




我之前出差带休假差不多两个礼拜吧,今天回北京更新一篇
我确实找到了一个有意思的东西,LivePortrait
这东西开源了,你可以认为是目前做得最好的"Sadtalker",国内也有dream-talker,EMO之类的。
我之前看EMO的效果最好,先不说EMO(它虽然标称A2V,实际上就是ASR+T2V+openpose)这种不开源,光拿git上挂个demo测不出来好坏,实际产品力有待观察,主要是LivePortrait的表情位移和精确度要吊打其他任何一个目前我看到的产品,包括EMO。
有兄弟也会说了,这Sadtalker有什么可说的,SDwebui的插件就玩过,那你错了,咱们频道从来不讲具体应用软件,也不愿意码代码,咱们还是讲的咱们老铁愿意听的东西。
讲什么呢?
就讲它发的这个论文 2407.03168 (arxiv.org)
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
效果还是不错的。
那具体技术有什么创新点呢?
其实有,但是都是微创新
首先模型分为两个阶段训练
第一阶段,在考虑了Diffusion路径还是其他路径之后,快手的LivePortrait团队, 没有选择市面上比较流行的Diffusion架构来做自己的模型,而是采用了GAN网络,直接从比较成熟的一个开源的paper Face-vid2vid开始做起。
face-vid2vid (nvlabs.github.io)
face-vid2vid也是很早的一个东西了,Nvidia team发的论文,Sadtalker的核心思想就是它。
为了承上启下,给没看过这块的老铁们简单讲讲这个face-vid2vid都干了啥?
简单说它就是能从一个图片s和一个给定的视频d(大多数是头部视频为主),用图片里的那个人来重生成一个能张嘴说话的视频d'
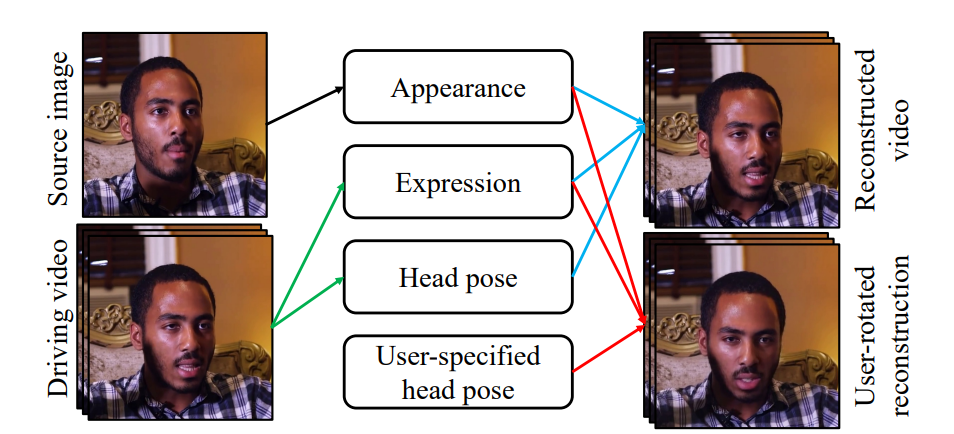
上面的图展示了face-vid2vid模型的工作流程和功能。
-
左侧:有两个输入,分别是源图像s(Source image)和驱动视频d(Driving video)。
-
中间:有四个模块,分别是外观(Appearance)、表情(Expression)、头部姿态(Head pose)和用户指定的头部姿态(User-specified head pose)。
-
右侧:有两个输出,分别是重建视频(Reconstructed video)和用户旋转后的重建视频(User-rotated reconstruction)。
工作流程上:
-
源图像s(Source image):这是模型的起始输入,提供了目标视频中主体的基本外观特征。
-
驱动视频d(Driving video):这是另一个输入,提供了模型需要模仿的表情、头部姿态等动态信息。
-
模块解释:
-
外观(Appearance):从源图像中提取的主体外观特征,用于确保合成视频中的主体外观与源图像一致。
-
表情(Expression):从驱动视频中提取的表情信息,用于在合成视频中模仿驱动视频的表情变化。
-
头部姿态(Head pose):从驱动视频中提取的头部姿态信息,用于在合成视频中模仿驱动视频中的头部运动。
-
用户指定的头部姿态(User-specified head pose):用户可以手动指定头部姿态,用于控制合成视频中的头部方向。
-
-
重建视频(Reconstructed video):将外观、表情和头部姿态结合起来,生成与驱动视频中的动态信息匹配的新视频。
-
用户旋转后的重建视频(User-rotated reconstruction):结合用户指定的头部姿态,生成特定方向上的视频。
训练的方法呢?
-
将一段视频给拆帧,每一帧的3D关键点都用序列表示,同时3D关键点表示被分解为 人物身份表示 和 运动信息表示。使用无监督学习方法学习这些3D关键点。
-
可以对 人物身份的3D关键点表示 进行3D矩阵变换,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









