




 本文详细介绍了特斯拉DOJO超级计算系统的非分离架构,强调其存算一体设计,减少布线,并与A100进行对比。重点讲解了Dojo Core的组成,包括前端、执行引擎、SRAM和Noc路由,特别是矩阵计算单元,展现其高效率和低延迟特性。
本文详细介绍了特斯拉DOJO超级计算系统的非分离架构,强调其存算一体设计,减少布线,并与A100进行对比。重点讲解了Dojo Core的组成,包括前端、执行引擎、SRAM和Noc路由,特别是矩阵计算单元,展现其高效率和低延迟特性。
最近把欠读者的连载的坑先填完,再开新坑,除非有特别的事件驱动临时更新新内容以外
书接前文:特斯拉 DOJO超级计算系统究竟是个啥?(1) (qq.com)
复习一下上节课的内容
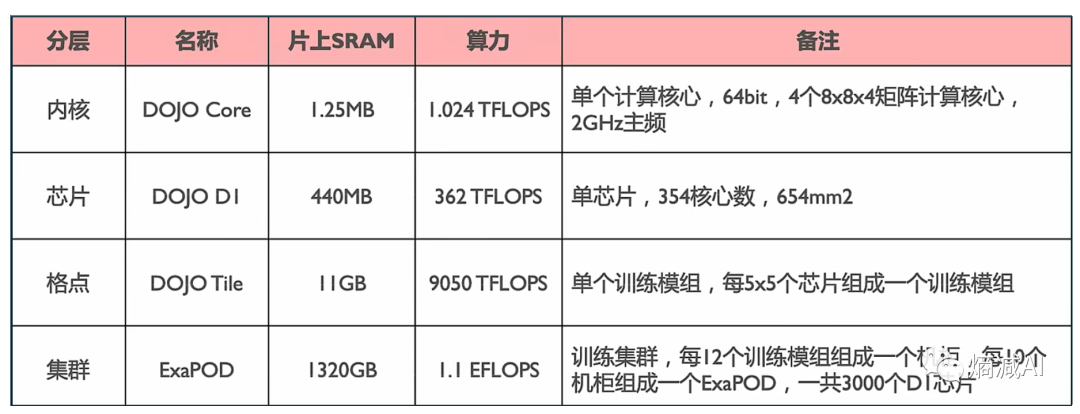
总结一下Dojo的几个特点:
-
非分离架构,存算一体:这其实也会是今后的方向,因为你存CKPT越快,你训练速度越快,以后的所有训练架构肯定都不会做存算分离,这是趋势,片内片外都是
-
每个core都可以扩展到D1或者D2,每个D1或者D2都能扩展到Tile,积木式玩法,大概率是今后自产芯片的趋势,(我司的Maia也是,但是没细粒度到Core级别,后面我会讲)
-
减少布线:core--->D1--->Tile几乎都是尽可能片内,减少布线,算力堆叠降低延迟
-
效率最大化,内核就给2Ghz,除了分支预测和小指令的缓存,其他面积全给NPU组件,向量和矩阵计算单元,和Nvidia相比,良心到极致,反正也是自己用

-
能省就省:Dojo core没有数据端缓存,没虚拟内存,不支持精确异常处理,说白了Dojo 等于战神GTR,"我不会让你等到弯道,而是在直道就开始加速干翻你!

"
Dojo和比它早出1年的A100做个对比
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









