




先说结论,其实LLaMA-omni做的就挺好的,思路基本对,所以我今天也围绕着它讲
在O1出来之前,其实多模态是上个世代比较火的技术类型,而大模型的趋势也从O1以后就分开来了
-
一个是感知能力的提升,主要是GPT4-o这种的,多模态,单一模型的能力
-
一个是O1这种self-play,自己玩自己(类自博弈)主要解决的是智力和解决问题能力的提升
我之前讲过草莓,后面会随着我深度学习的课程继续讲的更细,因为GPT4o最亮眼的实时语音功能上线了,大家对这个特别感兴趣,所以我就讲一下,但是因为Close AI众所周知的缘故,我就按着类似功能的论文讲了,只是从延迟能力上讲,这个是实现最接近的。
老规矩,论文地址:
2409.06666 (arxiv.org)
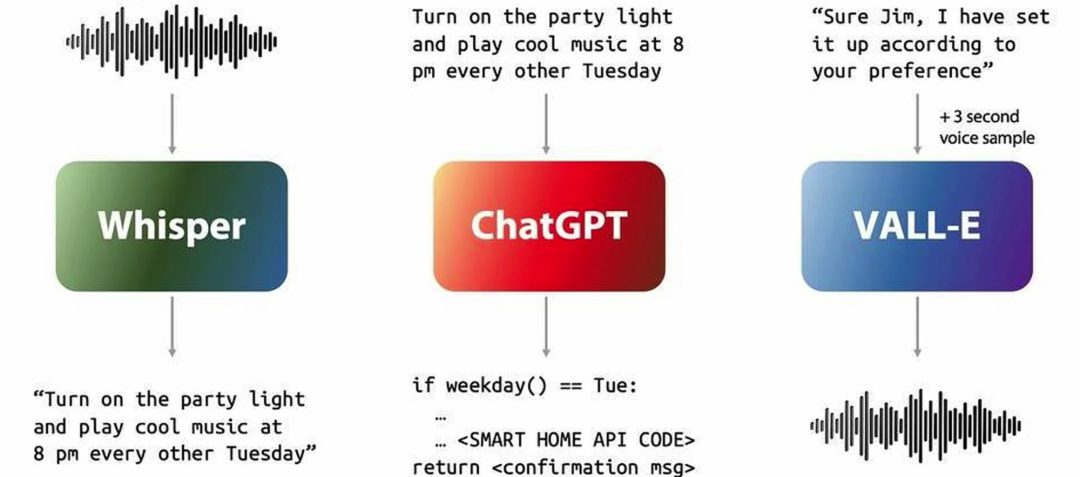
GPT4o其实一直就支持语音,只是那个不是端到端,比如你说句话半天才响应你,因为是多模型架构,以下是我们面对的问题。
-
Whisper ASR要转text问题,GPT去拿text问题推text答案,text用VALL-E转语音
-
因为,折腾好几遍,慢,而且因为传统的tts,一般都是整句话整明白再转,就更慢。
-
另外,Whisper如果端到端坐下来,就是个ASR转文字了,所以只保留了语义部分,其他的比如背景音,笑声都丢了,情感感知几乎是不可能的事
要先解决慢的问题
几秒争取到几百毫秒,GPT4o-advanced real-time voice API是350ms左右
思路:
1- Whisper 别做端到端的ASR就能省出来不少时间
2- 流式相应,不用整个句子都推完就给声音解码
拿LLaMA-Omini来举例
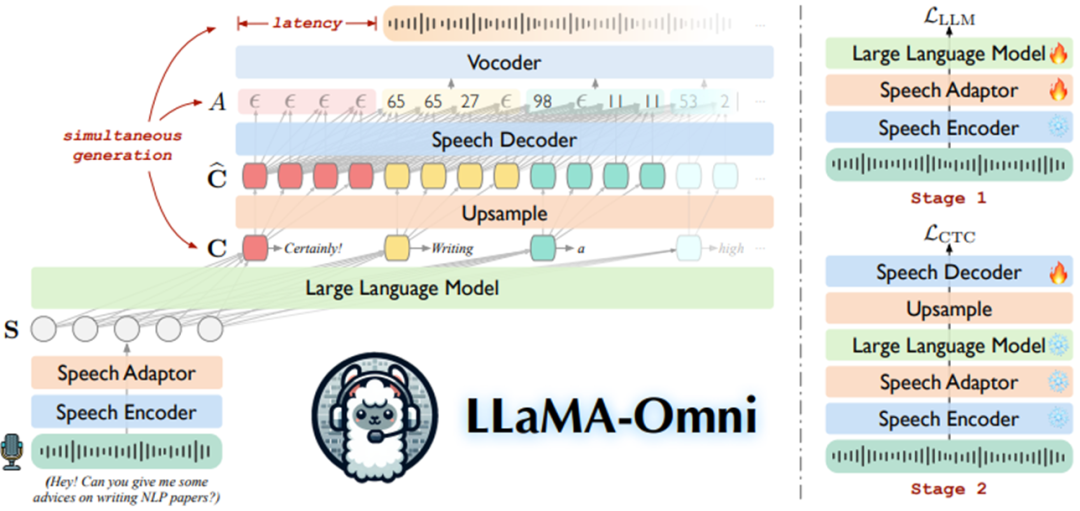
这网络其实很简单的,训练也容易,如果不考虑泛化,特定任务也还是可以的。
网络部分的组成,主要有从下往上几个网络组成
1- Speech Encoder:就用了Whisper-Large-3的encoder功能,负责voice转speech representations
2- Speech Adaptor:下采样
3- LLM就是LLmMA-3.1-8b
4- Speech Decoder:上采样
5- Vocoder: Decoder,负责离散
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









