




 本文探讨了CUDA与非CUDA生态在GPU计算领域的竞争,特别是AMD的ROCm、Intel的OneAPI以及Huawei的CANN框架。尽管AMD的ROCm和Intel的OneAPI试图挑战CUDA的主导地位,但CUDA庞大的开发者社区和完善的生态系统使其保持领先地位。Huawei的昇腾芯片和MindSpore框架则选择建立独立生态,借助国内市场的机遇寻求突破。
本文探讨了CUDA与非CUDA生态在GPU计算领域的竞争,特别是AMD的ROCm、Intel的OneAPI以及Huawei的CANN框架。尽管AMD的ROCm和Intel的OneAPI试图挑战CUDA的主导地位,但CUDA庞大的开发者社区和完善的生态系统使其保持领先地位。Huawei的昇腾芯片和MindSpore框架则选择建立独立生态,借助国内市场的机遇寻求突破。
首先声明,我不是卖卡的,至少截止2023年10月22日我都不是,所以个人认为我能相对公正的描述客观事实,写这个的目的是因为第一篇文章有读者朋友提到了能不能出一期CUDA和非CUDA生态的对比,所以有了这篇文章。
什么是CUDA就不解释了,各位读者大爷可能比我还了解,至于为什么说CUDA厉害,我相信很多人也会举很多例子,包括但不限于:
-
主动被动代码
-
SIMD
-
Threads,Blocks,Grids
-
包含了API、C编译器等极其方便的调度体系
-
利用片内L1 Cache共享数据,使数据不必经过内存-显存的反复传输 shader之间甚至可以互相通信
其实要想写能写整整一篇,那这些能力是不是别的硬件服务商不具备呢?
我们先拿AMD来说事吧,因为纸面数据上据称对LLM优化的MI300X在很多维度已经超过H100了例如:
-
HBM3管够!
-
晶体管达到1530亿是目前全球最大的逻辑处理器比H100多700亿
-
内存达到了192GB,内存带宽为5.2TB/s,虽然H100NVL可以,但是那是两块卡
-
CPU部分集成了24个ZEN4内核
-
GPU部分集成了6块使用CDNA3架构的芯片统一内存可降低不同内存间来回复制、同步和转换数据所导致的编程复杂性,采用3D堆叠优于H100的2.5D
甚至从A100/MI200的时代,AMD就拿算力说过事,可以在他们官网上找到相关的信息
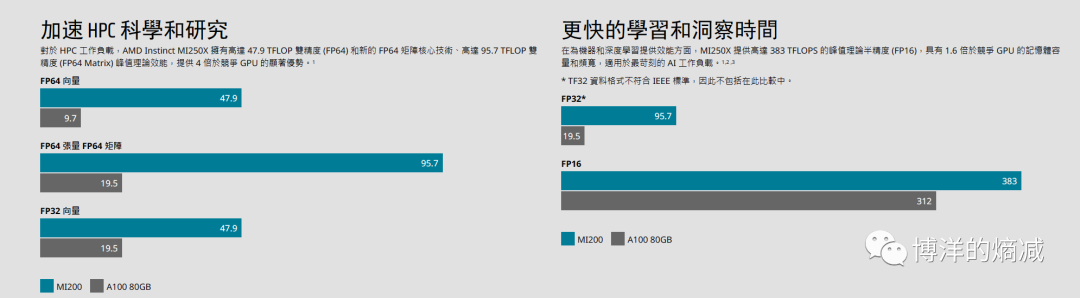
但是销量上的对比我们大抵是知道的,我相信很多读者甚至都没听说过MI这个系列,单提MI200,可能会以为是小米的新手机发布了。
远古时期不考虑了,AMD算是做GPU比较早的玩家,因为它2006收购了ATI, 但是并没有像Nvidia一样发展GPU在DC里的业务。正是同一年Nvidia推出了CUDA, 吴恩达曾经这样说过,在CUDA出现之前,世界上玩GPU编程的也就一百来人,CUDA推出以后,谁都可以玩GPU编程。
看到DC生意也太能挣钱了,作为重要对手的AMD坐不住了,但是种种原因自家的ROCm在2016年才发布,ROCm具有很多的局限,例如,操作系统长期只能支持Linux,最近才登录Windows,说一个具象化的数据,在Github上,贡献CUDA软件包仓库的开发者超过32600位,而ROCm只有不到600个...
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1222
1222




 到【灌水乐园】发言
到【灌水乐园】发言







