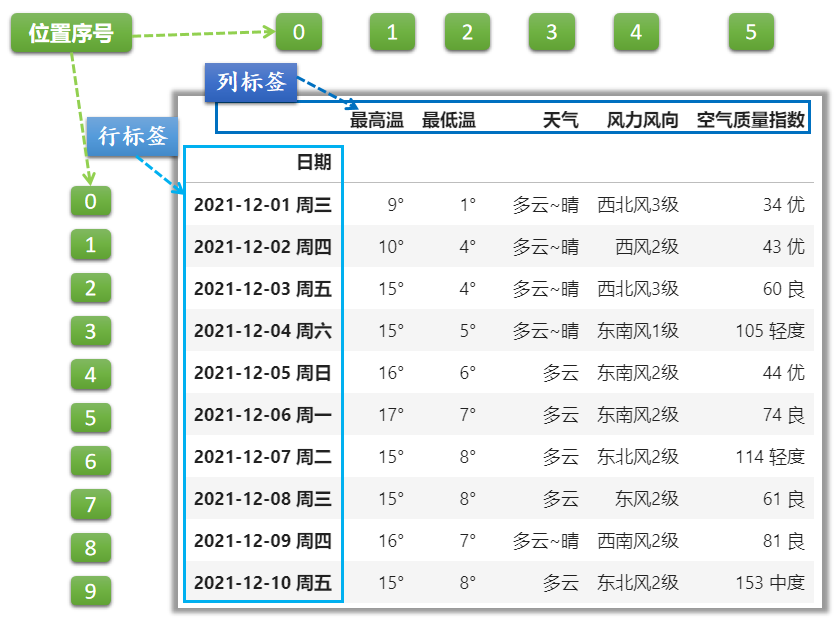
DataFrame是一种二维的表格型数据结构,每一行/列都有对应的标签和位置序号。行列标签、位置序号的对应关系如下图所示:

- 列标签(也叫列名:columns)
- 行标签(也叫行索引:index)默认为(0, 1, 2, …, n)。这里与位置序号恰好一致。
针对DataFrame的数据结构,pandas提供了三种获取子集的索引器:[]、.loc[]、.iloc[]。
-
df[]:快捷的整行整列选取 -
df.loc[]:按标签的行列交叉选取 -
df.iloc[]:按位置序号的行列交叉选取
二、整行整列选取:df[]
1df['列标签'],选取单个整列
# 选取“日期”列
df['日期']
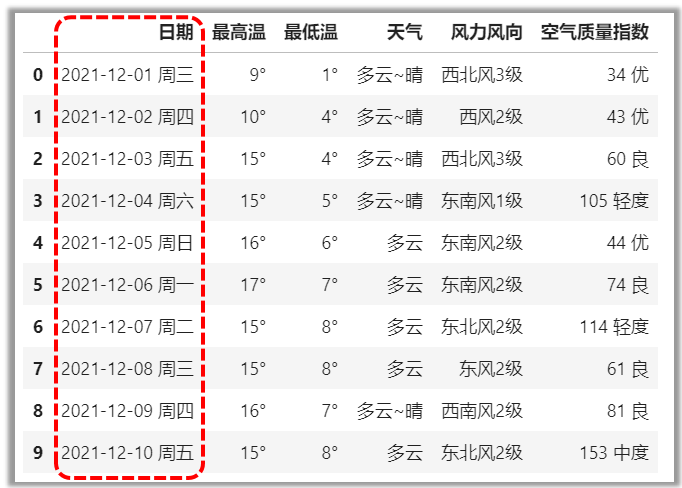
2df[标签列表],选取多个整列
# 选取“最高温”,“最低温”,“风力风向”三列
df[['最高温','最低温','风力风向']]
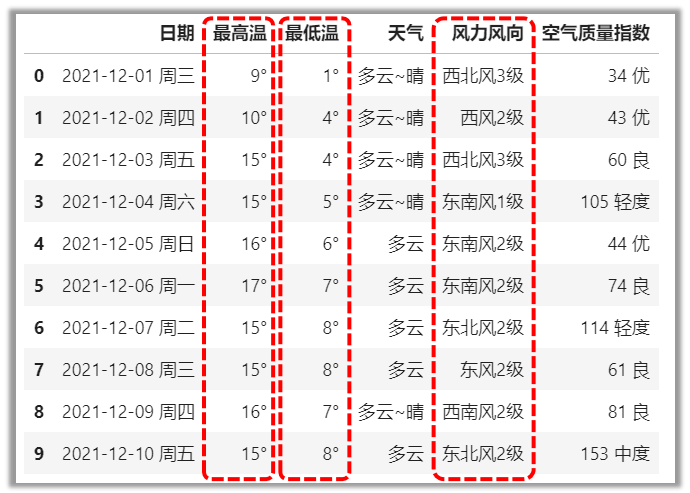
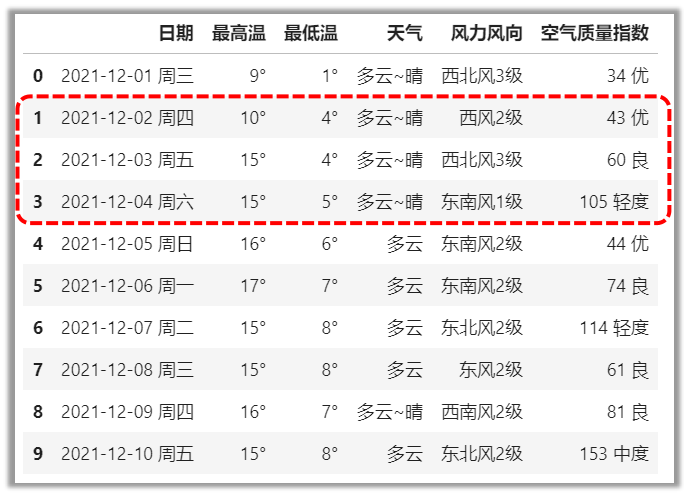
3df[切片],选取整行
# 选取行索引值1、2、3的整行。切片左闭右开
df[1:4]
切片语法也支持字符串的索引标签值,如将"日期"列修改为行索引(index)
df1 = df.set_index("日期")
# 下面两个切片选取的行是一样的
df1[1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









