







 本文介绍了强化学习的基础,将其定义为马尔可夫决策过程(MDP),涵盖状态、动作、状态转移函数、奖励、折扣因子等关键概念。MDP用五元组表示,描述智能体与环境的交互,其中状态和动作空间是有限的。强化学习的目标是通过优化策略最大化长期奖励的期望值。
本文介绍了强化学习的基础,将其定义为马尔可夫决策过程(MDP),涵盖状态、动作、状态转移函数、奖励、折扣因子等关键概念。MDP用五元组表示,描述智能体与环境的交互,其中状态和动作空间是有限的。强化学习的目标是通过优化策略最大化长期奖励的期望值。
【引言】强化学习技术历经几十年的发展,理论严谨,应用广泛;而强化学习与深度学习相结合而形成的深度强化学习技术在视频游戏、即时战略游戏、围棋等领域达到了人类顶尖水平。上一篇博客介绍了强化学习的发展历史,这篇博客将介绍一个用于描述强化学习过程的强有力的工具——马尔可夫决策过程, 然后介绍强化学习智能体的构成要素。(参考文献见本系列第一篇博客)
希望读者能有以下方面的基础知识:
- 概率论
- 随机过程
目录
中英文术语对照表
| 中文 | 英文 | 缩写或符号 |
|---|---|---|
| 马尔可夫决策过程 | Markov decision process | MDP |
| 状态空间 | state space | S \mathcal{S} S |
| 动作空间 | action space | A \mathcal{A} A |
| 转移函数 | transition function | T \mathcal{T} T |
| 奖励函数 | reward function | R \mathcal{R} R |
| 轨迹 | trajectory | τ \tau τ |
| 回报/收益 | gain | G G G |
| 折扣因子 | discount factor | γ \gamma γ |
| 策略 | policy | π \pi π |
| 分幕任务 | episodic tasks | |
| 连续任务 | continuing tasks |
1. 强化学习是一个马尔可夫决策过程
强化学习是一类基于反馈的学习[184][103]:存在一个智能体能够观察环境的状态和奖励信息,基于状态产生某个动作并执行,环境受到智能体动作的影响后转入下一个状态并给予智能体新的奖励。智能体的目标是在与环境不断的交互中最大化长期奖励和的期望。
图1 强化学习中智能体与环境的交互过程
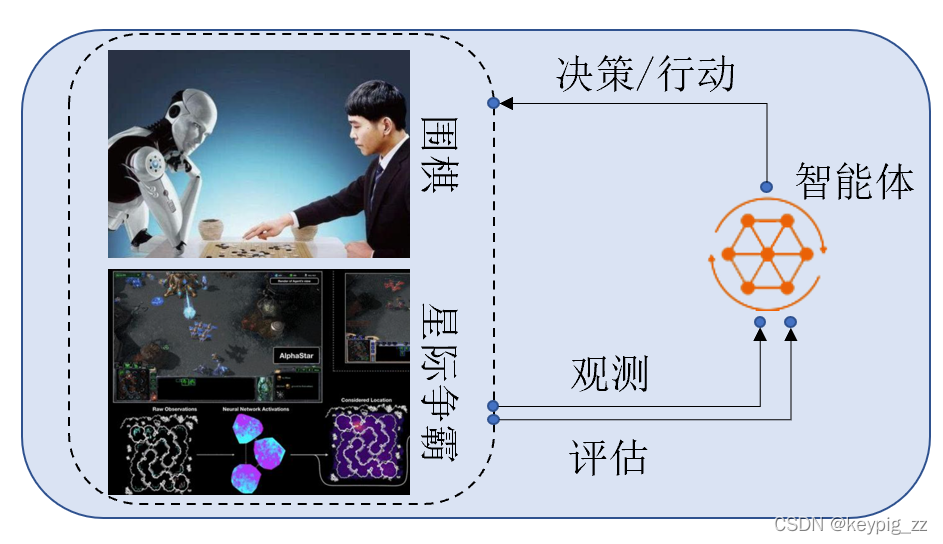
图2 智能体与环境交互简化图
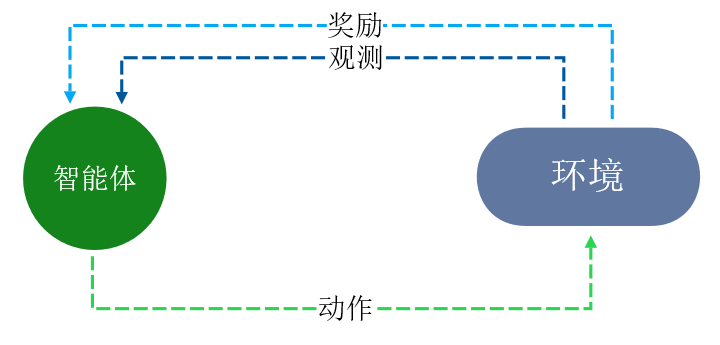
智能体与环境交互的过程如图1和图2,使用马尔可夫决策过程对其进行建模:一个马尔可夫决策过程用五元组表示:
⟨
S
,
A
,
R
,
T
,
γ
⟩
\langle \mathcal{S},\mathcal{A},\mathcal{R},\mathcal{T},\gamma\rangle
⟨S,A,R,T,γ⟩,其中
S
\mathcal{S}
S表示智能体的状态空间,
A
\mathcal{A}
A表示智能体的动作空间,
T
\mathcal{T}
T表示状态转移函数,
R
\mathcal{R}
R表示奖励函数,
γ
∈
[
0
,
1
]
\gamma\in[0,1]
γ∈[0,1]为奖励折扣因子。将时间离散化为
0
,
1
,
⋯
,
t
,
⋯
0,1,\cdots,t,\cdots
0,1,⋯,t,⋯,智能体与环境交互的过程可以描述为:在
t
t
t时刻,智能体观测到环境状态为
S
t
∈
S
S_t\in\mathcal{S}
St∈S,执行动作
A
t
∈
A
A_t\in\mathcal{A}
At∈A,环境以概率
T
(
S
t
,
A
t
,
S
t
+
1
)
\mathcal{T}(S_t,A_t,S_{t+1})
T(St,At,St+1)转移到下一个状态
S
t
+
1
∈
S
S_{t+1}\in\mathcal{S}
St+1∈S,智能体获得奖励
R
t
+
1
=
R
(
S
t
,
A
t
,
S
t
+
1
)
R_{t+1}=\mathcal{R}(S_t,A_t,S_{t+1})
Rt+1=R(St,At,St+1)。随着智能体与环境交互的进行,二者共同形成一条交互轨迹,用
τ
\tau
τ表示:
τ
:
S
0
,
A
0
,
R
1
,
S
1
,
A
1
,
R
2
,
⋯
\tau: S_0,A_0,R_1,S_1,A_1,R_2,\cdots
τ:S0,A0,R1,S1,A1,R2,⋯
1.1 状态和状态空间
上述马尔可夫决策过程中,状态空间 S \mathcal{S} S是一个有限非空集合,假设状态空间包含 N N N个离散状态,则状态空间为 S = { s 1 , s 2 , ⋯ , s N } \mathcal{S}=\{s_1,s_2,\cdots,s_N\} S={s1,s2,⋯,sN}。状态空间中的每一个元素都是抽象的,是环境信息的总和,如围棋中棋盘和棋子构成的盘面,或者游戏智能体获得的关于对手的位置、血量、武器类型构成的游戏局面。在某一时刻的状态用随机变量 S t S_t St来表示,对应的取值用 s t s_t st表示。
1.2 动作和动作空间
动作空间 A \mathcal{A} A是一个有限非空集合,假设动作空间包含 K K K个动作,则动作空间为 A = { a 1 , a 2 , ⋯ , a K } \mathcal{A}=\{a_1,a_2,\cdots,a_K\} A={a1,a2,⋯,aK}。动作空间中的每一个元素都是抽象的,是智能体对环境施加影响的行为总和,如围棋中智能体选定的下一步落子的位置,或者游戏智能体针对当前局面执行的由位移、攻击、协防等构成的一组行为。在某一时刻的动作用随机变量 A t A_t At表示,对应的取值用 a t a_t at表示。
1.3 状态转移函数
智能体在状态 S t S_t St下,决策并执行动作 A t A_t At,环境进入下一个状态 S t + 1 S_{t+1} St+1。状态转移函数描述的是状态转移过程中,各种转移方式发生的概率 T ( s t + 1 ∣ s t , a t ) {\mathcal T}({s_{t + 1}}|{s_t},{a_t}) T(st+1∣st,at): S × A × S → [ 0 , 1 ] {\mathcal S} \times {\mathcal A} \times S \to [0,1] S×A×S→[0,1] ,简记为 T ( s t , a t , s t + 1 ) {\mathcal T}({s_t},{a_t},{s_{t + 1}}) T(st,at,st+1),或者用条件概率 p ( s t + 1 ∣ s t , a t ) = p ( S t + 1 = s t + 1 ∣ S t = s t , A t = a t ) p({s_{t + 1}}|{s_t},{a_t})=p({S_{t+1}=s_{t + 1}}|S_t={s_t},A_t={a_t}) p(st+1∣st,at)=p(St+1=st+1∣St=st,At=at)表示。显然,状态转移函数 T \mathcal{T} T满足: 0 ≤ T ( s t , a t , s t + 1 ) ≤ 1 0 \le {\mathcal T}({s_t},{a_t},{s_{t + 1}}) \le 1 0≤T(st,at,st+1)≤1。假设所有状态和动作都是离散的,则有 ∑ s t + 1 ∈ S T ( s t , a t , s t + 1 ) = 1 \sum\limits_{{s_{t + 1}} \in {\mathcal S}} {\mathcal T} ({s_t},{a_t},{s_{t + 1}}) = 1 st+1∈S∑T(st,at,st+1)=1。
1.4 状态转移函数的马尔可夫性
如果状态的转移只与当前状态和动作有关,而与之前的所有动作都无关,那么这个交互过程具有马尔可夫性[186],即
Pr
(
S
t
+
1
∣
S
t
,
A
t
,
S
t
−
1
,
A
t
−
1
,
⋯
)
=
Pr
(
S
t
+
1
∣
S
t
,
A
t
)
(
2.1
)
\text{Pr} ({S_{t + 1}}|{S_t},{A_t},{S_{t - 1}},{A_{t - 1}}, \cdots ) = \text{Pr}({S_{t + 1}}|{S_t},{A_t})\quad (2.1)
Pr(St+1∣St,At,St−1,At−1,⋯)=Pr(St+1∣St,At)(2.1)
马尔可夫性的核心特点是当前状态具有足够的信息来做出最优决策,在这之前的信息都不是必要的。更一般地,如果下一个状态只与其之前
k
(
k
≥
1
)
k(k\ge 1)
k(k≥1)个状态有关,称
k
k
k 阶马尔可夫过程。
1.5 奖励和奖励函数
智能体在前状态 S t S_t St下,执行动作 A t A_t At后,环境转移至下一个状态 S t + 1 S_{t+1} St+1,获得的奖励用 R t + 1 R_{t+1} Rt+1表示。奖励由奖励函数 R ( S t , A t , S t + 1 ) : S × A × S → R \mathcal{R}({S_t},{A_t},{S_{t + 1}}):{\mathcal S} \times {\mathcal A} \times {\mathcal S} \to \mathbb{R} R(St,At,St+1):S×A×S→R产生。在 t t t时刻,智能体获得的奖励 R t R_t Rt是一个随机变量,取值用 r t r_t rt表示。奖励值是一个标量,即 r t ∈ R r_t\in\mathbb{R} rt∈R且有界。在一些文献中,奖励函数也可能定义为基于状态的奖励,或者基于动作的奖励,即只要环境到达某个状态或者智能体做出某个动作,奖励就会出现。在大多数情况下,这几种不同的定义对强化学习的研究没有影响。
奖励函数在一个强化学习问题中起着关键作用,它间接指明了智能体学习的目标。例如在围棋中,所有赢棋的盘面都会获得正的奖励,而输掉一盘棋则会获得负的奖励。智能体的目标是最大化奖励,因此就要想方设法去赢棋。
策略函数产生的动作与上一个状态一起使得环境按转移到下一个状态,如图3所示。
图3 环境状态转移图

1.6 智能体的策略
智能体的策略(函数)是一个从状态到动作的映射,用 π ( ⋅ ) \pi(\cdot) π(⋅)表示。智能体观测到状态 s s s,通过策略函数计算出动作: a = π ( s ) a=\pi(s) a=π(s)。如果智能体的策略具有随机性则称为随机策略,即 π ( s , a ) = π ( a ∣ s ) = Pr ( A t = a ∣ S t = s ) \pi (s,a)=\pi(a|s) = \Pr ({A_t} = a|{S_t} = s) π(s,a)=π(a∣s)=Pr(At=a∣St=s)随机策略针对每一个状态 s ∈ S s\in\mathcal{S} s∈S都定义了一个动作集 A \mathcal{A} A上的分布。智能体按照强化学习算法对经验数据进行学习,不断调整策略函数,策略的好坏直接决定了智能体执行任务的能力。
1.7 智能体的目标
智能体的任务是学习一种最优策略来最大化累积奖励和的期望。这里的累计奖励需要根据任务的不同形式分开讨论。如果任务在有限时间步后必然结束,则该任务称为分幕(episodic)任务,否则称为持续任务。对于交互轨迹
τ
:
S
0
,
A
0
,
R
1
,
S
1
,
A
1
,
R
2
,
⋯
\tau:{S_0},{A_0},{R_1},{S_1},{A_1},{R_2}, \cdots
τ:S0,A0,R1,S1,A1,R2,⋯,将智能体在 时刻之后能够获得的累积奖励称为回报,定义为
G
t
=
R
t
+
1
+
R
t
+
2
+
R
t
+
3
+
⋯
(
2.2
)
{G_t} = {R_{t + 1}} + {R_{t + 2}} + {R_{t + 3}} + \cdots\quad (2.2)
Gt=Rt+1+Rt+2+Rt+3+⋯(2.2)
对于分幕任务,假设任务在 时刻终止,则回报为
G
t
=
R
t
+
1
+
R
t
+
2
+
R
t
+
3
+
⋯
+
R
T
(
2.3
)
{G_t} = {R_{t + 1}} + {R_{t + 2}} + {R_{t + 3}} + \cdots + {R_T}\quad (2.3)
Gt=Rt+1+Rt+2+Rt+3+⋯+RT(2.3)
对于持续任务,需要引入折扣因子
γ
(
0
≤
γ
≤
1
)
\gamma (0 \le \gamma \le 1)
γ(0≤γ≤1)。折扣因子在计算回报的时候会根据未来的奖励与当前的时间的距离进行折扣,越是遥远的奖励,折扣越多。加入折扣因子后的回报为
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
⋯
=
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
(
2.4
)
{G_t} = {R_{t + 1}} + \gamma {R_{t + 2}} + {\gamma ^2}{R_{t + 3}} + \cdots = \sum\limits_{k = 0}^\infty {{\gamma ^k}} {R_{t + k + 1}}\quad (2.4)
Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1(2.4)
由式(2.4)可知,当
γ
=
0
\gamma = 0
γ=0,智能体只关心当前奖励,将会变得目光短浅;当
γ
=
1
\gamma = 1
γ=1,智能体可以会考虑未来的奖励,但是收敛性无法保证。因此,折扣因子一般设置为接近1。
假设奖励有界,则由于折扣因子 的存在,回报也将是有界的。不妨将奖励设为1,则回报为
G
t
=
∑
k
=
0
∞
γ
k
=
1
1
−
γ
(
2.5
)
{G_t} = \sum\limits_{k = 0}^\infty {{\gamma ^k}} = \frac{1}{{1 - \gamma }}\quad (2.5)
Gt=k=0∑∞γk=1−γ1(2.5)
如果允许分幕任务中的
T
T
T取
∞
\infty
∞,则分幕任务和持续任务可以统一表示为
G
t
=
∑
k
=
0
T
γ
k
R
t
+
k
+
1
(
2.6
)
{G_t} = \sum\limits_{k = 0}^T {{\gamma ^k}} {R_{t + k + 1}}\quad (2.6)
Gt=k=0∑TγkRt+k+1(2.6)
在分幕任务中也可以使用折扣因子。
智能体的目标是找到一种策略
π
\pi
π来最大化累计奖励和的期望,即
arg
max
π
[
G
t
∣
S
t
=
s
]
=
arg
max
π
E
τ
∼
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
(
2.7
)
\mathop {\arg \max }\limits_\pi[{G_t}|{S_t} = s] = \mathop {\arg \max }\limits_\pi\mathbb{E}{_{\tau\sim\pi} }\left[ {\sum\limits_{k = 0}^\infty {{\gamma ^k}} {R_{t + k + 1}}|{S_t} = s} \right]\quad(2.7)
πargmax[Gt∣St=s]=πargmaxEτ∼π[k=0∑∞γkRt+k+1∣St=s](2.7)
上式中求期望的下标
τ
∼
π
\tau\sim\pi
τ∼π表示轨迹
τ
\tau
τ是使用策略
π
\pi
π与环境交互生成的。
1.8 小结
这篇博客介绍了如何使用马尔可夫决策过程对强化学习进行形式化描述,并给出了智能体与环境交互过程中的重要概念:状态、动作、状态转移函数、奖励、折扣因子、目标函数。以上概念是整个强化学习的基石,如果要动手开发强化学习智能体或者进行强化学习理论研究,以上概念需要十分熟悉。
此外,强化学习研究者众多,细分领域繁杂,这里介绍几个启发性的问题。
- 仅仅依靠一个标量形式的奖励,一定能够学会有效的策略完成任务吗?
强化学习之父Sutton老爷子针对这个问题和网友进行了一些讨论,我把讨论文稿翻译后放在这里。对这个问题,强化学习领域的另一位大牛David Silver和Sutton一起在2021年在《Artificial Intelligence》上发表了一篇文章《Reward is Enough》,认为奖励足够驱动智能体表现出自然和人工智能所追求的能力和行为,包括知识、学习、感知、社会智能、语言、泛化、模仿等。但是也有很多人不同意,多目标强化学习一直都有人在研究,这研究中的奖励是一个向量,对应多个不同的目标函数。- 部分观测问题
到目前为止,认为环境的状态是可以完全而准确获得的。但是实际上并不是,更常见的情况是智能体智能观测到环境状态的一部分,此时马尔科夫性就不一定满足。部分观测马尔可夫决策(Partial observable Markov decision process, POMDP)一直都有人在研究。- 探索与利用问题
学而不思则罔,思而不学则殆。古代先贤诚不我欺。很多时候我们会根据自身的经验行事,在自己的认知范围内做出最有利于自己的决策,称之为利用(exploitation)。但是有时候我们也会想闯一闯,做一点不一样的事,世界那么大,大家都想去看看,做一些探索性(不一定符合经验中的最佳利益)的决定,称之为探索(exploration)。人类都解决不好这一对矛盾,因此探索与利用长期以来以及将来都会是强化学习研究的主题。
强化学习中由许多有趣而富有哲理的理论问题。但是本系列博客主要还是想由浅入深,从简单的概念开始,并通过动手实践,获得更加深刻的理解,为进行前沿研究打基础。费曼说,凡是我不能创造的,我就还不理解。后续将更多的围绕强化学习实例展开。


















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











